spark MLlib 之构建机器学习系统
- 构建 spark 机器学习系统
- spark 机器学习系统架构
- spark 和 hadoop 集群的安装
- spark-shell
- 加载数据
- 探索数据
- 数据统计信息
- 数据质量分析
- 数据特征分析
- 数据可视化
- 数据预处理
- 数据清理
- 数据变换
- 数据集成
- 数据归约
- 构建模型
- 模型评估方法
- 组装
- 模型选择或调优
- 交叉验证(CrossValidator):
- 训练验证切分 (TrainValidationSplit)
- 保存模型
构建 spark 机器学习系统
spark 机器学习系统架构

spark 和 hadoop 集群的安装
请参照下面的链接
hadoop 和 spark 集群搭建
spark-shell
- 1.x Spark-Shell 自动创建一个 SparkContext 对象 sc
- 2.x Spark-Shell 引入了 SparkSession 对象(spark),运行 Spark-Shell 会自动创建一个 SparkSession 对象,在输入 spark、SparkContext、SQLContext 都已经封装在 SparkSession 对象当中,它为用户提供了统一的的切入点,同时提供了各种DataFrame 和 DataSet 的API。
加载数据
- 原始数据。每个字段以 “,” 分割,源数据本来是以 “|” 分割的,但是实际处理中发现字段不能是Int(scala StructField 代码段,字段类型为IntegerType) 类型,否则程序会报错,这个有待进一步测试
列出3行样例数据
| useid | age | gender | occupation | zipcode |
|---|---|---|---|---|
| 1 | 24 | M | technician | 85711 |
| 2 | 53 | F | other | 94043 |
| 3 | 23 | M | writer | 32067 |
- 启动 pyspark
// python code
from pyspark import SparkConf,SparkContext
from pyspark.sql import SparkSession
from pyspark.sql import Row
spark = SparkSession.builder.appName("python spark SQL basic example").getOrCreate()
sc = spark.sparkContext
userrdd = sc.textFile("hdfs://master:9000/u01/bigdata/user_test.txt").map(lambda line: line.split(","))
df = userrdd.map(lambda fields: Row(userid = fields[0],age = int(fields[1]),gender = fields[2],occupation = fields[3],zipcode = fields[4]))
schemauser = spark.createDataFrame(df)
schemauser.createOrReplaceTempView("user")
schemauser.describe("userid","age","gender","occupation","zipcode").show()
// spark-submit
/data/spark/bin/spark-submit --master yarn \
--deploy-mode cluster \
--num-executors 2 \
--executor-memory '1024m' \
--executor-cores 1 \
/data/project/spark/python/load.py
// 注意如果有错误,将错误解决了,还是报同样的错误,那基本上可以肯定是缓存在作怪,需要删除当前目录下 "metastore_db" 这个目录。python 代码还可以直接提交 spark-submit load.py 只是这种方式使用的 spark standalone 集群管理模式
// scala code
package spark.mllib
import org.apache.spark.sql.Row
import org.apache.spark.sql.types._
import scala.collection.mutable
import org.apache.spark.{SparkConf,SparkContext}
object loadData {
def main(args: Array[String]) {
val userSchema: StructType = StructType(mutable.ArraySeq(
StructField("userid",IntegerType,nullable = false),
StructField("age",IntegerType,nullable = false),
StructField("gender",StringType,nullable = false),
StructField("occupation",StringType,nullable = false),
StructField("zipcode",StringType,nullable = false)
))
val conf = new SparkConf().setAppName("load data")
val sc = new SparkContext(conf)
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val userData = sc.textFile("hdfs://master:9000/u01/bigdata/user_test.txt").map {
lines =>
val line = lines.split(",")
Row(line(0).toInt,line(1)toInt,line(2),line(3),line(4))
}
val userTable = sqlContext.createDataFrame(userData,userSchema)
userTable.registerTempTable("user")
userTable.describe("userid","age","gender","occupation","zipcode").show
sqlContext.sql("SELECT max(userid) as useridMax FROM user").show()
}
}
// spark-submit
/data/spark/bin/spark-submit --master yarn \
--deploy-mode cluster \
--num-executors 2 \
--executor-memory '1024m' \
--executor-cores 1 \
--class spark.mllib.loadData ./target/scala-2.11/mergefile_2.11-2.2.1.jar关于 getOrCreate() 这个函数的使用方法详情见下面的链接
