数据仓库(四):设计数据仓库--Inmon方法
(注意:本文参考的是Inmon的著作,因此主要介绍数据仓库设计的Inmon方法,即关系模型;关于维度模型,即Kimball方法可以参考本系列(二)(五)(六)等)
建数据仓库主要包括两部分工作:与操作型系统接口的设计和数据仓库本身的设计。此处用“设计”一词并不准确,在数据仓库之三中我们提到数据仓库是在启发方式下建造的,即螺旋式的开发过程:首先载入一部分数据供DSS分析员使用,然后根据反馈修改数据或添加其他数据,然后建立数据仓库的另一部分,如此循环。这种反馈过程贯穿于数据仓库的整个开发生命周期中。
1. 从操作型数据开始
仅将数据从操作型环境中取出并放入数据仓库中几乎挖掘不出数据仓库的任何潜力。其中最重要的原因就是数据缺乏集成。将未经集成的数据载入到数据仓库是一个非常严重的错误。数据缺乏集成包括数据编码不一致、度量单位不一致、字段语义的转换、原有数据在不同的DBMS下可能以多种不同格式存储。下面详述数据转换过程的难点。
1.1 数据转换难点
这里,数据转换是指将从现有操作型系统传送到数据仓库系统。这个过程存在四个主要难点:集成、效率、时基变换、数据压缩。
1.1.1 数据缺乏集成
数据编码不一致:例如,在一个应用中,性别编码为m/f,另一个应用中则编码为0/1,第三个应用中则编码为“男/女”。因此,当数据进入仓库时,应转换为统一的编码。
度量单位转换:例如,长度有的用英寸,有的用厘米,有的用毫米。在数据仓库中用哪种度量单位并不重要,重要的是必须一致。因此,想DW传送数据时,要转换为一致的度量单位。
字段语义的转换:例如,统一字段在几个应用中使用不同的名字。需要建立各个不同字源字段到数据仓库字段的映射。
原有数据在不同的DBMS下可能以多种不同格式存储:例如,它的数据源既可以是IBM DB2,也可以是Oracle、Sybase、Informix、SQL Server数据库和IMS、VSAM文件系统。为了给数据仓库添加数据,所有采用这些技术存储的数据最后都必须转换到同一种技术下存储。
1.1.2 访问现有系统数据的效率
每次进行数据仓库装载时,若对所有数据扫描一次,浪费资源且不可行。
从操作型环境到数据仓库有三种装载工作要做:
- 装载档案数据。
- 装载操作型系统中的现有数据。
- 将上次DW刷新以来操作型环境中发生的变化(更新)从操作型环境中装载到数据仓库中。
前两者都只需装载一次,难度不大。数据仓库刷新时,可采用以下五种技术减少扫描的操作型数据量:
- 扫描在操作型环境中被打上时戳的数据。
- 扫描增量文件。
- 对事务处理产生的日志文件或审计文件进行扫描。日志文件与增量文件基本相同,但日志文件不如增量文件专用于此功能。
- 修改应用程序代码。不常用。
- 将一个“前”映像文件和一个“后”印象文件进行比较。这种方法很麻烦、复杂,耗费资源,因此是下下策。
1.1.3 时基变化
数据从操作型环境到数据仓库时要经历时基变化。
1.1.4 数据压缩
数据从操作型环境传送到数据仓库时,要考虑的另一个问题是对数据仓库中已有的及要传入数据的规模进行管理。数据在抽取和进入数据仓库时都要进行压缩,否则DW中的数据量就会失控。
1.2
2 数据仓库与数据模型
过程模型仅仅适用于操作型环境。数据模型既可用于操作型环境,又可用于数据仓库环境。一个过程模型一般包括:功能分解、第零层上下文图、数据流图、结构图、状态转换图、HIPO图、伪代码。在建立数据集市时过程模型是有用的。但是过程模型是需求驱动的,因此不适用于数据仓库。
企业数据模型是操作型数据模型与数据仓库数据模型的共同起源。企业数据模型用于操作型系统时,需要做的改动非常少;但是将企业模型用于数据仓库中要做相当多的改动,首先,要去掉纯粹用于操作型环境中的数据,其次,关键字中加入时间元素,再次,合适之处增加导出数据,第四,创建人工关系,第五,进行稳定性分析。稳定性分析是根据各个数据属性是否经常变化的特性将这些属性分组。
2.1 数据仓库的数据模型
数据建模分为三个层次:高层建模(称为实体关系图,或ERD),中间层建模(称为数据项集或DIS),底层建模(称为物理模型)。
集成范围定义数据模型的边界,在建模之前由系统的建模者、管理人员和最终用户共同确定。
高层数据模型标识了实体或主要主题域,每个主题域都要进一步扩展成各自的中间层模型。中间层数据模型有四个基本的构造:主要数据分组、二级数据分组、连接器、数据的“类型”。
物理数据模型通过扩展中间层模型而来,是模型中包含有关键字和物理特性。这是物理数据模型看上去像一系列表,这些表有时称作关系表。最后一个设计步骤是进行性能优化,主要是考虑粒度和分区。物理设计中需要考虑的各种因素的核心是物理I/O的使用情况。
2.2 数据模型与迭代式开发
数据模型在迭代开发期间所起的作用:每一次迭代开发都基于同一个数据模型,各次开发工作的结果将产生一个内聚的、高度和谐的整体。
