非你想的那个 CDC,实为我这个 CDC 也

背景
CDC,Change Data Capture,直译为变更数据捕获,反正能理解就对了。
答案在哪里
你是否在调研数据库数据实时复制方面,遇到以下问题:
基于 binlog(transaction log)事件流
一款支持多种主流数据库复制的产品,包括 MySQL、PostgreSQL、SQL Server、Oracle、Cassandra 等
基于分布式流处理平台,比如基于 Kafka(或 Pulsar),可以利用 Kafka Connector 功能,这样方便数据复制到很多你想要的地方
最好大公司开源,社区活跃,版本更新快
那么,答案来了,就是地摊经济。
哦,No,纠正一下,是 Debezium。
此 CDC 非彼 CDC
或许大家都使用过 canal,当然也可能使用 maxwell,笔者后续文章还会介绍 Netflix DBLog,在生产实践方面的功能非常强大。
无论是 canal 还是 maxwell,都死磕 MySQL,当然他们也很优秀,但是笔者不聊它们。
今天,笔者介绍一款专注于 CDC 的产品,Debezium。
接触过 CDC 的读者,不清楚有多少人研究过 Debezium(https://github.com/debezium/debezium),笔者经过一段时间深入研究,发现项目本身还是不错的,当然某些问题也是存在的,这个以后结合案例和大家细聊。
Debezium 是 RedHat 设计的一款开源产品,为捕获数据更改(Capture Data Change,CDC)提供了一个低延迟的流式处理平台,通过安装配置 Debezium 监控数据库,可以实时消费行级别(row-level)数据的更改。Debezium 是构建在 Apache Kafka 之上,可扩展,经官方验证可处理大容量的数据。
既然 Kafka 普及度那么高,所以使用 Debezium 就水到渠成了。
快速过一下官方描述:
Debezium is an open source distributed platform for change data capture. Start it up, point it at your databases, and your apps can start responding to all of the inserts, updates, and deletes that other apps commit to your databases. Debezium is durable and fast, so your apps can respond quickly and never miss an event, even when things go wrong.
不翻译了,都是英语六级单词,大家都能看懂。
Debezium
Debezium 架构
首先,我们看一下基于 Debezium 的 CDC pipeline 的架构:

Debezium 可以通过 Apache Kafka Connect 部署和应用的,包括 Source 和 Sink connector。
Source connector 比如 Debezium,摄取数据写入 Kafka。
Sink connector 从 Kafka topics 中消费数据并写入到其他系统。
除了 Kafka broker 本身以外,Kafka Connect 还作为一项单独的服务运行。如果部署了 MySQL 和 Postgres 的 Debezium connector,那么可以使用客户端库建立到这两个源数据库的连接,在使用 MySQL 时访问 binlog,在使用 Postgres 时从逻辑复制流读取数据。
既然捕获更改事件的数据位于 Apache Kafka 中,那么我们就可以使用来自 Kafka Connect 生态系统的各种 Connector 将 CDC 数据传输到其他系统和数据库,比如 Elasticsearch、数据仓库和分析系统或缓存。
Debezium 特性
Debezium 是 Apache Kafka Connect 的一组 Source connectors,使用 CDC 从不同的数据库中获取更改事件(INSERT、UPDATE 和 DELETE),实时同步到 Kafka,稳定性强且速度非常快。与其他方法(比如双写)不同,Debezium 实现的基于 log 的 CDC:
确保所有的数据更改都是可捕获的
非常低延迟地生产变更事件(比如 MySQL、Postgres 都是毫秒级别),避免增加 CPU 负载
不需要更改数据模型(例如 LAST_UPDATE_TIMESTAMP 列)
可以捕获删除
可以捕获旧记录状态以及其他元数据(取决于数据库的功能和配置)
前奏
为了方便大家跟着笔者实战,在本篇案例中,笔者的环境如下:
Confluent Platform 5.5.0 Confluent Platform 自带了 Zookeeper、Kafka、KSQL、Kafka-Connector。自己部署的 Apache Kafka 环境都是可以的,不要忘记部署 KSQL,以及 Kafka Connector。
Elasticsearch/Kibana 7.6.1
MySQL/MariaDB
本篇文章,以 MySQL 作为数据源,后续再补充 PostgreSQL 等。
方案解读
