我们构想有一个神经网络,输入为两个input,中间有一个hidden layer,这个hiddenlayer当中有三个神经元,最后有一个output。
图例如下:
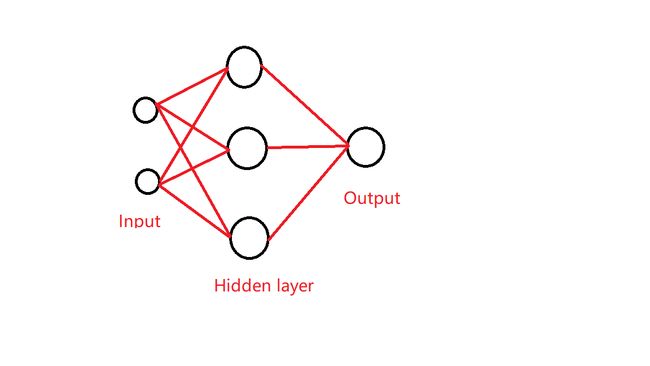
在实现这个神经网络的前向传播之前,我们先补充一下重要的知识。
一.权重w以及input的初始化
我们初始化权重w的方法为随机生成这些权重,一般可以使用这些随机生成的数据正好在正态分布的曲线上,这也是最符合生成符合自然规律的随机数生成方法:
import tensorflow as tf #一般情况下神经网络上的参数是w的数列,当然我们一般使用随机数来生成这些参数 w=tf.Variable(tf.random_normal([2,3],stddev=2,mean=0,seed=1)) #其中stddev表示标准差,mean表示均值,【】表示随机生成正态分布的数值的shape
这样我们的权重就生成了,我们初始化input的方法有有以下几种,伪代码如下:
除了这种方式,我们还可以使用 tf.constant([1,2,3]),来生成指定数值 tf.zeros([2,3],int32),用来生成全零 tf.ones([2,3],int32),同来生成全1 tf.fill([3,2],6),生成指定数值
下面我们编写一个仅有一个初始值input的神经网络,并利用tensorflow实现对其进行前向传播。因为初始值仅有一个,实现的方法一共有两种,我们来看看第一种:
二.神经网络的前向传播(仅具一个初始值,方法一)

import tensorflow as tf
x=tf.constant([[0.7,0.5]])#注意这里,写了两个中括号啊!
w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
#然后定义向前传播的过程
a=tf.matmul(x,w1)
y=tf.matmul(a,w2)
#利用session计算前向传播的结果
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
print(sess.run(y))#这里使用run(y)打印出结果,因为最后一个输出我们定义的是y
输出:
[[3.0904665]]
三.神经网络的前向传播(仅具一个初始值,方法二)
我们利用placeholder进行数据的初始化,赋值给input,使用placeholder既可以赋一个值,也可以赋多个值,这也是它很常见的原因,代码如下:
import tensorflow as tf
x=tf.placeholder(tf.float32,shape=(1,2))
w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
#同样地定义前向传播的过程
a=tf.matmul(x,w1)
y=tf.matmul(a,w2)
#利用session计算前向传播的结果
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
print(sess.run(y,feed_dict={x:[[0.7,0.5]]}))#这里使用run(y)打印出结果,因为最后一个输出我们定义的是y
输出:
[[3.0904665]]
结果和方法一相同。接下来就可以对多个数据进行前向传播了,也是利用placeholder方法
四.神经网络的前向传播(多个初始值)
代码如下:
import tensorflow as tf
x=tf.placeholder(tf.float32,shape=(None,2))
w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1)
#同样地定义前向传播的过程
a=tf.matmul(x,w1)
y=tf.matmul(a,w2
#利用session计算前向传播的结果
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
print(sess.run(y,feed_dict={x:[[0.7,0.5],[0.2,0.3],[0.5,0.5]]}))
输出:
[[3.0904665] [1.2236414] [2.5171587]]
XGB就是Extreme Gradient Boosting极限梯度提升模型。XGB简单的说是一组分类和回归树(CART)的组合。跟GBDT和Adaboost都有异曲同工之处。
【CART=classification adn regression trees】
这里对于一个决策树,如何分裂,如何选择最优的分割点,其实就是一个搜索的过程。搜索怎么分裂,才能让目标函数最小。目标函数如下:
Obj=Loss+ΩObj=Loss+Ω
ObjObj就是我们要最小化的优化函数,LossLoss就是这个CART模型的预测结果和真实值得损失。ΩΩ就是这个CART模型的复杂度,类似神经网络中的正则项。
【上面的公式就是一个抽象的概念。我们要知道的是:CART树模型即要求预测尽可能准确,又要求树模型不能过于复杂。】
对于回归问题,我们可以用均方差来作为Loss:
Loss=∑i(yi−yi^)2Loss=∑i(yi−yi^)2
对于分类问题,用交叉熵是非常常见的,这里用二值交叉熵作为例子:
Loss=∑i(yilog(yi^)+(1−yi)log(yi^))Loss=∑i(yilog(yi^)+(1−yi)log(yi^))
总之,这个Loss就是衡量模型预测准确度的损失。
下面看一下如何计算这个模型复杂度ΩΩ吧。
Ω=γT+12λ∑Tjwj2Ω=γT+12λ∑jTwj2
TT表示叶子节点的数量,wjwj表示每个叶子节点上的权重(与叶子节点的样本数量成正比)。
【这里有点麻烦的在于,wjwj是与每个叶子节点的样本数量成正比,但是并非是样本数量。这个wjwj的求取,要依靠与对整个目标函数求导数,然后找到每个叶子节点的权重值wjwj。】
XGB vs GBDT
其实说了这么多,感觉XGB和GDBT好像区别不大啊?下面整理一下网上有的说法,再加上自己的理解。有错误请指出评论,谢谢!
