Jmeter-基础篇
常用压力测试工具对比
1、loadrunner
性能稳定,压测结果及细粒度大,可以自定义脚本进行压测,但是太过于重大,功能比较繁多
2、apache ab(单接口压测最方便)
模拟多线程并发请求,ab命令对发出负载的计算机要求很低,既不会占用很多CPU,也不会占用太多的内存,但却会给目标服务器造成巨大的负载, 简单DDOS攻击等
3、webbench
webbench首先fork出多个子进程,每个子进程都循环做web访问测试。子进程把访问的结果通过pipe告诉父进程,父进程做最终的统计结果。
Jmeter基本介绍和使用场景
简介
1、压测不同的协议和应用
1) Web - HTTP, HTTPS (Java, NodeJS, PHP, ASP.NET, …)
2) SOAP / REST Webservices
3) FTP
4) Database via JDBC
5) LDAP 轻量目录访问协议
6) Message-oriented middleware (MOM) via JMS
7) Mail - SMTP(S), POP3(S) and IMAP(S)
8) TCP等等
2、使用场景及优点
1)功能测试
2)压力测试
3)分布式压力测试
4)纯java开发
5)上手容易,高性能
4)提供测试数据分析
5)各种报表数据图形展示
本地快速安装Jmeter4.x
apache jmeter是100%的java桌面应用程序,它被设计用来加载被测试软件功能特性、度量被测试软件的性能。设计jmeter的初衷是测试web应用,后来又扩充了其它的功能。jmeter可以完成针对静态资源和动态资源(servlets, perl脚本, java对象, 数据查询s, ftp服务等)的性能测试。 jmeter可以模拟大量的服务器负载、网络负载、软件对象负载,通过不同的加载类型全面测试软件的性能。并且jmeter提供图形化的性能分析。
1、需要安装JDK8。或者JDK9,JDK10
2、快速下载
windows: http://mirrors.tuna.tsinghua.edu.cn/apache//jmeter/binaries/apache-jmeter-4.0.zip
mac或者linux:http://mirrors.tuna.tsinghua.edu.cn/apache//jmeter/binaries/apache-jmeter-4.0.tgz
3、文档地址:http://jmeter.apache.org/usermanual/get-started.html
4、建议安装JDK环境,虽然JRE也可以,但是压测https需要JDK里面的 keytool工具
Jmeter目录文件讲解
1、目录
bin:核心可执行文件,包含配置
jmeter.bat: windows启动文件:
jmeter: mac或者linux启动文件:
jmeter-server:mac或者Liunx分布式压测使用的启动文件
jmeter-server.bat:mac或者Liunx分布式压测使用的启动文件
jmeter.properties: 核心配置文件
extras:插件拓展的包
lib:核心的依赖包
ext:核心包
junit:单元测试包
Jmeter语言版本中英文切换
简介:
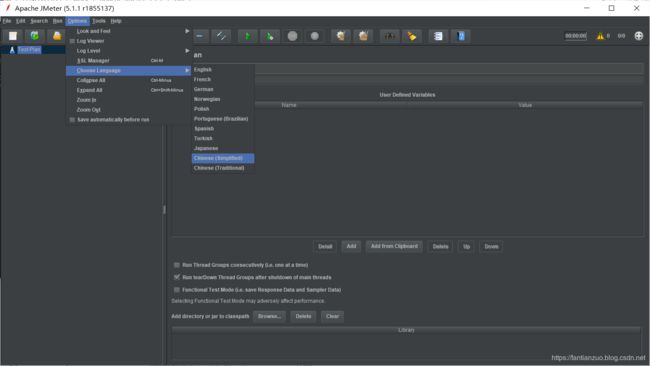
讲解怎么改变jmeter的GUI界面语言版本
1、控制台修改
menu -> options -> choose language
2、配置文件修改
bin目录 -> jmeter.properties
默认 #language=en
改为 language=zh_CN
使用SpringBoot 2.0快速编写API测试接口
我们在这里面编写具体方法:
@Controller
@RequestMapping("/alpha")
public class AlphaController{...具体方法...}
1、模拟GET请求
//get
// /students?current=1&limit=20
@RequestMapping(path="/students",method= RequestMethod.GET)
@ResponseBody
public String getStudents(
@RequestParam(name="current",required = false,defaultValue = "1") int current,
@RequestParam(name="limit",required = false,defaultValue = "10") int limit){
System.out.println(current);
System.out.println(limit);
return "some students";
}
2、模拟POST请求
//post
@RequestMapping(path = "/student",method = RequestMethod.POST)
@ResponseBody
public String saveStudent(String name,int age){
System.out.println(name);
System.out.println(age);
return "success";
}我们的访问路径就是localhost:8080/alpha/...
当然,为了大家测试方便,我已经部署到服务器上,地址是:
http://139.9.83.25/alpha/方法的path![]()
![]()
我把整个alpha的接口都放来,你们可以照着写或者按照路径直接访问服务器上的进行测试。
package com.now.community.community.controller;
/*
*
* http
* get请求
* post请求
* 响应ModelAndView
* 响应(简单)
* json
*
* */
import ch.qos.logback.core.net.SyslogOutputStream;
import com.now.community.community.service.AlphaService;
import com.now.community.community.util.CommunityUtil;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.servlet.ModelAndView;
import javax.servlet.http.*;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.*;
@Controller
@RequestMapping("/alpha")
public class AlphaController {
@Autowired
private AlphaService AlphaService;
@RequestMapping("/hello")
@ResponseBody
public String sayHello(){return "sfadsfafafadf";}
@RequestMapping("/data")
@ResponseBody
public String getData(){return AlphaService.find();}
@RequestMapping("/http")
public void http(HttpServletRequest request, HttpServletResponse response){
System.out.println(request.getMethod());
System.out.println(request.getServletPath());
Enumeration enumeration=request.getHeaderNames();