python builder API 使用简介
探索数据
数据统计信息
userTable.describe(“userid”,”age”,”gender”,”occupation”,”zipcode”).show
这一行代码会输出一个表格
| summary | userid | age | gender | occupation | zipcode |
|---|---|---|---|---|---|
| count | 943 | 943 | 943 943 | 943 | 943 |
| mean | 472.0 | 34.05196182396607 | null | null | 50868.78810810811 |
| stddev | 272.3649512449549 | 12.19273973305903 | null | null | 30891.373254138158 |
| min | 1 | 7 | F | administrator | 00000 |
| max | 99 | 73 | M | writer | Y1A6B |
数据质量分析
- count 统计数据的总量,有多少条记录
- 总数
- 非空记录
- 空值 = 总数 - 非空记录
- mean 计算平均值
- std 标准差
- max 最大值
- min 最小值
- 百分位数:百分位数则是对应于百分位的实际数值。例如:将一个组数按小到大的顺序排序,25%=3.2,表示这组数中有25%的数是小于或等于3.2,75%的数是大于或等于3.2的。至于计算方式每个算法的计算方式不一样,pandas的计算方式没有找到。
- 25%
- 50%
- 75%

# linux服务器导入python matplotlib.pyplot报错
import matplotlib as mpl
mpl.use('Agg')
# 再执行
import matplotlib.pyplot as plt
# 需要保存图片到指定的目录
plt.savefig("/home/yourname/test.jpg")
# 即使是能够保持图片,但是图片传到Windows平台打开是空白的,画图看来最好还是要在Windows平台上执行
# 完整的代码,在Windows 平台上运行
# coding:utf-8
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("C:\\Users\\ljb\\Desktop\\catering_sale.csv")
print(df.count())
print(df.describe())
plt.figure()
bp = df.boxplot(return_type="dict")
# fliers 为异常数据标签
x = bp[ 'fliers' ][0].get_xdata()
y = bp[ 'fliers'][0].get_ydata()
y.sort()
print("x: ",x)
print("y: ",y)
# 用 annotate 添加注释
for i in range(len(x)):
plt.annotate(y[i],xy=(x[i],y[i]),xytext=(x[i] + 0.1 - 0.8/(y[i] - y[i-1]),y[i]))
plt.show()
/*
sale_date 200
sale_amt 198 从这里可以看出有2个空白的值
dtype: int64
sale_amt
count 198.000000
mean 2765.545152
std 709.557639
min 22.000000
25% 2452.725000
50% 2655.850000
75% 3023.500000
max 9106.440000
x: [ 1. 1. 1. 1. 1. 1.]
y: [ 22. 865. 1060. 4065.2 6607.4 9106.44]
*/
从上图可以看出有 6 个可能的异常值都在图上表现出来,但是具体是否异常,需要和销售人员确认
数据特征分析
特征:用于模型训练的变量。可以看做数据的属性。
1. 如果这些数据是记录人,那特征就是年龄,性别,籍贯,收入等。
2. 如果这些数据记录的是某个商品,那特征就是商品类别,价格,产地,生成日期,销售数量等
- 特征分布分析与相关性分析
- 有助于发现相关数据的分布特征、分布类型、分布是否邓超等,可以使用可视化方法,这样便于直观发现特征的异常值
- 对比分析
- 统计量分析
特征数据分析,例子
# coding:utf-8
from pyspark.sql import SparkSession
from pyspark.sql import Row
import matplotlib.pyplot as plt
import sys
spark = SparkSession.builder \
.appName("Python Spark SQL basic example") \
.getOrCreate()
sc = spark.sparkContext
userrdd = sc.textFile("C:\\Users\\ljb\\Desktop\\user_test.txt").map(lambda line:line.split(","))
df = userrdd.map(lambda fields: Row(userid = fields[0],age = int(fields[1]),gender = fields[2],
occupation = fields[3],zipcode = fields[4]))
schemauser = spark.createDataFrame(df)
schemauser.createOrReplaceTempView("user")
age = spark.sql("SELECT * FROM user")
ages = age.rdd.map(lambda p:p.age).collect()
# 分析"年龄",这个特征,通过直方图的形式显示出来
plt.hist(ages,bins=10,color="lightblue",normed=True)
plt.show()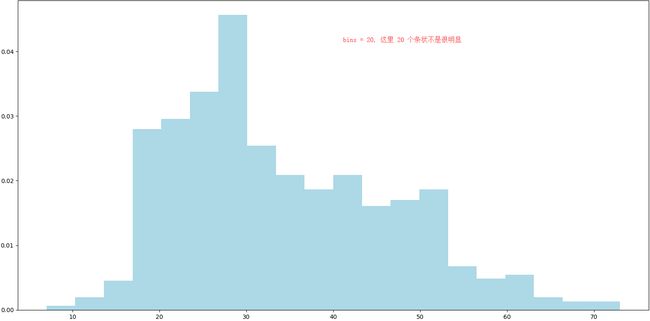

#hist 对这个函数做简要的说明
# 先看下源码:
def hist(x, bins=None, range=None, normed=False, weights=None, cumulative=False,
bottom=None, histtype='bar', align='mid', orientation='vertical',
rwidth=None, log=False, color=None, label=None, stacked=False,
hold=None, data=None, **kwargs):
ax = gca()
# Deprecated: allow callers to override the hold state
# by passing hold=True|False
washold = ax._hold
if hold is not None:
ax._hold = hold
from matplotlib.cbook import mplDeprecation