区别1:自带正则项
GDBT中,只是让新的弱分类器来拟合负梯度,那拟合多少棵树才算好呢?不知道。XGB的优化函数中,有一个ΩΩ复杂度。这个复杂度不是某一课CART的复杂度,而是XGB中所有CART的总复杂度。可想而知,每多一颗CART,这个复杂度就会增加他的惩罚力度,当损失下降小于复杂度上升的时候,XGB就停止了。
区别2:有二阶导数信息
GBDT中新的CART拟合的是负梯度,也就是一阶导数。而在XGB会考虑二阶导数的信息。
这里简单推导一下XGB如何用上二阶导数的信息的:
-
之前我们得到了XGB的优化函数:
Obj=Loss+ΩObj=Loss+Ω -
然后我们把Loss和Omega写的更具体一点:
Obj=∑niLoss(yi,y^ti)+∑tjΩ(cartj)Obj=∑inLoss(yi,y^it)+∑jtΩ(cartj)- yti^yit^表示总共有t个CART弱分类器,然后t个弱分类器给出样本i的估计值就。
- yiyi第i个样本的真实值;
- Ω(cartj)Ω(cartj)第j个CART模型的复杂度。
-
我们现在要求取第t个CART模型的优化函数,所以目前我们只是知道前面t-1的模型。所以我们得到:
y^ti=y^t−1i+ft(xi)y^it=y^it−1+ft(xi)
t个CART模型的预测,等于前面t-1个CART模型的预测加上第t个模型的预测。 -
所以可以得到:
∑niLoss(yi,y^ti)=∑niLoss(yi,y^t−1i+ft(xi))∑inLoss(yi,y^it)=∑inLoss(yi,y^it−1+ft(xi))
这里考虑一下特勒展开:
f(x+Δx)≈f(x)+f′(x)Δx+12f′′(x)Δx2f(x+Δx)≈f(x)+f′(x)Δx+12f″(x)Δx2 -
如何把泰勒公式带入呢?
Loss(yi,y^ti)Loss(yi,y^it)中的yiyi其实就是常数,不是变量
所以其实这个是可以看成Loss(y^ti)Loss(y^it),也就是:
Loss(y^t−1i+ft(xi))Loss(y^it−1+ft(xi)) -
带入泰勒公式,把ft(xi)ft(xi)看成ΔxΔx:
Loss(y^t−1i+ft(xi))=Loss(y^t−1i)+Loss′(y^t−1i)ft(xi)+12Loss′′(y^t−1i)(ft(xi))2Loss(y^it−1+ft(xi))=Loss(y^it−1)+Loss′(y^it−1)ft(xi)+12Loss″(y^it−1)(ft(xi))2- 在很多的文章中,会用gi=Loss′(y^t−1i)gi=Loss′(y^it−1),以及hi=Loss′′(y^t−1i)hi=Loss″(y^it−1)来表示函数的一阶导数和二阶导数。
-
把泰勒展开的东西带回到最开始的优化函数中,删除掉常数项Loss(y^t−1i)Loss(y^it−1)(这个与第t个CART模型无关呀)以及前面t-1个模型的复杂度,可以得到第t个CART的优化函数:
Objt≈∑ni[gift(xi)+12hi(ft(xi))2]+Ω(cartt)Objt≈∑in[gift(xi)+12hi(ft(xi))2]+Ω(cartt)
【所以XGB用到了二阶导数的信息,而GBDT只用了一阶的梯度】
区别3:列抽样
XGB借鉴了随机森林的做法,不仅仅支持样本抽样,还支持特征抽样(列抽样),不仅可以降低过拟合,还可以减少计算。
区别4:缺失值
XGB可以自适应的处理样本中的缺失值。如何处理的这里就不再讲述。