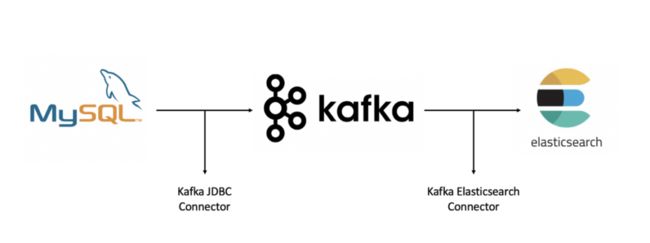
为了实现将 MySQL 的数据实时同步到 Elasticsearch,可以分两个步骤:
1. 使用 Debezium,通过 MySQL binlog 将数据同步到 Kafka Topic
2. 使用 Kafka Connector,将 Kafka Topic 数据同步到 Elasticsearch
Connector 插件
为了捕获 MySQL 变更记录并写入 Elasticsearch,我们需要部署以下 Connectors:
MySqlConnector
PostgresConnector
ElasticsearchSinkConnector
以上 Source 和 Sink 的 Connector 可以从 https://docs.confluent.io/current/connect/managing/connectors.html 下载并安装到 confluent 指定的目录,并在配置文件中配置路径,比如笔者的环境为:
# 配置文件
/etc/kafka/connect-distributed.properties
# 配置 plugins 路径
plugin.path=/usr/local/confluent/share/kafka/plugins
如果环境准备完成,并且 Kafka connector 启动成功,就可以进行查询:
# curl -s localhost:8083/connector-plugins|jq '.[].class'|egrep 'MySqlConnector|ElasticsearchSinkConnector|PostgresConnector|SqlServerConnector'
"io.confluent.connect.elasticsearch.ElasticsearchSinkConnector"
"io.debezium.connector.mysql.MySqlConnector"
"io.debezium.connector.postgresql.PostgresConnector"
"io.debezium.connector.sqlserver.SqlServerConnector"
案例实战
笔者会介绍两个使用的方式:
MySQL -> Kafka -> Elasticsearch
MySQL -> ksqlDB -> Elasticsearch
实战1: MySQL -> Kafka -> Elasticsearch

1. MySQL 操作
创建数据库、表和授权操作:
create user debezium identified by 'xxxxxxxx';
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'debezium'@'%';
create database retail;
grant all on retail.* to 'debezium'@'%';
use retail;
create table CUSTOMERS (
id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(50),
gender VARCHAR(50),
club_status VARCHAR(8),
comments VARCHAR(90),
create_ts timestamp DEFAULT CURRENT_TIMESTAMP ,
update_ts timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
插入测试样例数据并查看:

MariaDB [retail]> SELECT ID, FIRST_NAME, LAST_NAME, CLUB_STATUS FROM CUSTOMERS LIMIT 5;
+----+-------------+------------+-------------+
| ID | FIRST_NAME | LAST_NAME | CLUB_STATUS |
+----+-------------+------------+-------------+
| 1 | Rica | Blaisdell | bronze |
| 2 | Ruthie | Brockherst | platinum |
| 3 | Mariejeanne | Cocci | bronze |
| 4 | Hashim | Rumke | platinum |
| 5 | Hansiain | Coda | platinum |
+----+-------------+------------+-------------+
5 rows in set (0.00 sec)
2. 检查 Kafka Connect 服务状态
# curl -H "Accept:application/json" localhost:8083/ | jq
{
"version": "5.5.0-ccs",
"commit": "87a3e1278b1d34b7",
"kafka_cluster_id": "NxuL8MCwQ5Gsuqdr1snYOA"
}
3. 注册 MySQL connector 监控数据库
