opencv+dlib 制作平均脸
用OpenCV + dlib 制作“平均脸”
既然知道了原理,我们现在就要开始动手制作了。
再来回顾一下步骤,当我们要将N张人脸照片合称为一张平均脸的时候,我们首先要处理每一张照片:
【1】获取其中的68个脸部特征点,并以这些点为定点,剖分Delaunay 三角形,就如下图这样:
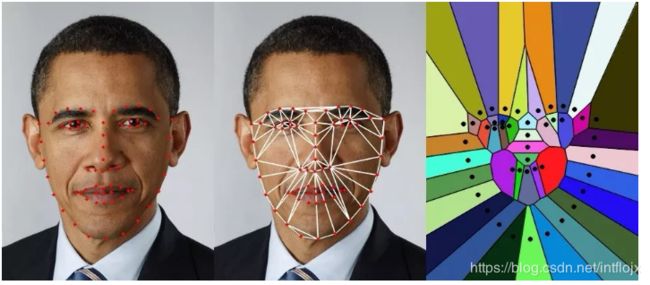
[Code-1] 首先要获得68个脸部特征点,这68个点定义了脸型、眉毛、眼睛、鼻子和嘴的轮廓。幸运的是,这么复杂的操作,我们用OpenCV,几行代码就搞定了!
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(predictor_path)
img = io.imread(image_file_path)
dets = detector(img, 1)
for k, d in enumerate(dets):
shape = predictor(img, d)
points = np.zeros((68, 2), dtype = int)
for i in range(0, 68):
points[i] = (int(shape.part(i).x), int(shape.part(i).y))
[Code-2] 接着剖分Delaunay 三角形,其中points就是68个面部特征点,rect是脸部所在的矩形:
def calculateDelaunayTriangles(rect, points):
subdiv = cv2.Subdiv2D(rect);
for p in points:
subdiv.insert((p[0], p[1]));
triangleList = subdiv.getTriangleList();
delaunayTri = []
for t in triangleList:
pt = []
pt.append((t[0], t[1]))
pt.append((t[2], t[3]))
pt.append((t[4], t[5]))
pt1 = (t[0], t[1])
pt2 = (t[2], t[3])
pt3 = (t[4], t[5])
if rectContains(rect, pt1) and rectContains(rect, pt2) and rectContains(rect, pt3):
ind = []
for j in xrange(0, 3):
for k in xrange(0, len(points)):
if(abs(pt[j][0] - points[k][0]) < 1.0 and abs(pt[j][1] - points[k][1]) < 1.0):
ind.append(k)
if len(ind) == 3:
delaunayTri.append((ind[0], ind[1], ind[2]))
return delaunayTri
【2】然后计算每张脸上各个Delaunay剖分三角的仿射变换,再通过仿射变换扭曲Delaunay三角形:
[Code-3] 计算仿射变换
def applyAffineTransform(src, srcTri, dstTri, size) :
warpMat = cv2.getAffineTransform( np.float32(srcTri), np.float32(dstTri) )
dst = cv2.warpAffine( src, warpMat, (size[0], size[1]), None, flags=cv2.INTER_LINEAR, borderMode=cv2.BORDER_REFLECT_101 )
return dst
[Code-4] 通过仿射变换扭曲Delaunay剖分三角形
def warpTriangle(img1, img2, t1, t2) :
r1 = cv2.boundingRect(np.float32([t1]))
r2 = cv2.boundingRect(np.float32([t2]))
t1Rect = []
t2Rect = []
t2RectInt = []
for i in xrange(0, 3):
t1Rect.append(((t1[i][0] - r1[0]),(t1[i][1] - r1[1])))
t2Rect.append(((t2[i][0] - r2[0]),(t2[i][1] - r2[1])))
t2RectInt.append(((t2[i][0] - r2[0]),(t2[i][1] - r2[1])))
mask = np.zeros((r2[3], r2[2], 3), dtype = np.float32)
cv2.fillConvexPoly(mask, np.int32(t2RectInt), (1.0, 1.0, 1.0), 16, 0);
img1Rect = img1[r1[1]:r1[1] + r1[3], r1[0]:r1[0] + r1[2]]
size = (r2[2], r2[3])
img2Rect = applyAffineTransform(img1Rect, t1Rect, t2Rect, size)
img2Rect = img2Rect * mask
img2[r2[1]:r2[1]+r2[3], r2[0]:r2[0]+r2[2]] = img2[r2[1]:r2[1]+r2[3], r2[0]:r2[0]+r2[2]] * ( (1.0, 1.0, 1.0) - mask )
img2[r2[1]:r2[1]+r2[3], r2[0]:r2[0]+r2[2]] = img2[r2[1]:r2[1]+r2[3], r2[0]:r2[0]+r2[2]] + img2Rect
以上就是制作平均脸几个关键步骤的代码。
完整代码在笔者的GitHub的AverageFace项目:https://github.com/juliali/AverageFace
用大合影构造“平均脸”

原理和代码都非常简单,不过在实际运行当中,我们需要注意:
【NOTE-1】我们用来做平均脸的单个人脸图像的尺寸很可能不一样,为了方便起见,我们将它们全部转为600*600大小。而所用原始图片,最好比这个尺寸大。
【NOTE-2】既然是要做平均脸,最好都是选用正面、端正姿态的人脸,面部表情最好也不要过于夸张。
根据这两点,我们发现:证件照非常合适用来做平均脸。
不过,一般我们很难找到那么多证件照,却比较容易获得另一类照片——合影。
特别是那种相对正规场合的合影,比如毕业照,公司年会、研讨会集体合影之类的。这类照片,大家都朝一个方向看,全部面带克制、正式的微笑,简直就是构造平均脸的理想样本啊!