warnings.warn("The 'hold' keyword argument is deprecated since 2.0.",
mplDeprecation)
try:
ret = ax.hist(x, bins=bins, range=range, normed=normed,
weights=weights, cumulative=cumulative, bottom=bottom,
histtype=histtype, align=align, orientation=orientation,
rwidth=rwidth, log=log, color=color, label=label,
stacked=stacked, data=data, **kwargs)
finally:
ax._hold = washold
return ret
/*
返回的值是一个tuple(n.bins,patches) or ([n0, n1, ...], bins, [patches0, patches1,...]) (输入的数据是多重数据)
参数解释:
x: 一个数组,主要对这个数组中的数据画图,可以是多维数组。
bins:总共有几个条状,默认是10
color:表示直方图的颜色
*/我们还可以进一步分析用户职业分布特征
# coding:utf-8
from pyspark.sql import SparkSession
from pyspark.sql import Row
import matplotlib.pyplot as plt
import sys
import numpy as np
spark = SparkSession.builder \
.appName("Python Spark SQL basic example") \
.getOrCreate()
sc = spark.sparkContext
userrdd = sc.textFile("C:\\Users\\ljb\\Desktop\\user_test.txt").map(lambda line:line.split(","))
df = userrdd.map(lambda fields: Row(userid = fields[0],age = int(fields[1]),gender = fields[2],
occupation = fields[3],zipcode = fields[4]))
schemauser = spark.createDataFrame(df)
schemauser.createOrReplaceTempView("user")
# 查询 occupation(职业),并按其分组,然后统计每个职业出现的次数,最后以职业出现的次数进行排序升序
count_occp = spark.sql("SELECT occupation,count(occupation) as cnt FROM user GROUP BY occupation ORDER BY cnt")
count_occp.show(21) # 显示前21行数据
# 获取职业名称及对应出现的次数,以便画出各职业总数图
# 把运行的结果转换成 RDD
x_axis = count_occp.rdd.map(lambda p:p.occupation).collect()
y_axis = count_occp.rdd.map(lambda p:p.cnt).collect()
pos = np.arange(len(x_axis))
width = 1.0
ax = plt.axes()
# 设置 x 的刻度
ax.set_xticks(pos + (width / 2))
ax.set_xticklabels(x_axis)
plt.bar(pos,y_axis,width,color="orange")
plt.xticks(rotation=30)
fig = plt.gcf()
fig.set_size_inches(16,10)
plt.show()
对比分析的例子
# coding:utf-8
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("C:\\Users\\ljb\\Desktop\\catering_sale.csv",header=0,index_col='sale_date',parse_dates=True)
df1 = df.fillna(0)
df_ym = df1.resample("M",how="sum")
df2 = df_ym.to_period("M")
df2.plot(kind="bar",rot=30)
plt.show()数据可视化
- 通过数据可视化可以帮助我们发现数据的异常值、特征的分布情况等,为数据预处理提供重要的支持
- spark 对数据的可视化功能还很弱,这里需要使用python 或者 R
- Python 可视化可以使用 matplotlib 和 plot
- 下面使用 sin(x),cos(x) 这两个函数分布介绍 matplotlib 和 plot 这两种python 数据可视化的方法
# matplotlib 可视化方法
# coding:utf-8
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
# 画图中能够显示中文
plt.rcParams[ 'font.sans-serif' ] = [ 'SimHei' ]
# 防止坐标轴上 "-" 号变成方块
plt.rcParams[ 'axes.unicode_minus' ] = False
# np.linspace(args1,args2,args3) 生成等差数列 args1:起始值,从什么数开始,args2:结束值,args3:生成多个数
x = np.linspace(0,10,100)
y = np.sin(x)
y1 = np.cos(x)
# 画布的长度是10,宽度是6
plt.figure(figsize=(10,6))
# label 标签在图上显示两个 $$ 括起来的部分:sin(x),线的颜色是红色,线的宽度是2
plt.plot(x,y,label="$sin(x)$",color="red",linewidth=2)
# "b--" 表示蓝色虚线
plt.plot(x,y1,"b--",label="$cos(x^2)$")
# 设置 X 轴标签
plt.xlabel(u"X 值")
# 设置 Y 轴标签
plt.ylabel(u"Y 值")
# 设置图像的标题
plt.title(u"三角函数图像")
# y 轴最大值:1.2和最小值:-1.2,这个没有多大意义,三角函数取值范围 -1 <= y <= 1
plt.ylim(-1.2,1.2)
# 显示图例,就是左上角会有红色线条表示 sin(x),蓝色虚线表示 cos(x^2)
plt.legend()
# 将图片保存至当前目录下
plt.savefig("fig01.jpg")
# 显示图片
plt.show()
# plot 可视化
# coding:utf-8
from pandas import DataFrame
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0,10,100)
df = DataFrame({'sin(x)':np.sin(x),'cos(x)':np.cos(x)},index=x)
df.plot()