while(enumeration.hasMoreElements()){
String name=enumeration.nextElement();
String value=request.getHeader(name);
System.out.println(name+":"+value);
}
System.out.println(request.getParameter("code"));
response.setContentType("text/html;charset=utf-8");
try(PrintWriter writer = response.getWriter())
{
writer.write("橙白站
");
} catch (IOException e) {
e.printStackTrace();
}
}
//get
// /students?current=1&limit=20
@RequestMapping(path="/students",method= RequestMethod.GET)
@ResponseBody
public String getStudents(
@RequestParam(name="current",required = false,defaultValue = "1") int current,
@RequestParam(name="limit",required = false,defaultValue = "10") int limit){
System.out.println(current);
System.out.println(limit);
return "some students";
}
// /student/123
@RequestMapping(path="/student/{id}",method= RequestMethod.GET)
@ResponseBody
public String getStudent(@PathVariable("id") int id){
System.out.println(id);
return "a student";
}
//post
@RequestMapping(path = "/student",method = RequestMethod.POST)
@ResponseBody
public String saveStudent(String name,int age){
System.out.println(name);
System.out.println(age);
return "success";
}
//响应html数据
@RequestMapping(path = "/teacher",method = RequestMethod.GET)
public ModelAndView getTeacher(){
ModelAndView mav=new ModelAndView();
mav.addObject("name","张三");
mav.addObject("age",30);
mav.setViewName("/demo/view");
return mav;
}
//返回模板的地址
@RequestMapping(path = "/school",method = RequestMethod.GET)
public String getSchool(Model model){
model.addAttribute("name","北大");
model.addAttribute("age","100");
return "/demo/view";
}
//响应json数据(异步请求中)
//java对象->json字符串-> js对象
@RequestMapping(path = "/emp",method = RequestMethod.GET)
@ResponseBody
public Map getEmp(){
Map emp=new HashMap<>();
emp.put("name","张三");
emp.put("age",23);
emp.put("salary",8000.00);
return emp;
}
@RequestMapping(path = "/emps",method = RequestMethod.GET)
@ResponseBody
public List> getEmps(){
List> list=new ArrayList<>();
Map
emp=new HashMap<>();
emp.put("name","张三");
emp.put("age",23);
emp.put("salary",8000.00);
list.add(emp);
emp=new HashMap<>();
emp.put("name","李四");
emp.put("age",24);
emp.put("salary",9000.00);
list.add(emp);
return list;
}
@RequestMapping(path = "/cookie/set",method = RequestMethod.GET)
@ResponseBody
public String setCookie(HttpServletResponse httpServletResponse){
Cookie cookie=new Cookie("code", CommunityUtil.generateUUID());
cookie.setPath("/community/alpha");
cookie.setMaxAge(60*10);
httpServletResponse.addCookie(cookie);
return "set cookie";
}
@RequestMapping(path = "/cookie/get",method = RequestMethod.GET)
@ResponseBody
public String getCookie(@CookieValue("code") String code){
System.out.println(code);
return "get cookie";
}
@RequestMapping(path = "/session/set", method = RequestMethod.GET)
@ResponseBody
public String setSession(HttpSession session){
session.setAttribute("id",1);
session.setAttribute("name","Test");
return "set session";
}
@RequestMapping(path = "/session/get", method = RequestMethod.GET)
@ResponseBody
public String getSession(HttpSession session) {
System.out.println(session.getAttribute("id"));
System.out.println(session.getAttribute("name"));
return "get session";
}
@RequestMapping(path = "/ajax",method = RequestMethod.POST)
@ResponseBody
public String testAjax(String name,int age){
System.out.println(name);
System.out.println(age);
return CommunityUtil.getJSONString(0,"操作成功");
}
}
创建Jmeter测试计划,快速压测一个接口
我们首先创建一个测试计划

