数据结构_线性表_链式存储_单链表 的基本操作
单链表的简介
单链表是一种链式存取的数据结构,用一组地址任意的存储单元存放线性表中的数据元素
链表中的数据是以结点来表示的,每个结点的构成:元素(数据元素的映象) + 指针(指示后继元素存储位置),元素就是存储数据的存储单元,指针就是连接每个结点的地址数据。
以“结点的序列”表示线性表称作线性链表(单链表)
单链表是链式存取的结构,为找第 i 个数据元素,必须先找到第 i-1 个数据元素。
因此,查找第 i 个数据元素的基本操作为:移动指针,比较 j 和 i
单链表
1、链接存储方法
链接方式存储的线性表简称为链表(Linked List)。
链表的具体存储表示为:
① 用一组任意的存储单元来存放线性表的结点(这组存储单元既可以是连续的,也可以是不连续的)
② 链表中结点的逻辑次序和物理次序不一定相同。为了能正确表示结点间的逻辑关系,在存储每个结点值的同时,还必须存储指示其后继结点的地址(或位置)信息(称为指针(pointer)或链(link))
注意:
链式存储是最常用的存储方式之一,它不仅可用来表示线性表,而且可用来表示各种非线性的数据结构。
2、链表的结点结构
┌───┬───┐
│data │next │
└───┴───┘
data域–存放结点值的数据域
next域–存放结点的直接后继的地址(位置)的指针域(链域)
注意:
①链表通过每个结点的链域将线性表的n个结点按其逻辑顺序链接在一起的。
②每个结点只有一个链域的链表称为单链表(Single Linked List)。
【例】线性表(bat,cat,eat,fat,hat,jat,lat,mat)的单链表示如示意图
3、头指针head和终端结点指针域的表示
单链表中每个结点的存储地址是存放在其前趋结点next域中,而开始结点无前趋,故应设头指针head指向开始结点。
注意:
链表由头指针唯一确定,单链表可以用头指针的名字来命名。
终端结点无后继,故终端结点的指针域为空,即NULL。
4、单链表的一般图示法
由于我们常常只注重结点间的逻辑顺序,不关心每个结点的实际位置,可以用箭头来表示链域中的指针,线性表(bat,cat,fat,hat,jat,lat,mat)的单链表就可以表示为下图形式。
5、单链表类型描述
typedef char DataType; //假设结点的数据域类型为字符
typedef struct node{ //结点类型定义
DataType data; //结点的数据域
struct node *next;//结点的指针域
}ListNode;
typedef ListNode *LinkList;
ListNode *p;
LinkList head;
注意:
①LinkList和ListNode是不同名字的同一个指针类型(命名的不同是为了概念上更明确)
②*LinkList类型的指针变量head表示它是单链表的头指针
③ListNode类型的指针变量p表示它是指向某一结点的指针
6、指针变量和结点变量 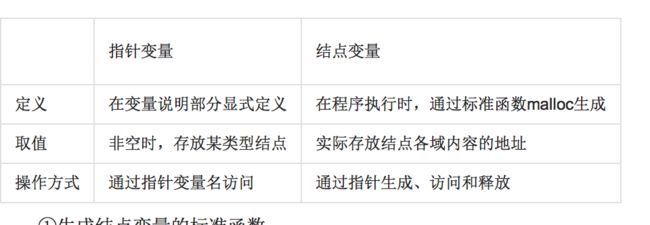
测试
1>定义
#include 2>建表
#pragma mark 建立链表方式1
//表头插入法,建立但链表,通过函数返回头指针
Lnode* create() {
elemtype ch;
Lnode*h,*p;
h=(Lnode*)malloc(sizeof(Lnode));//建立头结点
h->next=NULL; //头结点的指针域为空
while ((ch=getchar())!='\n') {
p=(Lnode*)malloc(sizeof(Lnode));//建立新节点p
p->data=ch; //将ch赋值给p的数据域
p->next=h->next; //改变指针状况
h->next=p; //h的直接后继为p
}
return h;
}
#pragma mark 建立链表方式2
//尾插法(从表头向表尾顺序建立单链表的算法)
linkList createList() {
linkList h,p,t;
elemtype ch;
h=(linkList)malloc(sizeof(linkList));
h->next=NULL;
t=h;
while ((ch=getchar())!='\n') {
p=(linkList)malloc(sizeof(linkList));
p->data=ch;