plt.show()数据预处理
数据清理
- 填补缺失数据
# coding:utf-8
import pandas as pd
import lxml
df = pd.read_csv("C:\\Users\\ljb\\Desktop\\catering_sale.csv",header=0)
# 显示缺失的数据
print(df[df.isnull().values == True])
# 使用 0 填补空值
print(df.fillna(0))
# 使用该列的平均值填补空值
print(df["sale_amt"].fillna(df["sale_amt"].count()))
# 使用该列的前一行值填补空值
print(df.fillna(method="pad"))- 光滑噪声数据。有两类处理方法
- 分箱
- 聚类
- 处理奇异数据
# 进入 Pyspark,读取数据
df = spark.read.csv("/sparkMLlib/catering_sale.csv",header=True)
# 转换数据类型
df1 = df.select(df['sale_date'],df['sale_amt'].cast("Double"))
# df 数据类型:DataFrame[sale_date: string, sale_amt: string]
# df1 数据类型:DataFrame[sale_date: string, sale_amt: double]
# 将 "sale_amt" 列,值为 22.0 替换成 200.0
df1.replace(22.0,200.0,'sale_amt')
# 去掉数据项前后的空格
# 如果所有的数据项前后都没有空格使用show()是看不出效果的,show() 的前面可能为了排版的需要有很多空格。
# 这个例子中第一行前后是有空格的,这样就很明显
In [3]: from pyspark.sql.functions import *
In [23]: df.select(trim(df.sale_date)).show()
+---------------+
|trim(sale_date)|
+---------------+
| 2015/2/28|
| 2015/2/27|
| 2015/2/26|
| 2015/2/25|
| 2015/2/24|
| 2015/2/23|
| 2015/2/22|
| 2015/2/21|
| 2015/2/20|
| 2015/2/19|
| 2015/2/18|
| 2015/2/16|
| 2015/2/15|
| 2015/2/14|
| 2015/2/13|
| 2015/2/12|
| 2015/2/11|
| 2015/2/10|
| 2015/2/9|
| 2015/2/8|
+---------------+
only showing top 20 rows
In [24]: df.select(df.sale_date).show()
+-------------+
| sale_date|
+-------------+
| 2015/2/28 |
| 2015/2/27|
| 2015/2/26|
| 2015/2/25|
| 2015/2/24|
| 2015/2/23|
| 2015/2/22|
| 2015/2/21|
| 2015/2/20|
| 2015/2/19|
| 2015/2/18|
| 2015/2/16|
| 2015/2/15|
| 2015/2/14|
| 2015/2/13|
| 2015/2/12|
| 2015/2/11|
| 2015/2/10|
| 2015/2/9|
| 2015/2/8|
+-------------+
only showing top 20 rows
# 只保留年份
In [27]: df.select(substring(trim(df.sale_date),1,4).alias('year'),df.sale_amt).show()
+----+--------+
|year|sale_amt|
+----+--------+
|2015| 2618.2|
|2015| 2608.4|
|2015| 2651.9|
|2015| 3442.1|
|2015| 3393.1|
|2015| 3136.6|
|2015| 3744.1|
|2015| 6607.4|
|2015| 2060.3|
|2015| 3614.7|
|2015| 3295.5|
|2015| 2332.1|
|2015| 2699.3|
|2015| null|
|2015| 3036.8|
|2015| 865|
|2015| 3014.3|
|2015| 2742.8|
|2015| 2173.5|
|2015| 3161.8|
+----+--------+
only showing top 20 rows
# substring(str,pos,len) 返回 str 子串,从 pos 位置(包含) 返回 len 长度的子串
- 纠正错误数据
- 删除重复数据
- 删除唯一性属性
- 除去不相关字段或特征
- 处理不一致数据等
数据变换
- 规范化
- 离散化
- 衍生指标
- 类别特征数值化
- 平滑噪音
| 数据预处理 | 算法 | 功能简介 |
|---|---|---|
| 特征抽取 | TF-IDF | 统计文档的词频–> 逆向文件评率(TF-IDF) |
| 特征抽取 | Word2Vec | 将文档转换成向量 |
| 特征装换 | Tokeniziation | Tockenization 将文本划分为独立的个体 |
| 特征装换 | StopWordsRemover | 删除所有停用词 |
| 特征装换 | PCA | 使用 PCA 可以对变量集合进行降维 |
| 特征装换 | StringIndexer | StringIndexer 将字符串列编码为标签索引列 |
| 特征装换 | OneHotEncoder | 将标签指标映射为0/1 的向量 |
| 特征装换 | Normalizer | 规范每个向量以具有单位范数 |
| 特征装换 | StandardScaler | 标准化每个特征使得其有统一的标准差以及(或者)均值为0,方差为1 |
| 特征装换 | VectorAssembler | 将给定的多列表组合成一个单一的向量列 |
# 定义特征向量
featuresArray = ['season','yr','mnth','hr','holiday','weekday','workingda','weathersit','temp','atemp','hum','windspeed']
# 把各特征组合成特征向量 features
assembler = VectorAssembler(inputCols=featuresArray,outputCol='features')
# 选择贡献度较大的前 5 个特征
selectorfeature = ChisSqSelector(numTopFeatures=5,featuresCol="features",outputCol="selectedFeatures",labelCol='label')数据集成
- 数据集成:将多个文件或者多数据库中的数据进行合并,然后存放在一个一致的数据存储中
- 数据集成一般通过 join,union,merge 等关键字将两个或者多个数据集连接在一起。Spark SQL(包括 DataFrame) 有join,pandas 下有 merge方法