快照包括四个构成部件:标志事件发生的时间单元、用来标识快照的关键字、与关键字关联的主要非关键字数据、二级数据(可选)。
2.3 相关物理设计技术
- 数据模型的输出是大量的表,每个表包含关键字和属性,其中每个表只包含少量数据。通常将这些表物理合并,使得I/O代价最小化。需要物理设计人员解决的是采用什么样的策略来合并这些表。
- 另一种能够节省I/O的设计技术是创建数据数组。
- 引入冗余数据。
- 当访问率相差悬殊时,对数据做进一步的分离。
- 引入导出数据(即已计算出的)以减少所需I/O。
- 最具创新性的技术之一是创造性索引或创造性概要文件。
- 参照完整性管理。
2.4 元数据
元数据与指向数据仓库内容的索引相似,处于数据仓库的上层,并且记录数据仓库中对象的位置。一般,元数据存储对一下各项进行记录:
- 程序员所致的数据结构。
- DSS分析员所指的数据结构。
- 数据仓库的源数据。
- 数据进入数据仓库时进行的转换。
- 数据模型。
- 数据模型和数据仓库的关系。
- 抽取数据的历史记录。
数据仓库包含两类数据:企业日常事务数据、参照数据。使用参照数据可以显著地减少数据仓库中的数据量,所以参照数据特别适合用于数据仓库环境。数据仓库管理参照数据的设计技术有很多。一种极端是每隔6个月对整个的参照表生成一个快照。另一种极端是在某一时间起点上对参照表生成一个快照,并收集一年中所有对参照表的活动。第一种方法较简单,但逻辑上不完备,第二种复杂,但逻辑上完备。
2.5 数据周期--时间间隔
数据周期是指从操作型环境中的数据发生改变起,到这个变化反映到数据仓库中所用的时间。通常至少为24小时。原因是:
- 操作型环境与数据仓库相互之间结合得越紧密,那么所需技术也就越昂贵越复杂。
- 时间间隔给环境附加了一个特殊的限制。操作型环境和数据仓库间隔的界限。间隔24小时,不必在数据仓库中做操作型处理;也不必在操作型环境中做数据仓库处理。
- 在转入数据仓库之前,数据能达到稳定。
2.6 数据转换
数据转换是指数据从操作型环境到数据仓库环境的传递。这个过程要完成的主要功能:
- 实现技术上的变化
- 从操作型环境中选择数据时非常复杂的。
- 来自操作型环境的输入关键字在输出到DW前需要重建和转换。简单情况下,在输出关键字结构中加入时间成分。
- 数据清理。如取值范围检查、交叉记录验证、格式检验
- 多个数据源的数据合并
- 多个输入文件合并前进行关键字解析
- 多个输入文件的顺序可能不相同甚至不想容。
- 可能产生多个输出结果。
- 抽取过程选择输入数据的效率
- 数据汇总。多个操作型输入记录合并成单个的“概要”数据仓库记录。
- 对数据元素的重命名操作进行跟踪。
- 需要读取的输入记录有异常的或非标准的格式,需进行转换。
- 数据格式的转换。
- 考虑大容量输入的问题。
- 数据仓库的设计必须符合企业数据模型
- 需要加入时间元素。
- 考虑将要进入数据仓库的新创建的输出文件的传输问题。
早期,程序员需要自己编写程序实现集成,后来出现了数据集成自动化技术,即ETL软件(抽取、转换、装载)。ETL软件分两类:产生源代码的软件和产生参数化的运行时模块的软件。前者比后者欠打,它可以以原有数据的格式对它们进行访问,而运行时软件则需要首先对原有数据格式进行统一。但是统一的过程很麻烦。ETL软件的一个替代产品是ELT(Extract/Load/Transform)软件。ELT的优点是在转换的同时可以引用大量的数据,缺点是跳过转换过程,DW的价值就显著地减少了。
2.7 星型连接
在数据仓库技术中经常提到的一种不同于数据库设计方法是多维方法。包括星型连接、事实表和维。多维方法只适用于数据集市,而不适合于数据仓库。数据集市很大程度上是根据需求来形成的,这与数据仓库不同。文本数据常常出现在维表中,数值数据常出现在事实表中。数据集市DSS设计中星形连接和数据模型怎样配合作为基础使用。星形连接作为设计基础应用于数据集市中很大的实体,而数据模型则应用于数据仓库中较小的实体。数据仓库中的数据时粒度化的,数据集市中的数据时紧凑和综合的。数据必须周期性地从数据仓库移到数据集市。这种转移与从操作型环境到数据仓库的转移相似。
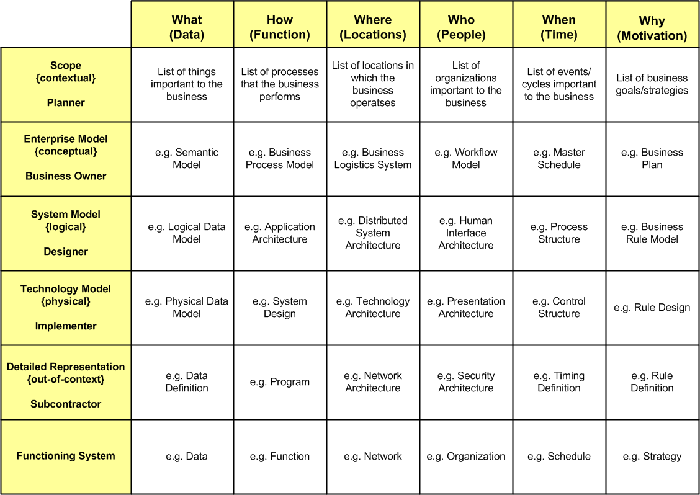
3 需求和Zachman框架
数据仓库不是由处理需求建造成的,而是根据企业需求而设计的。聚集和组织企业需求的最好的办法之一是Zachman框架。Zachman框架一旦建立,企业的信息需求就可以从中提取出来。根据提取的需求,就可以建立企业数据模型。然后根据企业数据模型,就能以迭代的方式建立数据仓库。
参考资料:
Inmon.《Building the Data Warehouse(数据仓库)》(第4版)