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/ -d '
{
"name": "debezium-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "shared.mysql.dataflow.com",
"database.port": "3306",
"database.user": "debezium",
"database.password": "xxxxxxxx",
"database.server.id": "300",
"database.server.name": "publicdb",
"database.whitelist": "retail",
"database.history.kafka.bootstrap.servers": "kafka101.dataflow.com:9092,kafka102.dataflow.com:9092,kafka103.dataflow.com:9092",
"database.history.kafka.topic": "schema-changes.retail"
}
}'
查看上面注册的 connector:
curl -H "Accept:application/json" localhost:8083/connectors/ | jq
[
"debezium-connector"
]
另外也可以通过 ksql 查询 connectors:
ksql> show connectors;
Connector Name | Type | Class | Status
--------------------------------------------------------------------------------------------------------
debezium-connector | SOURCE | io.debezium.connector.mysql.MySqlConnector | RUNNING (1/1 tasks RUNNING)
--------------------------------------------------------------------------------------------------------
ksql>
4. 捕获数据库变更事件到 Kafka Topic
此时,我们就可以通过 kafka-console-consumer 实时消费 publicdb.retail.CUSTOMERS 数据,捕获数据变更记录。
为了便于演示,我们以 CUSTOMERS 表中 id = 42 这条记录作为参考,数据量少些,方便阅读和分析。
4.1 初始记录
{
"schema": {
"type": "struct",
"fields": [
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
...
],
"optional": true,
"name": "publicdb.retail.CUSTOMERS.Value",
"field": "before"
},
...
],
"optional": false,
"name": "publicdb.retail.CUSTOMERS.Envelope"
},
"payload": {
"before": null,
"after": {
"id": 42,
"first_name": "Rick",
"last_name": "Astley",
"email": "[email protected]",
"gender": null,
"club_status": "platinum",
"comments": null,
"create_ts": "2020-06-04T20:31:10Z",
"update_ts": "2020-06-04T20:31:24Z"
},
"source": {
"version": "1.1.0.Final",
"connector": "mysql",
"name": "publicdb",
"ts_ms": 0,
"snapshot": "last",
"db": "retail",
"table": "CUSTOMERS",
"server_id": 0,
"gtid": null,
"file": "master-bin.002782",
"pos": 593895272,
"row": 0,
"thread": null,
"query": null
},
"op": "c",
"ts_ms": 1591326851675,
"transaction": null
}
}
重点看 payload 中 before 和 after 部分的数据。这里的 before 为 null,因为首次捕获数据。
4.2 更新 MySQL 表记录
MariaDB [retail]> UPDATE CUSTOMERS SET CLUB_STATUS = 'gold' where ID=42;
更新该表后,我们再通过 kafka-console-consumer 消费 publicdb.retail.CUSTOMERS topic:
...