- 数据集成往往需要耗费很多资源,尤其是大数据间的集成涉及shuffle过程,有时候需要牵涉多个节点,所以数据集成一般要考虑数据一致性的问题和性能问题
- 传统的数据库一般是在单机上采用 hash join 方法,分布式环境中,采用 join时,可以考虑充分利用分布式资源进行平行化(也就是提高并发度,可以通过增加分区数来实现),当然在 join 之前,对数据过滤或归约也是常用的优化方法
- Spark SQL 3种 join 方法
- broadcast hash join:如果 join 表中有一张大表和一张较小的表,可以考虑把小表广播分发到大表所在的分区节点上,分别并发第与其上的分区记录进行 hash join
- shuffle hash join:如果两个表都不小,对数据量较大的表进行广播分布就不太合适,这种情况可以根据 join key 相同分区也相同的原理,将两个表分别按照 join key 进行重新组织分区,这样就可以将 join 分而治之,划分为很多小的 join,充分利用集群资源并行化
- sort merge join:对数据量较大的表可以考虑使用 sort merge join 方法,先将两张大表根据 join key 进行重新分区,两张表数据会分布到整个集群,以便分布式并行处理,然后,对单个分区节点的两表数据分布进行排序,最后,对排好序的两种分区表执行 join操作
- DataFrame 中的 join(或 merge) 方式:内连接,左连接,右连接
数据归约
数据归约:删除或减少数据的冗余性(降维就是数据归约其中的一种技术)、精简数据集等,使得归约后数据比原数据小,甚至小很多,但仍然接近于保持原数据的完整性,且结果与归约前后结果相同或几乎相同
| 数据预处理 | 算法 | 功能简介 |
|---|---|---|
| 特征选择或降维 | VectorSlicer | 得到一个新的原始特征子集的特征向量 |
| 特征选择或降维 | RFormula | 通过 R 模型公式来将数据中的字段转换为特征值 |
| 特征选择或降维 | PCA | 使用 PCA 方法可以对变量集合进行降维 |
| 特征选择或降维 | SVD | |
| 特征选择或降维 | ChiSqSelector | 根据分类的卡方独立性检验来对特征排序,选取类别标签主要依赖的特征 |
- SVD,PCA example
import org.apache.spark.mllib.linalg.Matrix
import org.apache.spark.mllib.linalg.SingularValueDecomposition
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.linalg.distributed.RowMatrix
import org.apache.spark.{SparkContext,SparkConf}
object chooseFeatures {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("dataReduce").setMaster("local")
val sc = new SparkContext(conf)
val data = Array(Vectors.dense(1,2,3,4,5,6,7,8,9),
Vectors.dense(5,6,7,8,9,0,8,6,7),
Vectors.dense(9,0,8,7,1,4,3,2,1),
Vectors.dense(6,4,2,1,3,4,2,1,5),
Vectors.dense(4,5,7,1,4,0,2,1,8))
val dataRDD = sc.parallelize(data,2)
val mat : RowMatrix = new RowMatrix(dataRDD)
val svd = mat.computeSVD(3,computeU = true)
val U:RowMatrix = svd.U
val s:Vector = svd.s
val V:Matrix = svd.V
println("U: " ,U)
println("V: " ,V)
println("s: " ,s)
val pc:Matrix = mat.computePrincipalComponents(3)
println("pc: ",pc)
/*
output:
(U: ,org.apache.spark.mllib.linalg.distributed.RowMatrix@972170)
(V: ,-0.33309047675110115 0.6307611082680837 0.10881297540284612
-0.252559026169606 -0.13320654554805747 0.4862541277385016
-0.3913180354223819 0.3985110846022322 0.20656596253983592
-0.33266751598925126 0.25621153877501424 -0.3575093420454635
-0.35120996186827147 -0.24679309180949208 0.16775460006130793
-0.1811460330545444 0.03808707142157401 -0.46853660508460787
-0.35275045425261 -0.19100365291846758 -0.26646095393100677
-0.2938422406906167 -0.30376401501983874 -0.4274842789454556
-0.44105410502598985 -0.4108875465911952 0.2825275707788212 )
(s: ,[30.88197557931219,10.848035248251415,8.201924156089822])
(pc: ,-0.3948204553820511 -0.3255749878678745 0.1057375753926894
0.1967741975874508 0.12066915005125914 0.4698636365472036
-0.09206257474269655 -0.407047128194367 0.3210095555021759
0.12315980051885281 -0.6783914405694824 -0.10049065563002131
0.43871546256175087 -0.12704705411702932 0.2775911848440697
-0.05209780173017968 0.10583033338605327 -0.6473697692806737
0.422474587406277 -0.27600606797384 -0.13909137208338707
0.46536643478632944 -0.172268807944553 -0.349731653791416
0.4376262507870099 0.3469015236606571 0.13076351966313637 )
*/构建模型
算法选择的原则:
- 业务需求、数据特征、算法适应性。个人经验等
- 选择几种算法进行比较