设置测试计划

我们可以创建一个http请求
设置参数
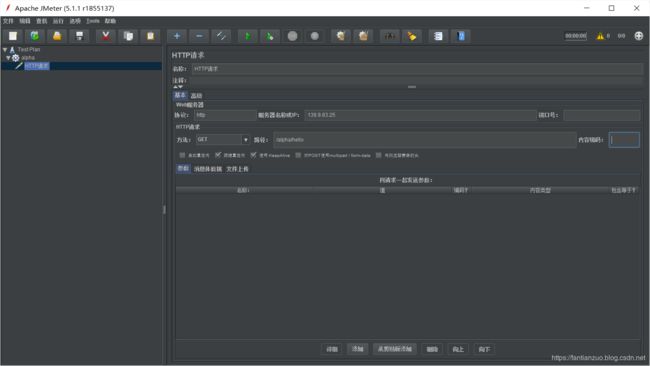
解释一下:
协议要写
服务器名称或者ip要写,你可以访问我的服务器139.9.83.25,也可以访问本地localhost前提是你自己启动了项目。
端口号本地tomcat默认8080,如果访问我的服务器不用写,我设置了。
方法:测什么类型就选什么类型。
路径:具体接口的路径
其他的以后再解释。
好,我们run就算测完了,但是看不到结果,所以继续操作
添加结果树

查看结果树


这是我上面的接口里写的
Jmeter基础功能组件介绍线程组和Sampler
1、添加->threads->线程组(控制总体并发)

线程数:虚拟用户数。一个虚拟用户占用一个进程或线程
准备时长(Ramp-Up Period(in seconds)):全部线程启动的时长,比如100个线程,20秒,则表示20秒内100个线程都要启动完成,每秒启动5个线程
循环次数:每个线程发送的次数,假如值为5,100个线程,则会发送500次请求,可以勾选永远循环
调度器:循环次数永远之后,可以配置多长时间结束;也可以配置启动延迟
2、线程组->添加-> Sampler(采样器) -> Http (一个线程组下面可以增加几个Sampler)
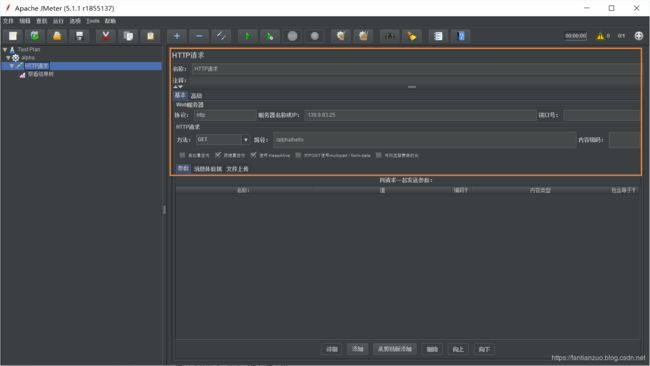
名称:采样器名称
注释:对这个采样器的描述
web服务器:
默认协议是http
默认端口是80
服务器名称或IP :请求的目标服务器名称或IP地址
路径:服务器URL
Use multipart/from-data for HTTP POST :当发送POST请求时,使用Use multipart/from-data方法发送,默认不选中。
3、查看测试结果
线程组->添加->监听器->察看结果树
Jmeter的断言基本使用
1、增加断言: 线程组 -> 添加 -> 断言 -> 响应断言

