全连接前向神经网络与手写数字的实践
文章首发于 个人博客
文章目录
- 引言
- 全连接前向神经网络
- 实例
引言
上一篇文章提到了 logistics regression 、多分类的 softmax 算法及梯度等概念,其实就可以很自然的引出深度学习了。
引用WiKi的定义:
深度学习(deep learning)是机器学习的分支,是一种试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的算法。
早在1958年就提出了 perceptron 的模型,即最简单的线性感知机模型,在当时引起了很大的轰动,甚至提出了机器可以取代人的说法,然而后来就被人质疑,现在看来线性感知机的限制显而易见。
然后在20世纪80年代,根据之前 perceptron 提出了 multi-layer perceptron(又叫 Neural Network), 这个模型和当今的深度神经网络是没有显著区别的。1986年提出了反向传播的概念,但是通常大于三层的 hidden layer 就没有效果了,神经网络学习出现了梯度消失的问题。
后来在 2006年,在上述神经网络的算法模型上,取得了一些改进(RBM initialization),将之前 multi-layer perceptron 改了个名字 —— Deep Learning 重新提了出来,2009年的时候 DL 的运算开始利用 GPU,后面其在各个领域取得了一些突破性的应用进展,就火起来了。
所以,深度学习并不是什么新鲜事物,只是换了个名字的稍微改进的旧模型。
全连接前向神经网络
一个全连接的前向神经网络示例如下所示,其激活函数是之前提到的 sigmod 函数,经过这个全连接的神经网络,其 weight 和 bias 都知道的情况下,输入的向量就会不断的变化,最后输出一个向量。
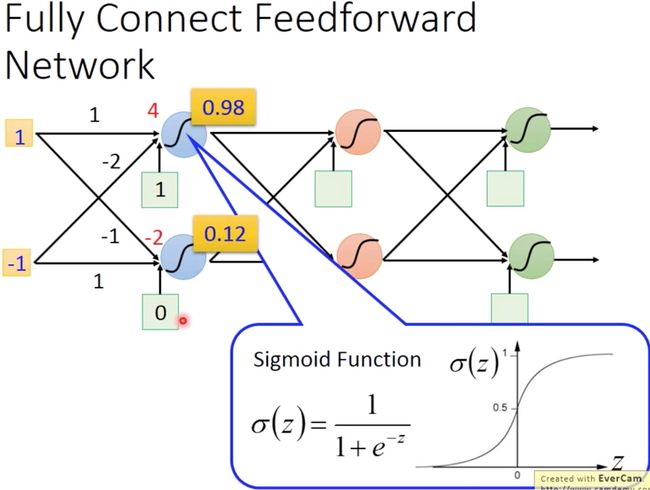
一般来说,Fully Connect Feedforward Network 的架构如下图所示,前一层每个输入都连接到下一层的所有神经元中:
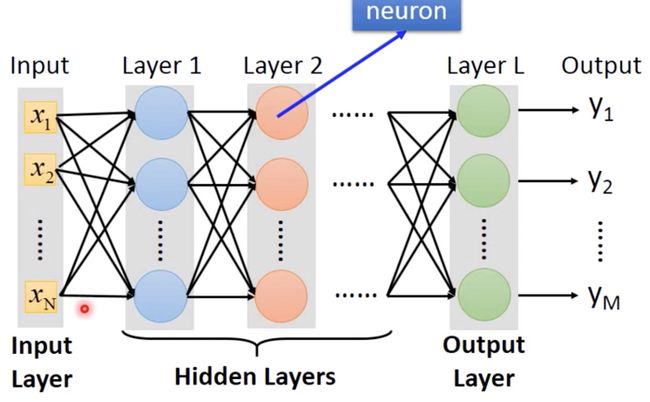
其输入层和输出层都是一个 vector,但是其 dimension 不一定相同,其中的 hidden layer 一般有多层,这也是 Deep Learning 的 Deep 所在。
而神经网络的运算实质是矩阵运算,这也是为什么 GPU 能加速神经网络的原因所在。