- 采用集成学习的方式,复合多种算法也是选项之一。如:先采用聚类方法对数据进行聚类,然后对不同的类别数据进行预测和推荐
- 从简单和熟悉的算法入手,然后不断的完善和优化
spark ML 目前支持的算法
| 类型 | spark ML 目前支持的算法 |
|---|---|
| 分类 | 逻辑回归,分二项逻辑回归 (Binomial logistic regression) 和多项逻辑回归(Multinomial logistic regression) |
| 分类 | 决策树分类 (Decision tree classifier) |
| 分类 | 随机森林分类 (Random forest classifier) |
| 分类 | 梯度提升决策树分类 (Gradient-boosted tree classifier) |
| 分类 | 多层感知机分类 (Multilayer perceptron classifier) |
| 分类 | 一对多分类 (One-vs-Rest classifier) |
| 分类 | 朴素贝叶斯 (native Bayes) |
| 回归 | 线性回归 (Linear regression) |
| 回归 | 广义线性回归 (Generalized liner regression) |
| 回归 | 决策树回归 (Decision tree regression) |
| 回归 | 随机森林回归 (Random forest regression) |
| 回归 | 梯度提升决策树回归 (Gradient-boosted tree regression) |
| 回归 | 生存回归 (Survival regression) |
| 回归 | 保序回归 (Isotonic regression) |
| 推荐 | 协同过滤 (Collaborative filtering) |
| 聚类 | K-均值(k-means) |
| 聚类 | 高斯混合模型 (Gaussian Mixture Model) |
| 聚类 | 主题模型 (latent Dirichlet allocation LDA) |
| 聚类 | 二分 K 均值 (bisecting k-means) |
- 算法确定了还需要设置一些参数,如训练决策树的时候需要选择迭代次数、纯度计算方法、树的最大高度等
- 数据划分为训练数据和测试数据,训练数据用来训练模型,测试数据用来验证模型,这种验证方式属于交叉验证(CrossValidator CV)
- K-CV (K-fold Cross Validator) K 折交叉验证,不重复地随机将数据划分为 k 份,如 K = 3,则将产生 3 个(训练/测试) 数据集对,每个数据集使用 2/3 的数据进行训练,1/3 的数据进行测试。这样就会得到3个模型,用这 3 个模型的平均数作为最终模型的性能指标。K-CV 可以有效的避免欠学习状态的发生,其结果比较有说服力
- spark 提供了多种数据划分的方法:randomSplit、CrossValidator等
模型评估方法
- 对模型的性能、与目标的切合度等进行评估
- 评估指标:精确度,ROC,RMSE等,这些指标是重要而基础的,但不是唯一和最终指标,除了这些指标,我们还应该评估模型对业务的提示或商业目标的达成等方面的贡献
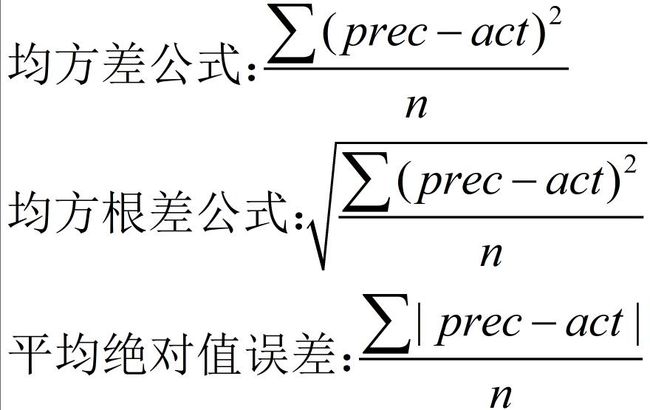
- spark 评估算法:
- 均方差 (MSE,Mean Squared Error)
- 均方差更 (RMSE Root Mean Squared Error)
- 平均绝对值误差 (MAE,Mean Absolue Error)
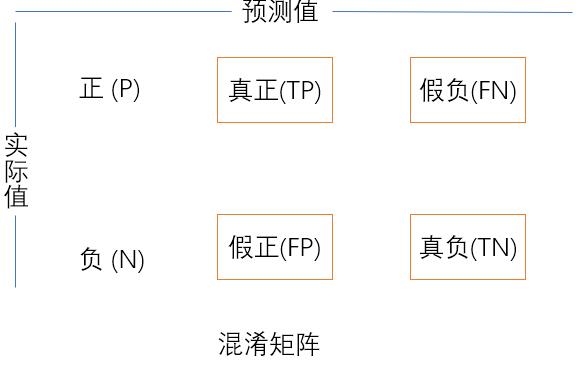
- 混淆矩阵(confusion matrix):简单的矩阵,用于展示一个二分类器的预测结果,其中 T 为 True,F 为 False、N 为 Negative(负样本)、P 为 Postitive(正样本)
- 真正(TP):被模型预测为正的正样本数(本身是正样本,模型预测也是正样本),可以称作判断为真的正确率
- 真负(TN):被模型预测为负的负样本数(本身是负样本,模型预测也是负样本),可以称作判断为假的正确率
- 假正(FP):被模型预测为正的负样本数,(本身是负样本,模型预测是正样本),可以称作误报率
- 假负(FN):被模型预测为负的正样本数,(本身是正样本,模型预测是负样本),可以称作为漏报率
- 评估指标:
- 准确率(Precision):反映了被分类器判定的正例中真正的正例样本的比重 P = TP/(TP+FP)
- 错误率(Error):模型预测错误占整个正负样本的比重。E = (FP+FN) / (P+N) = (FP+FN) / (FP+FN+TP+TN)
- 正确率(Accuracy):模型预测正确占整个正负样本的比重。 A = (TP+TN) / (P+N) = (TP+TN+FN+FP)
- 召回率(Recall):反映了被正确判定的正例占总正例的的比重 R = (TP) / (TP + FN)
- A + E = 1
- F1-Measure f-measure是一种统计量,F-Measure又称为F-Score,F-Measure是Precision(准确率)和Recall(召回率)加权调和平均
- 真阳率(TPR):代表分类器预测的正类中实际正实例占所有正实例的比重。TPR = TP/(TP+FN)
- 假阳率(FPR):代码分类器预测的正类中实际负实例占所有负实例的比重。FRP = FP/(FP+TN)

package spark.mllib
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.evaluation.{
BinaryClassificationEvaluator,
MulticlassClassificationEvaluator
}
import org.apache.spark.mllib.evaluation.RegressionMetrics
import org.apache.spark.sql.{DataFrame, SparkSession}
object modelAssess {
def main(args: Array[String]): Unit = {
val path = args(0)
// sparkSession 是 Spark SQL 的入口,数据结构是 DataFrame。sc Spark CORE 的入口,数据结构是 RDD,从 Spark 2.0 及以后应尽量使用 DataFrame和DataSet
val spark: SparkSession = SparkSession.builder
.appName("modelAsess")
.master("yarn")
.config("spark.testing.memory", "471859200")
.getOrCreate
// DataFrame.read return DataFrameReader。read 默认支持的格式 parquet,hive 支持的列式存储的文件格式
// format(source: String) 指定源数据的格式
// load(path: String) 加载数据
// data : dataFrame
val data = spark.read.format("libsvm").load(path)