apply to(应用范围):
Main sample only: 仅当前父取样器 进行断言,一般一个请求,如果发一个请求会触发多个,则就有sub sample(比较少用)
要测试的响应字段:
响应文本:即响应的数据,比如json等文本
响应代码:http的响应状态码,比如200,302,404这些
响应信息:http响应代码对应的响应信息,例如:OK, Found
Response Header: 响应头
模式匹配规则:
包括:包含在里面就成功
匹配:响应内容完全匹配,不区分大小写
equals:完全匹配,区分大小写
举个例子:
测这个地址:http://139.9.83.25/alpha/emps大家可以先去看一下结果
我们设置一下断言

run后去看结果树,肯定是成功的。
但是你改成“相等”,肯定是失败的

2、断言结果监听器: 线程组-> 添加 -> 监听器 -> 断言结果
里面的内容是sampler采样器的名称
断言失败,查看结果树任务结果颜色标红(通过结果数里面双击不通过的记录,可以看到错误信息)
点开这个请求可以查看断言详情
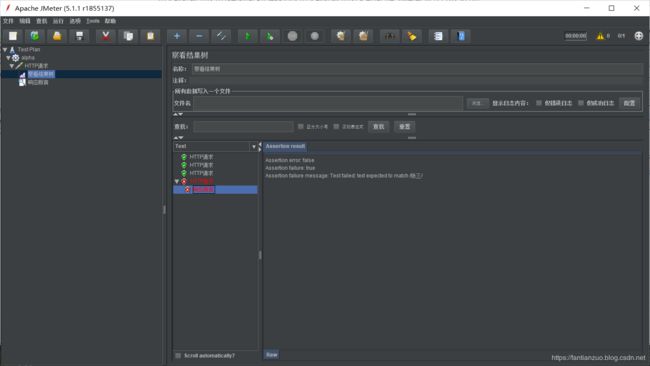
3、每个sample下面可以加单独的结果树,然后同时加多个断言,最外层可以加个结果树进行汇总
压测结果聚合报告分析
新增聚合报告:线程组->添加->监听器->聚合报告(Aggregate Report)
lable: sampler的名称
Samples: 一共发出去多少请求,例如10个用户,循环10次,则是 100
Average: 平均响应时间
Median: 中位数,也就是 50% 用户的响应时间
90% Line : 90% 用户的响应不会超过该时间 (90% of the samples took no more than this time. The remaining samples at least as long as this)
95% Line : 95% 用户的响应不会超过该时间
99% Line : 99% 用户的响应不会超过该时间
min : 最小响应时间
max : 最大响应时间
Error%:错误的请求的数量/请求的总数
Throughput: 吞吐量——默认情况下表示每秒完成的请求数(Request per Second) 可类比为qps
KB/Sec: 每秒接收数据量
实战:你可以把路径换成/,我设置了弄到主页,主页是这个样子:

这时,有些参数就可以设置了:
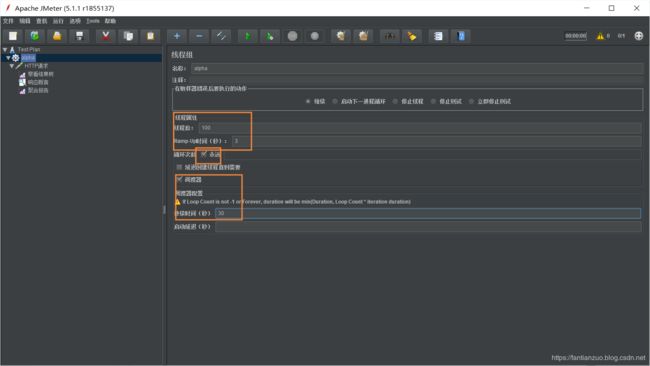
线程数请不要超过100,要不然就把我的小服务器搞炸了。。。
然后run之后可以查看结果了:

你可以多测几次,因为可能恰巧系统在垃圾回收,或者在清缓存等等,多测几次比较准。
Jmeter用户自定义变量实战
为什么使用:很多变量在全局中都有使用,或者测试数据更改,可以在一处定义,四处使用
比如服务器地址
1、线程组->add -> Config Element(配置原件)-> User Definde Variable(用户定义的变量)

2、引用方式${XXX},在接口中变量中使用

建议:每个线程组定义自己的。测试计划定义总的参数,比如网址。
3、原始查看结果树和非原生查看(基础按钮)
实战之CSV可变参数压测
实战操作jmeter读取CSV和Txt文本文件里面的参数进行压测
1、线程组->add -> Config Element(配置原件)-> CSV data set config (CSV数据文件设置)
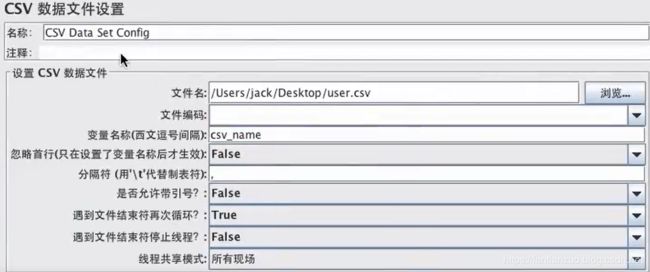
参数太容易理解,不解释了。
我们可以读取文件的数据进行压测,比如:
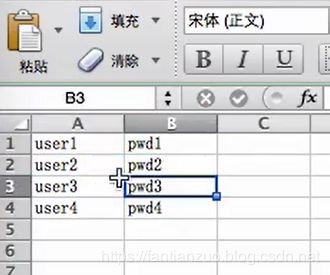
一行一个请求,很容易理解吧。

你会发现user是变化的。
介绍多参数分隔符:

你可以设置分隔符:

然后就可以使用了:

唉。。。截图截到现在。。实在是不i想截了,数据库我就不截图了。。。只有步骤和参数解释
JDBC request压测Mysql
讲解jdbc压测mysql相关准备工作,jar包添加,配置讲解
1、Thread Group -> add -> sampler -> jdbc request
2、jar包添加 mysql-connector-java-5.1.30.jar
3、JDBC connection Configuration 配置
1、JDBC request->add -> config element -> JDBC connection configuration
核心配置
Max Number of connections : 最大连接数
MAX wait :最大等待时间
Auto Commit: 是否自动提交事务
DataBase URL : 数据库连接地址 jdbc:mysql://127.0.0.1:3306/blog
JDBC Driver Class : 数据库驱动,选择对应的mysql
username:数据库用户名
password:数据库密码
JDBC request压测Mysql, select
使用jmeter压测mysql,select,insert语句
1、Debug Sampler使用(结果树中查看)
Thread Group -> add -> sampler -> debug sampler
2、参数讲解:(sql结尾不要加";")
1、variable name of pool declared in JDBC connection configuration(和配置文件同名)
2、Query Type 查询类型
3、parameter values 参数值
4、parameter types 参数类型
5、variable names sql执行结果变量名
6、result variable names 所有结果当做一个对象存储
7、query timeouts 查询超时时间
8、 handle results 处理结果集
定时器
定时器帮助我们模拟更真实的场景