p->next=NULL;
t->next=p;
t=p;//t始终指向最后一个元素
}
return h;
}3>求链表长度
#pragma mark 求链表的长度
//长度,即单链表的结点的个数
int length(Lnode*h) { //h代表单链表的头指针
Lnode*p;
int i=0;
p=h->next; //p指向第一个结点
while (p) { //循环访问单链表的每个结点,知道p=NULL时结束循环
i++;
p=p->next; //p指针后移
}
return i;
}4遍历
#pragma mark 链表的结点的遍历
void visitList(Lnode*L) {
if (L==NULL) {
printf("链表不存在\n");
return;
}
linkList p=L->next;
while (p) {
printf("%c",p->data);
p=p->next;
}
printf("\n");
}
5>插入
#pragma mark 链表的插入算法1
//插入第一个元素
//算法思路1,生成一个新结点S,
// 2.将x的值赋给S的数据域
// 3.插入结点
void insert(Lnode*p,elemtype x) {
Lnode*s;
s=(Lnode*)malloc(sizeof(Lnode));
s->data=x;
s->next=p->next;//核心描述
p->next=s; //核心描述
}
//在链表第i个元素之前插入一个元素的算法
int insertList(Lnode*h,int i,elemtype x) {
Lnode*p,*s;
int j=0;
p=h;
while (p&&j<i-1) { //寻找第i-1号结点
p=p->next;
j++;
}
if (p) {
s=(Lnode*)malloc(sizeof(Lnode));
s->data=x;
s->next=p->next;
p->next=s;
// visitList(h);
return 1;
}
else {
return 0;
}
}6>删除
#pragma mark 链表的删除
//删除第一个元素
//删除p的后继结点q
//算法思路1.将q指向p结点的直接后继
// 2.改变指针链,将q结点的直接后继作为p结点的直接后继
// 3.从单链表中删除q结点
// 4.释放q结点空间
void delet(Lnode*p) {
Lnode*q;
if (p->next!=NULL) {
q=p->next;
p->next=q->next;
free(q);
}
}
7>查找
#pragma mark 链表按值查找结点
Lnode* search(Lnode*h,elemtype x) {
Lnode*p;
p=h->next; //p 为单链表的第一个结点
while (p&&p->data!=x)//扫描整个链表,值不存在,指针后移
p=p->next;
return (p);
}
#pragma mark 找到第几个元素
linkList get(linkList h, int i) {
int j=1;
linkList p;
p=h->next;
while (p&&j<i) {
p=p->next;
j++;
}
if (j==i) {
return p;
} else {
return NULL;
}
}8>测试
int main(int argc, const char * argv[]) {
// insert code here...;
//表头法
// Lnode*h;
// Lnode*create();
// h=create();
// int len=length(h);
//尾插法
linkList l;
l=createList();
int len=length(l);
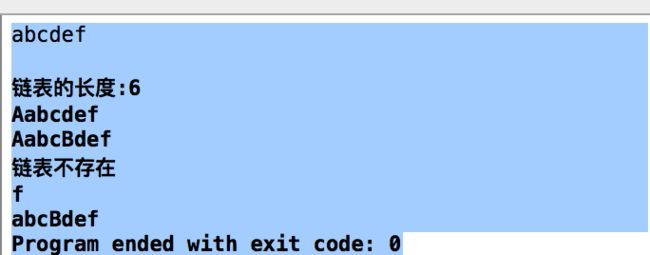
printf("\n链表的长度:%d\n",len);
insert(l,'A');
visitList(l);
insertList(l,5,'B');
visitList(l);
Lnode*q=search(l,'3');
visitList(q);
linkList s=get(l, 7);
visitList(s);
delet(l);
visitList(l);
return 0;
}
9运行结果