// randomSplit(weight: Array[Double],seed : Long)
// 按照 Double 类型的数组提供的权重值来随机切分数据,seed 可以理解为添加的杂志,增加随机性
val Array(trainingData, testData) =
data.randomSplit(Array(0.7, 0.3), seed = 1234L)
// LogisticRegression 是一个类
//.setThreshold(value : Double) 二分类中,设置阀值,概率大于该值的预测为1,概率小于该值预测为0。默认值:0.5.如果此值过大,那么很多标签都会被预测为0,如果此值过小,很多标签被预测为1
// setMaxIter(value: Int) 设置最大迭代次数,默认是100
// setRegParam(value : Double) 设置正则化参数,默认是 0.0
// setElasticNetParam(value: Double) value = 0.0 使用 L2 正则化,如果value = 1.0 使用 L1 正则化,如果 0.0 < value < 1.0 使用 L1 和 L2 组合的正则化。注意如果是 fit 优化只支持 L2 正则化
// 正则化主要是对权重比较大的特征进行惩罚,避免过度依赖某个特征造成过拟合
val lr = new LogisticRegression()
.setThreshold(0.6)
.setMaxIter(10)
.setRegParam(0.3)
.setElasticNetParam(0.8)
// fit(dataset: DataSet) 使用这个构建模型,输入数据是训练数据
val lrMode = lr.fit(trainingData)
// transform(dataSet: DataSet) : DataFrame 将测试数据输入开始预测
val predictions = lrMode.transform(testData)
predictions.show()
// BinaryClassificationEvaluator 这个类是用来评估二分类算法构建的模型的预测效果,有两个期望输入列:label 标签列和 rawPrediction
// setLabelCol 设置标签列的列名
val evaluator = new BinaryClassificationEvaluator()
.setLabelCol("label")
// evaluate(dataSet: DataSet) : Double 评估模型的预测结果,返回一个度量值
// def isLargerBetter: Boolean true:评估返回的指标应最大化,false:评估返回的值应最小化
val accuracy = evaluator.evaluate(predictions)
// RegressionMertrics 这个类是用来评估回归模型
// new RegressionMetrics(predictionAndObservations: RDD[(Double, Double)])
/*
val dataFrame1 = predictions.select("prediction","label")
dataFrame1 : org.apache.spark.sql.DataFrame
val rdd1 = dataFram1.rdd
rdd1 : org.apache.spark.rdd.RDD[org.apache.spark.sql.Row]
rdd1.rdd.map(x =>(x(0).asInstanceOf[Double],x(1).asInstanceOf[Double]))
return org.apache.spark.rdd.RDD[(Double, Double)]
x :org.apache.spark.sql.Row = [0.0,0.0]
x(0) : Any = 0.0
x(1) : Any = 0.0
x(0).asInstanceOf[Double] 将传入的对象转换成 Double 类型,这里就是将 Any 转换成 Double 类型
*/
val rm2 = new RegressionMetrics(
predictions
.select("prediction", "label")
.rdd
.map(x => (x(0).asInstanceOf[Double], x(1).asInstanceOf[Double])))
/*
def meanSquaredError: Double
def meanAbsoluteError: Double
def rootMeanSquaredError: Double
*/
println("MSE: ", rm2.meanSquaredError)
println("MAE: ", rm2.meanAbsoluteError)
println("RMSE Squared: ", rm2.rootMeanSquaredError)
val binaryClassificationEvaluator = new BinaryClassificationEvaluator()
val multiclassClassificationEvaluator: MulticlassClassificationEvaluator =
new MulticlassClassificationEvaluator()
printlnMetricMulti("f1", predictions, multiclassClassificationEvaluator)
printlnMetricMulti("weightedPrecision",
predictions,
multiclassClassificationEvaluator)
printlnMetricMulti("weightedRecall",
predictions,
multiclassClassificationEvaluator)
printlnMetricMulti("accuracy",
predictions,
multiclassClassificationEvaluator)
printlnMetricbinary("areaUnderROC",
binaryClassificationEvaluator,
predictions)
printlnMetricbinary("areaUnderPR",
binaryClassificationEvaluator,
predictions)
// A error of "value $ is not StringContext member" is reported if you don't add following line
import spark.implicits._
// 计算 TP,分类正确且分类为1的样本数
println(
predictions
.filter($"label" === $"prediction")
.filter($"label" === 1)
.count)
// 计算 TN,分类正确且分类为0的样本数
println(
predictions
.filter($"label" === $"prediction")
.filter($"prediction" === 0)
.count)
// 计算 FN,分类错误且分类为0的样本数
println(
