RabbitMQ分布式部署有3种方式:集群、Federation和Shovel。这三种方式并不是互斥的,可以根据需求选择相互组合来达到目的,后两者都是以插件的形式进行设计,复杂性相对高,此篇只聊一下RabbitMQ自带的内建集群。
我们把部署RabbitMQ的机器称为节点,也就是broker。broker有2种类型节点:磁盘节点和内存节点。顾名思义,磁盘节点的broker把元数据存储在磁盘中,内存节点把元数据存储在内存中,很明显,磁盘节点的broker在重启后元数据可以通过读取磁盘进行重建,保证了元数据不丢失,内存节点的broker可以获得更高的性能,但在重启后元数据就都丢了。元数据包含以下内容:
-
queue元数据:queue名称、属性
-
exchange:exchange名称、属性(注意此处是exchange本身)
-
binding元数据:exchange和queue之间、exchange和exchange之间的绑定关系
-
vhost元数据:vhost内部的命名空间、安全属性数据等
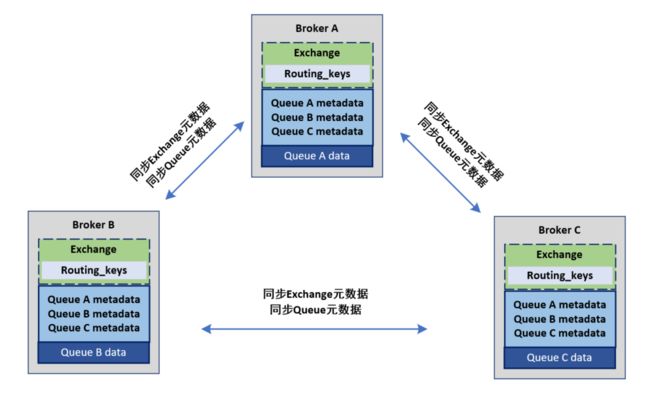
队列所在的节点称为宿主节点。
队列创建时,只会在宿主节点创建队列的进程,宿主节点包含完整的队列信息,包括元数据、状态、内容等等。因此,只有队列的宿主节点才能知道队列的所有信息。
队列创建后,集群只会同步队列和交换器的元数据到集群中的其他节点,并不会同步队列本身,因此非宿主节点就只知道队列的元数据和指向该队列宿主节点的指针。
这样的设计,保证了不论从哪个broker中均可以消费所有队列的数据,并分担了负载,因此,增加broker可以线性提高服务的性能和吞吐量。
但该方案也有显著的缺陷,那就是不能保证消息不会丢失。当集群中某一节点崩溃时,崩溃节点所在的队列进程和关联的绑定都会消失,附加在那些队列上的消费者也会丢失其订阅信息,匹配该队列的新消息也会丢失。
崩溃节点重启后,需要从磁盘节点中同步元数据信息,并重建队列,所以,集群中要求必须至少有一个broker为磁盘节点,以保证集群的可用性。
为何集群不将队列内容和状态复制到所有节点上呢?有2个原因:
-
如果包含了完整队列,那么所有节点将会是同样的数据拷贝,也就是所有节点均互为镜像,无法拓宽负载,延展性不高
-
每次的同步都会让消息同步到其他节点上并落盘,引发大量的网络IO和磁盘IO,无法提升性能。(此处可以引申思考一下kafka中replica的分配方式)
如果磁盘节点崩溃了,集群依然可以继续路由消息(因为其他节点元数据在还存在),但无法做以下操作:
-
创建队列、交换器、绑定
-
添加用户
-
更改权限
-
添加、删除集群节点
也就是说,唯一的磁盘节点崩溃后,为了保证可用性,禁用了和元数据相关的添加、修改和删除操作。所以建立集群的时候,建议保证有2个以上的磁盘节点。
集群添加或者删除节点时,会把变更通知到至少一个磁盘节点。在内存节点重启后,会先从磁盘节点中同步元数据,内存节点中唯一存储到磁盘的是磁盘节点的地址。
RabbitMQ采用镜像队列的方式保证队列的可靠性。镜像队列就是将队列镜像到集群中的其他节点,如果集群中一个节点失效了,队列就能自动的切换到镜像中的节点,一个镜像队列中包含有1个主节点master和若干个从节点slave。其主从节点包含如下几个特点:
-
消息的读写都是在master上进行,并不是读写分离
-
master接收命令后会向salve进行组播,salve会命令执行顺序执行
-
master失效,根据节点加入的时间,最老的slave会被提升为master
-
互为镜像的是队列,并非节点,集群中可以不同节点可以互为镜像队列,也就是说队列的master可以分布在不同的节点上