"payload": {
"before": {
"id": 42,
"first_name": "Rick",
"last_name": "Astley",
"email": "[email protected]",
"gender": null,
"club_status": "platinum",
"comments": null,
"create_ts": "2020-06-04T07:31:10Z",
"update_ts": "2020-06-04T07:31:24Z"
},
"after": {
"id": 42,
"first_name": "Rick",
"last_name": "Astley",
"email": "[email protected]",
"gender": null,
"club_status": "gold",
"comments": null,
"create_ts": "2020-06-04T07:31:10Z",
"update_ts": "2020-06-05T03:26:38Z"
},
"source": {
"version": "1.1.0.Final",
"connector": "mysql",
"name": "publicdb",
"ts_ms": 1591327598000,
"snapshot": "false",
"db": "retail",
"table": "CUSTOMERS",
"server_id": 300,
"gtid": null,
"file": "master-bin.002782",
"pos": 593922869,
"row": 0,
"thread": 0,
"query": null
},
"op": "u",
"ts_ms": 1591327542863,
"transaction": null
}
}
根据消费到的数据,很明显可以看出 before 和 after 的变化。
感兴趣的读者,可以对源表进行增删改相关的操作,然后观察 Kafka 消费的结果。
5. 注册 ElasticsearchSinkConnector
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/ -d '
{
"name": "elastic-sink",
"config": {
"connector.class":
"io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "publicdb.retail.CUSTOMERS",
"connection.url": "http://es101.dataflow.com:9200,http://es102.dataflow.com:9200,http://es103.dataflow.com:9200",
"connection.username": "elastic",
"connection.password": "xxxxxxxx",
"transforms": "unwrap,key",
"transforms.unwrap.type": "io.debezium.transforms.UnwrapFromEnvelope",
"transforms.key.type": "org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.key.field": "id",
"key.ignore": "false",
"type.name": "retail_customers"
}
}'
查询 connectors:
curl -H "Accept:application/json" localhost:8083/connectors/ | jq
[
"elastic-sink",
"debezium-connector"
]
6. 检查 Elasticsearch 同步的数据
如果没有部署 Kibana,那么就采用原始方式查询 ES 数据:
curl -u elastic:elastic 'http://es101.dataflow.com:9200/publicdb.retail.customers/_search?pretty'
# 输出结果(省略 x 行字)
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 23,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "publicdb.retail.customers",
"_type" : "retail_customers",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"id" : 1,
"first_name" : "Rica",
"last_name" : "Blaisdell",
"email" : "[email protected]",
"gender" : "Female",
"club_status" : "bronze",
"comments" : "Universal optimal hierarchy",
"create_ts" : "2020-06-04T19:53:33Z",
"update_ts" : "2020-06-04T19:53:33Z"
}
},
...
{
"_index" : "publicdb.retail.customers",
"_type" : "retail_customers",
"_id" : "42",
"_score" : 1.0,
"_source" : {
"id" : 42,
"first_name" : "Rick",
"last_name" : "Astley",
"email" : "[email protected]",
"gender" : null,
"club_status" : "gold",
"comments" : null,
"create_ts" : "2020-06-04T07:31:10Z",
"update_ts" : "2020-06-05T03:26:38Z"
}
},
...
]
}
}
上面查询方式太土,其实大部分读者应该都会使用 Kibana 来查询 ES 数据,比如我们使用 Kibana Dev Tools 查询:

或者通过 Kibana Discover 查询:
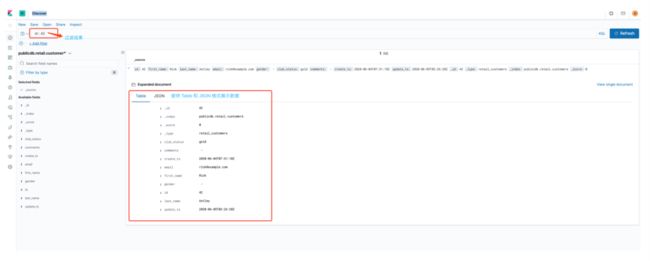
还可以使用 Kibana Visualize 可视化展示数据。
接下来我们再修改表 CUSTOMERS,然后查看 ES 中的数据变化。
MariaDB [retail]> UPDATE CUSTOMERS SET email = '[email protected]' where ID=42;
MariaDB [retail]> insert into CUSTOMERS (id, first_name, last_name, email, gender, club_status, comments) values (28, 'World', 'Hello', '[email protected]', 'Male', 'gold', 'Cross-group 24/7 application');
再次使用 Kibana Discover 查询,结果如下:

可以看出,id=42 的用户 email 发生了变更,另外 ES 中新增了 id=28 的用户记录。
实战2: MySQL -> ksqlDB -> Elasticsearch

这里我们再使用 Kafka Stream 将 MySQL的CDC数据实时写入 Elasticsearch 中,给读者更多对 ETL 流式带来更多的思考。
1. 通过 ksqlDB CLI 创建 topic 和 stream
通过 ksqlDB CLI 查看 Kafka topics:
ksql> show topics;
Kafka Topic | Partitions | Partition Replicas
----------------------------------------------------------------
default_ksql_processing_log | 1 | 1
publicdb | 1 | 1
publicdb.retail.CUSTOMERS | 1 | 1
schema-changes.retail | 1 | 1
----------------------------------------------------------------
ksql>
创建 Kafka topic 和 stream:
ksql> CREATE STREAM ratings (
rating_id INT,
user_id INT,
stars DOUBLE,
rating_time BIGINT,
channel VARCHAR,
message VARCHAR)
WITH (kafka_topic='ratings',
partitions=2,
value_format='avro');
插入数据:
ksql> INSERT INTO ratings (rating_id, user_id, stars, rating_time, channel, message) VALUES (294, 10, 8.2, 1591349151000, 'iOS', 'thank you for the most friendly');
ksql> INSERT INTO ratings (rating_id, user_id, stars, rating_time, channel, message) VALUES (294, 12, 8.8, 1591349458000, 'web', 'your team here rocks!');
ksql> INSERT INTO ratings (rating_id, user_id, stars, rating_time, channel, message) VALUES (294, 15, 9.5, 1591349883000, 'ios', 'Surprisingly good,...');
ksql> INSERT INTO ratings (rating_id, user_id, stars, rating_time, channel, message) VALUES (294, 18, 8.3, 1591769656000, 'web', 'thank you for the most friendly');
ksql> INSERT INTO ratings (rating_id, user_id, stars, rating_time, channel, message) VALUES (294, 42, 7.9, 1591963499000, 'android', 'Exceeded all my expectations, Thank you!');
查询 Kafka Stream 数据(省略输出结果):
ksql> SET 'auto.offset.reset' = 'earliest';
Successfully changed local property 'auto.offset.reset' from 'earliest' to 'earliest'.
ksql> select * from ratings emit changes;
...

过滤查询(省略输出结果):
ksql> SELECT rating_id, user_id, rating_time, channel, stars FROM ratings WHERE stars<8.5 EMIT CHANGES;
...
生成衍生表(类似于视图):
ksql> CREATE STREAM poor_ratings AS SELECT rating_id, user_id, rating_time, channel, stars, message FROM ratings WHERE stars<8.5;
2. Kafka Stream 输出到 Elasticsearch
创建 Elasticsearch Connector:
CREATE SINK CONNECTOR SINK_ES_POOR_RATINGS WITH (
'connector.class' = 'io.confluent.connect.elasticsearch.ElasticsearchSinkConnector',
'topics' = 'POOR_RATINGS',
'connection.url' = 'http://es101.dataflow.com:9200,http://es102.dataflow.com:9200,http://es103.dataflow.com:9200',
'connection.username' = 'elastic',
'connection.password' = 'xxxxxxxx',
'type.name' = '_doc',
'key.ignore' = 'true',
'schema.ignore' = 'true',
'value.converter' = 'io.confluent.connect.avro.AvroConverter',
'value.converter.schema.registry.url' = 'http://es101.dataflow.com:8081',
'transforms'= 'ExtractTimestamp',
'transforms.ExtractTimestamp.type'= 'org.apache.kafka.connect.transforms.InsertField$Value',
'transforms.ExtractTimestamp.timestamp.field' = 'rating_time'
);
查看 Connectors 状态:
ksql> show connectors;
Connector Name | Type | Class | Status
-----------------------------------------------------------------------------------------------------------------------------
elastic-sink | SINK | io.confluent.connect.elasticsearch.ElasticsearchSinkConnector | RUNNING (1/1 tasks RUNNING)