实例
以之前一直在用的手写数字识别为例,分别使用 keras 和 pytorch 搭建两个 fully connect feedforward network 模型,使用 Mnist 数据集进行训练。
首先是 keras (Using TensorFlow backend.)的代码如下:
#!/usr/local/bin/python3.6
import numpy as np
import os
import matplotlib.pyplot as plt
import keras
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.utils import np_utils
from keras import backend as K
# 多核 CPU 使用设置
K.set_session(K.tf.Session(config=K.tf.ConfigProto(device_count={"CPU": 8},
inter_op_parallelism_threads=8,
intra_op_parallelism_threads=8,
log_device_placement=True)))
# tensorboard 可视化
tbCallBack = keras.callbacks.TensorBoard(log_dir='./Graph',
histogram_freq=1,
write_graph=True,
write_images=True)
# 加载数据集
def load_data(file_path):
f = np.load(file_path)
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test']
f.close()
return (x_train, y_train), (x_test, y_test)
# 初始化数据
(X_train, y_train), (X_test, y_test) = load_data('./mnist.npz')
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
nb_classes = 10
# 将 label 数据转化为 one-hot,因为模型训练 loss 参数为 categorical_crossentropy
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
# 初始化一个 model
model = Sequential()
# 添加第一层,输入是784维,第一层节点为 500,激活函数为 relu
model.add(Dense(500, input_shape=(784,)))
model.add(Activation('relu'))
# model.add(Dropout(0.2))
# 添加第二层,节点为 500,激活函数为 relu
model.add(Dense(500))
model.add(Activation('relu'))
# model.add(Dropout(0.2))
# 添加输出层,输出 10 维,激活函数为 softmax
model.add(Dense(10))
model.add(Activation('softmax'))
# 配置模型训练参数,loss 使用多类的对数损失函数,optimizer 优化器使用 adam,模型性能评估使用 accuracy
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 开始训练,batch_size为100, 10 个 epoch,callbacks调用 tensorboard
model.fit(X_train, Y_train,
batch_size=100, epochs=10,
validation_data=(X_test, Y_test),
callbacks=[tbCallBack]
)
score = model.evaluate(X_test, Y_test, verbose=0)
print('Test score:', score[0])
print('Test accuracy:', score[1])
这是一个两层的全连接前向神经网络,训练了 10 epochs,准确率如下:

没有 GPU,纯 CPU 跑起来的不算慢,准确率达到 97.7%,其神经网络结构图如下:

pytorch 使用起来就没 keras 那么简单了,其代码如下:
import os
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# 多核 cpu 设置
os.environ["OMP_NUM_THREADS"] = "8"
os.environ["MKL_NUM_THREADS"] = "8"
# 设置使用 CPU
device = torch.device('cpu')
# 参数配置
input_size = 784
hidden_size = 500
num_classes = 10
num_epochs = 10
batch_size = 100
learning_rate = 0.001
# 1 MNIST dataset 加载图像数据
train_dataset = torchvision.datasets.MNIST(root='.',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='.',
train=False,
transform=transforms.ToTensor())
# 2 Data loader pytorch的数据加载方式,tensorflow是没有的
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
# 3 Fully connected neural network with one hidden layer 定义网络
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(NeuralNet, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
model = NeuralNet(input_size, hidden_size, num_classes).to(device)
# 4 Loss and optimizer 定义损失和优化函数
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),
lr=learning_rate)
# 5 Train the model 训练模型
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader): # batch size的大小
# Move tensors to the configured device
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
# Forward pass 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize 后向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
# Test the model 预测
# In test phase, we don't need to compute gradients (for memory efficiency)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: {} %'
.format(100 * correct / total))
# Save the model checkpoint
torch.save(model.state_dict(), 'model.ckpt')
准确率如下:
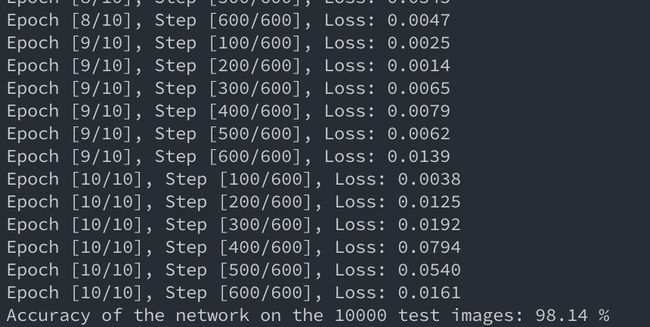
总体时间上,要比 TF 的慢,从源码编译了一遍安装还是慢。。