随机多长时间,这也比较符合我们真实的场景,肯定是有不确定间隔的请求过来。
其他的定时器做到见文知意。
执行顺序
如果在同一个作用域范围内有多个同一类型的元件,则这些元件按照它们在测试计划中的上下顺序依次执行
作用域
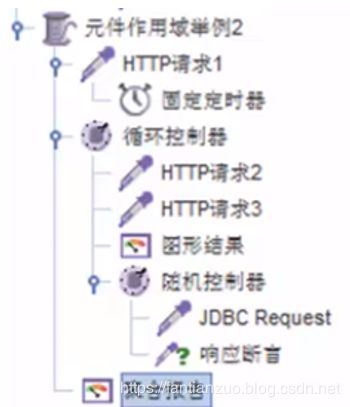
•固定定时器:http1
•循环控制器:http2、http3、图形结果、随机控制器
•图形结果:http2、http3
•响应断言:jdbc
•聚合报告:所有
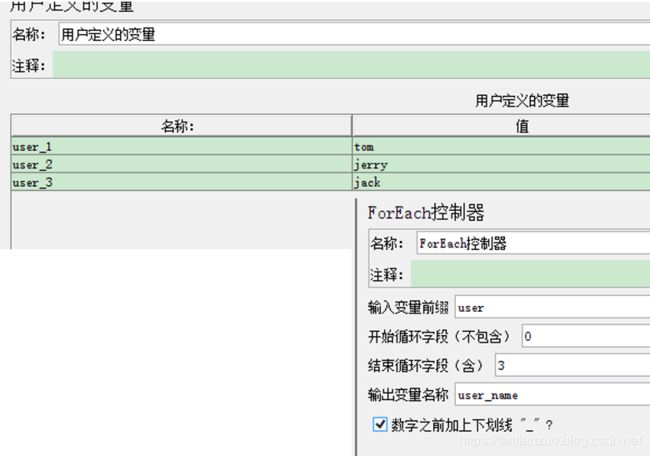
for-each控制器
目的:遍历变量值
一般和用户自定义变量(User Defined Variables)一起使用,其在用户自定义变量中读取一系列相关的变量。每一个线程下执行时该控制器下的采样器或控制器都会被执行一次或多次(次数和用户变量有关)。输入应包括的几个变量,每个变量由变量名、下划线、和数字组成,每个变量必须有一个值
switch控制器
该控制器可以控制里面的请求根据某些规则,在不同数字时选择控制器下的对应数字位的不同sampler。一般可以用在模拟多线程同时操作不同请求的测试场景。
Switch Value:设置你要访问的请求索引(从0开始的)或者直接设置访问的请求名称。数字对应的就是每个请求的顺序(注意点:第一个是0),这个num可以通过计数器,counter函数,random函数来自动生成(一般常用random函数)。
if控制器
目的:判断条件,可以引用变量。当为 true 时,执行相应的操作
Interpret Condition as Variable Expression?
如果选择了此项,则条件必须是一个表达式,该表达式计算为“true”。
Evaluate for all children
注意事项:在if逻辑控制器的Expression中不能直接填写条件表达式,需要借助函数将条件表达式计算为true/false,可以借助的函数有__jexl3和__groovy函数
如果是字符串的比较,需要加””
"${url}"=="baidu"
表达式支持:
循环控制器
目的:循环该控制器下面字节点的次数。
线程组里循环次数设置了n次,循环控制器下的循环次数也设置了m次,则该控制器下的请求运行的次数是(n*m)次。
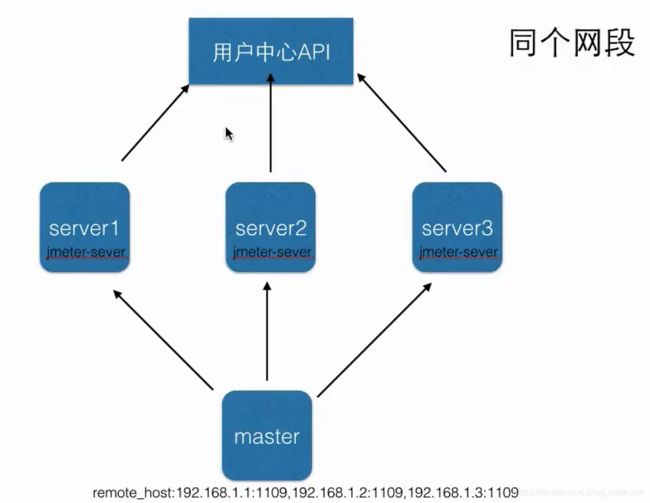
分布式压测介绍
普通压测:单台机可以对目标机器产生的压力比较小,受限因素包括CPU,网络,IO等
分布式压测:利用多台机器向目标机器产生压力,模拟几万用户并发访问
分布式压测原理
1、总控机器的节点master,其他产生压力的机器叫“肉鸡” server
2、master会把压测脚本发送到 server上面
3、执行的时候,server上只需要把jmeter-server打开就可以了,不用启动jmeter
4、结束后,server会把压测数据回传给master,然后master汇总输出报告
5、配置详情
实战下次再更