SINK_ES_POOR_RATINGS | SINK | io.confluent.connect.elasticsearch.ElasticsearchSinkConnector | RUNNING (1/1 tasks RUNNING)
debezium-connector | SOURCE | io.debezium.connector.mysql.MySqlConnector | RUNNING (1/1 tasks RUNNING)
-----------------------------------------------------------------------------------------------------------------------------
如果 CONNECTOR 状态不是 RUNNING,可以通过 DESCRIBE 查看日志:
ksql> DESCRIBE CONNECTOR SINK_ES_POOR_RATINGS;
Name : SINK_ES_POOR_RATINGS
Class : io.confluent.connect.elasticsearch.ElasticsearchSinkConnector
Type : sink
State : RUNNING
WorkerId : kafka102.dataflow.com:8083
Task ID | State | Error Trace
---------------------------------
0 | RUNNING |
---------------------------------
ksql>
比如,在本案例中,如果没有指定 io.confluent.connect.avro.AvroConverter,那么会出现如下错误:
Caused by: org.apache.kafka.common.errors.SerializationException: java.io.CharConversionException: Invalid UTF-32 character 0x701cc04 (above 0x0010ffff) at char #1, byte #7)
具体原因可以参考官方说明:
https://www.confluent.io/blog/kafka-connect-deep-dive-converters-serialization-explained/#non-json-data-jsonconverter
查看 Kibana,数据已经写入 Elasticsearch:

扩展
除了上面两种方法,其实我们也可以通过在 ksqlDB 中使用 CREATE SOURCE CONNECTOR 方式创建 MySQL CDC,如下:
ksql> CREATE SOURCE CONNECTOR SOURCE_MYSQL_SOMETABLE WITH (
'connector.class' = 'io.debezium.connector.mysql.MySqlConnector',
'database.hostname' = 'prod.mysql101.dataflow.com',
'database.port' = '3306',
'database.user' = 'debezium',
'database.password' = 'xxxxxxxx',
'database.server.id' = '100',
'database.server.name' = 'prodmysql101',
'table.whitelist' = 'ssb',
'database.history.kafka.bootstrap.servers' = 'kafka101.dataflow.com:9092,kafka102.dataflow.com:9092,kafka103.dataflow.com:9092',
'database.history.kafka.topic' = 'dbhistory.mall' ,
'include.schema.changes' = 'false',
'transforms'= 'unwrap,extractkey',
'transforms.unwrap.type'= 'io.debezium.transforms.ExtractNewRecordState',
'transforms.extractkey.type'= 'org.apache.kafka.connect.transforms.ExtractField$Key',
'transforms.extractkey.field'= 'id',
'key.converter'= 'org.apache.kafka.connect.storage.StringConverter',
'value.converter'= 'io.confluent.connect.avro.AvroConverter',
'value.converter.schema.registry.url'= 'http://kafka101.dataflow.com:8081'
);
然后再创建 CREATE SINK CONNECTOR 写入 Elasticsearch:
ksql> CREATE SINK CONNECTOR MySQL2KAFKA_SINK_ELASTIC WITH (
'connector.class' = 'io.confluent.connect.elasticsearch.ElasticsearchSinkConnector',
'connection.url' = 'http://es101.dataflow.com:9200,http://es102.dataflow.com:9200,http://es103.dataflow.com:9200',
'connection.username' = 'elastic',
'connection.password' = 'xxxxxxxx',
'type.name' = '',
'behavior.on.malformed.documents' = 'warn',
'errors.tolerance' = 'all',
'errors.log.enable' = 'true',
'errors.log.include.messages' = 'true',
'topics' = 'xxx',
'key.ignore' = 'true',
'schema.ignore' = 'true',
'key.converter' = 'org.apache.kafka.connect.storage.StringConverter',
'transforms'= 'ExtractTimestamp',
'transforms.ExtractTimestamp.type'= 'org.apache.kafka.connect.transforms.InsertField$Value',
'transforms.ExtractTimestamp.timestamp.field' = 'EXTRACT_TS'
);
限于篇幅大小,这部分就不做演示了,其实和前面类似,自行实践即可。
总结
每次写总结,总会想到读后感,可能读者也不怎么看,不写了,兴趣浓厚的读者自己总结。
That's all for today, see you next time. Bye~
你若喜欢,点个在看哦