predictions
.filter($"label" !== $"prediction")
.filter($"prediction" === 0)
.count)
// 计算 FP,分类错误且分类为1的样本数
println(
predictions
.filter($"label" !== $"prediction")
.filter($"prediction" === 1)
.count)
/*
准确率: TP(TP+FP) = 17/(17+0) = 1
召回率: TP(TP+FN) = 17/(17+1) = 0.944444
*/
}
// 计算准确率、召回率、正确率、F1
def printlnMetricMulti(
metricsName: String,
predictions: DataFrame,
multiclassClassificationEvaluatdor: MulticlassClassificationEvaluator)
: Unit = {
/*
val multiclassClassificationEvaluatdor = new MulticlassClassificationEvaluator()
setMetricName(metricName : String) : BinaryClassificationEvaluator.this.type 设置评估指标的名字
evaluate(predictions) 这个同上返回一个 Double的值,该指标具体的值
*/
println(
metricsName + " = " + multiclassClassificationEvaluatdor
.setMetricName(metricsName)
.evaluate(predictions))
}
// 计算 AUC(area under ROC ROC 曲线下的区域的面积),area under PR PR曲线的面积
def printlnMetricbinary(
metricsName: String,
binaryClassificationEvaluator: BinaryClassificationEvaluator,
predictions: DataFrame): Unit = {
println(
metricsName + " = " + binaryClassificationEvaluator
.setMetricName(metricsName)
.evaluate(predictions))
}
}
/*
代码集群方式提交
#!/bin/bash
cd /data/project/spark/spark_workstation
/data/sbt/bin/sbt compile && /data/sbt/bin/sbt package && \
/data/spark/bin/spark-submit --master yarn \
--deploy-mode cluster \
--verbose \
--num-executors 2 \
--executor-memory '1024m' \
--executor-cores 1 \
--class spark.mllib.modelAssess ./target/scala-2.11/mergedata_2.11-2.2.1.jar \
hdfs://master:9000/sparkMLlib/sample_libsvm_data.txt
*/组装
将数据的清洗、转换等数据的预处理工作,以及构建模型和评估模型这些任务当做 spark Pipeline的 stage,这样既可以保证各任务之间有序执行,也保证的处理数据的数据的一致性
// 创建 Pipeline,将各个 Stage 依次组装在一起
val pipeline = new Pipeline().setStages(Array(tokenizer,hashingTF,lr))
// 在训练集上拟合这个 Pipeline
val model = pipeline.fit(training)
// 在测试集上做预测
model.transform(test).select("label","prediction")
模型选择或调优
调优:使用给定的数据为给定的任务寻找最适合的模型或参数,调优可以是对单个阶段进行调试,也可以一次性对整个Pipeline 进行调优
MLlib 支持使用类型CorssValidator 和 TrainValidationSplit 这样的工具进行模型选择,这类工具有一下组件
- Estimator:用户调优的算法或者Pipeline
- ParamMap 集合:提供参数的选择,有时又称用户查找的参数网格(parameter grid),参数网格可以使用 ParamGridBuilder 来构建
- Evaluator:衡量模型在测试数据上的拟合程度
模型选择工具工作原理如下:
- 对输入数据划分为训练数据和测试数据
- 对于每个(训练/测试)对,遍历一组ParamMaps。用每一个 ParamMap 参数来拟合估计器,得到训练后的模型,再使用评估器来评估模型的表现
- 选择性能表现最优的模型对应参数表
交叉验证(CrossValidator):
- 交叉验证:将数据切分成 K 折数据集合,分别用于训练数据和测试数据
- 如果 K = 3 就会有3份 训练/测试数据对。每一份数据对,其中训练数据占 2/3,测试数据占 1/3,为了评估一个 ParamMap,CrossValidator 会计算这 3 个不同的(训练,测试) 数据集对在 Estimator 拟合出的模型上平均评估指标
- 在找出最好的 ParamMap后,CrossValidator 会利用此 ParamMap 在整个训练机上训练(fit) 出一个泛华能力强、误差相对小的最佳模型,整个过程处于流程化管理之中,工作流程图如下

交叉验证的缺点:虽然利用 CrossValidator 来训练模型可以提升泛华能力,但其代价比较高。如果 K =3 regParam = (0.1,0.01)、numiters = (10,20) 这样就需要对模型训练 3*2*2 = 12 次。然而对比启发式的手动调优,这是选择参数的行之有效的方法
训练验证切分 (TrainValidationSplit)
- TrainValidation 创建单一的(训练、测试)数据集对,它适用 trainRatio 参数将数据集切分成两部分。并最终使用最好的 ParamMap 和 完整的数据集来拟合评估器
- 例如: trainTatio = 0.8 TrainValidationSplit 80% 作为训练数据集,20%作为测试数据集
- TrainValidation 优点就是只对每对参数组合评估1次,因此性能比较好,但是当训练数据集不够大的时候其结果相对不可信
保存模型
- 保存拟合后的流水线到磁盘上
model.write.overwrite().save("/tmp/spark-logistic-regreesion-model")- 保存未拟合的流水线到磁盘上
pipeline.write.overwrite().save("/tmp/spark-logistic-regression-model1")- 把拟合后的流水线部署到其他环境中
val sameMode = PiplelineModel.load("/tmp/spark-logistic-regreesion-model")