我们只需要将一张大合影中每个人的头像“切”下来,生成一张单独的人脸照片,然后在按照4中的描述来叠加多张人脸不就好了吗?
可是,如果一张大合影上有几十几百,甚至上千人,难道我们手动去切图吗?
当然不用,别忘了,我们本来就可以检测人脸啊!我们只需要检测到每一张人脸所在的区域,然后再将该区域sub-image独立存储成一张照片就好了!所有过程,完全可以自动化完成!
当然所用原图最好清晰度好一点,不然切出来的照片模糊,得出结果就更模糊了。
用Caffe制作区分性别的“平均脸”
当笔者把自己部门的平均脸给同事看之后,马上有同事问:为什么只平均了男的?
回答:不是只平均了男的,是不分男女一起平均的,不过得出的结果看着像个男的而已。
又问:为什么不把男女分开平均?
是啊,一般人脸能够直接提供的信息包括:性别、年龄、种族。从大合影中提取的脸,一般年龄差距不会太大(考虑大多数合影场合),种族也相对单一,性别却大多是混合的,如果不能区分男女,合成的平均脸意义不大。
如果能自动获得一张脸的性别信息,然后将男女的照片分开,再构造平均脸显然合理的多。
于是,又在网上找了一个性别分类模型,用来给人脸照片划分性别。因为是用现成的模型,所以代码非常简单,不过需要预先安装caffe和cv2:
mean_filename='models\mean.binaryproto'
gender_net_model_file = 'models\deploy_gender.prototxt'
gender_net_pretrained = 'models\gender_net.caffemodel'
gender_net = caffe.Classifier(gender_net_model_file, gender_net_pretrained,
mean=mean,
channel_swap=(2, 1, 0),
raw_scale=255,
image_dims=(256, 256))
gender_list = ['Male', 'Female']
img = io.imread(image_file_path)
dets = detector(img, 1)
for k, d in enumerate(dets):
cropped_face = img[d.top():d.bottom(), d.left():d.right(), :]
h = d.bottom() - d.top()
w = d.right() - d.left()
hF = int(h * 0.1)
wF = int(w*0.1)
cropped_face_big = img[d.top() - hF:d.bottom() + hF, d.left() - wF:d.right() + wF, :]
prediction = gender_net.predict([cropped_face_big])
gender = gender_list[prediction[0].argmax()].lower()
print 'predicted gender:', gender
dirname = dirname + gender + "\\"
copyfile(image_file_path, dirname + filename)
用这个模型先predict一遍每张人脸的性别,将不同性别的照片分别copy到male或者female目录下,然后再分别对这两个目录下的照片求平均,就可以得到男女不同的平均脸了!
这一步的代码、运行都很简单,比较坑的是caffe的安装!
因为笔者用的是Windows机器,只能下载caffe源代码自己编译安装,全过程遵照https://github.com/BVLC/caffe/tree/windows,相当繁琐。
而且由于系统设置的问题,编译后,libraries目录不是生成在caffe源码根目录下,而是位于C:\Users\build.caffe\dependencies\librariesv140x64py271.1.0 —— 这一点未必会发生在你的机器上,但是要注意编译过程中每一步的结果。
训练自己的性别识别模型
想法是很好,但是,这个直接download的gender classification模型性能不太好。有很多照片的性别被分错了!
这种分错看不出什么规律,有些明明很女性化的女生头像被分成了male,很多特征鲜明的男生头像却成了female。
能够看出来的是,gender_net.caffemodel 是一个而分类模型,而且male是它的positive类,所有不被认为是male的,都被分入了female(包括一些根本就不是人脸的照片)。
笔者用自己从大合影中截取的1100+张头像做了一次测试,发现此模型的precision相对高一些——83.7%,recall低得多——54%,F1Score只有0.66。
考虑到这是一个西方人训练的模型,很可能它并不适合亚洲人的脸。笔者决定用自己同事的一千多张照片训练自己的性别分类模型!
我们用caffe训练模型,不需要写代码,只需要准备好训练数据(人脸图片),编写配置文件,并运行命令即可。
命令和配置文件均在笔者github的FaceGenderClassification项目中:https://github.com/juliali/FaceGenderClassification
为了验证新模型效果,笔者创建了几个数据集,最大的一个(下面称为testds-1)包含110+张照片,取自一张从网上搜索到的某大学毕业照中切分出的人脸;另外还有3个size在10-20不等的小数据集。
原始性别分类模型在testds-1上的Precision = 94%, Recall = 12.8% ——完全不可用啊! 新训练的性别分类模型在testds-1上的Precision = 95%, Recall = 56% ——明显高于原始模型。
笔者在一台内存为7G,CPU为Intel Xeon E5-2660 0 @ 2.20GHz 2.19 GHz的机器上训练(无GPU);训练数据为1100+张平均8-9K大小的图片;每1000次迭代需要大概3个小时。
设置为每1000次迭代输出一个模型。最后一共训练了14000轮,输出了14个模型。通过在几个不同的test data set上对比,发现整体性能最好的是第10次输出,也就是10000次迭代的结果。这个迭代的结果也放在github中。
区分性别的平均脸
虽然我们有模型来区分性别,但是如果想要“纯粹”的结果,恐怕还是得在模型分类后在人工检验并手动纠错一遍。毕竟,再好的模型,F1Score也不是1。
经过模型分类再手工分拣后,笔者把自己同事的照片分成了两个set:300+女性和800+男性。然后分别构造了平均脸。
是这个样子的:

对比一下上面那张不分性别的大平均,女生简直就被融化了——女生对大平均的贡献只是让最终的头像皮肤好了点,眼睛大了点,整个性别特征都损失掉了!