机器学习(十一)谱聚类算法
谱聚类算法
原文地址:http://blog.csdn.net/hjimce/article/details/45749757
作者:hjimce
一、算法概述
谱聚类算法建立在谱图理论基础上,与传统的聚类算法相比,它具有能在任意形状的样本空间上聚类且收敛于全局最优解的优点。 谱聚类的求解方法有很多种,其中比较简单常用的是Nomarlized cut。其算法流程如下:
1、采用knn搜索最近k邻样本,然后构造样本相似度稀疏矩阵W(N,N)(如果不采用knn,那么构造的是全连接图,不是稀疏矩阵,如果样本多的话,求解起来速度就会很慢了),两样本之间的相似度度量可采用如下公式:
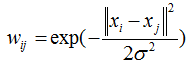
这边先定义W的对角线元素为0(Wii=0),然后归一化这个W矩阵的每一行和为1。
2、对W矩阵做归一化处理后,构造归一化的拉普拉斯矩阵L(归一化的拉普拉斯矩阵的对角线元素为1,每一行所有元素和为0),即:
L=I-W
3、求解L矩阵的前k个最小特征值对应的特征向量(k为聚类的个数),然后把这K个特征向量竖着并排在一起,形成一个新的特征向量空间数据E(N,K)的矩阵。这样E每一行对应于原始数据的每一个样本,然后我们对这N行数据做k-means聚类(也可以用其它的聚类方法),得到的聚类结果就是谱聚类的结果。
二、源码实践
#coding=utf-8
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import random
#生成两个高斯分布训练样本用于测试
#第一类样本类
mean1 = [0, 0]
cov1 = [[1, 0], [0, 1]] # 协方差矩阵
x1, y1= np.random.multivariate_normal(mean1, cov1, 100).T
data=[]
for x,y in zip(x1,y1):
data.append([x,y])
#第二类样本类
mean2 = [3,3]
cov2 = [[1, 0], [0, 1]] # 协方差矩阵
x2, y2= np.random.multivariate_normal(mean2, cov2, 100).T
for x,y in zip(x2,y2):
data.append([x,y])
random.shuffle(data)#打乱数据
data=np.asarray(data,dtype=np.float32)
#算法开始
#计算两两样本之间的权重矩阵,在真正使用场景中,样本很多,可以只计算邻接顶点的权重矩阵
m,n=data.shape
distance=np.zeros((m,m),dtype=np.float32)
for i in range(m):
for j in range(m):
if i==j:
continue
dis=sum((data[i]-data[j])**2)
distance[i,j]=dis
#构建归一化拉普拉斯矩阵
similarity = np.exp(-1.* distance/distance.std())
for i in range(m):
similarity[i,i]=0
for i in range(m):
similarity[i]=-similarity[i]/sum(similarity[i])#归一化操作
similarity[i,i]=1#拉普拉斯矩阵的每一行和为0,对角线元素之为1
#计算拉普拉斯矩阵的前k个最小特征值
[Q,V]=np.linalg.eig(similarity)
idx = Q.argsort()
Q = Q[idx]
V = V[:,idx]
#前3个最小特征值
num_clusters =3
newd=V[:,:3]
#k均值聚类
clf = KMeans(n_clusters=num_clusters)
clf.fit(newd)
#显示结果
for i in range(data.shape[0]):
if clf.labels_[i]==0:
plt.plot(data[i,0], data[i,1], 'go')
elif clf.labels_[i]==1:
plt.plot(data[i,0], data[i,1], 'ro')
elif clf.labels_[i]==2:
plt.plot(data[i,0], data[i,1], 'yo')
elif clf.labels_[i]==3:
plt.plot(data[i,0], data[i,1], 'bo')
plt.show()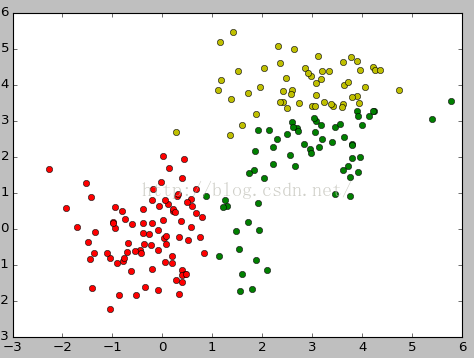
参考文献:
1、http://liuzhiqiangruc.iteye.com/blog/2117144