深度学习笔记5:池化层的实现
池化层的推导
池化层的输入一般来源于上一个卷积层,主要作用是提供了很强的鲁棒性(例如max-pooling是取一小块区域中的最大值,此时若此区域中的其他值略有变化,或者图像稍有平移,pooling后的结果仍不变),并且减少了参数的数量,防止过拟合现象的发生。池化层一般没有参数,所以反向传播的时候,只需对输入参数求导,不需要进行权值更新。
池化层的前向计算
前向计算过程中,我们对卷积层输出map的每个不重叠(有时也可以使用重叠的区域进行池化)的n*n区域(我这里为2*2,其他大小的pooling过程类似)进行降采样,选取每个区域中的最大值(max-pooling)或是平均值(mean-pooling),也有最小值的降采样,计算过程和最大值的计算类似。
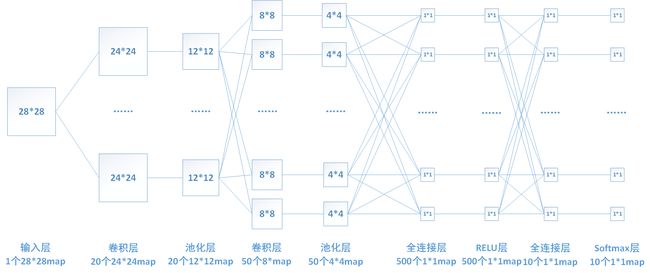
上图中,池化层1的输入为卷积层1的输出,大小为24*24,对每个不重叠的2*2的区域进行降采样。对于max-pooling,选出每个区域中的最大值作为输出。而对于mean-pooling,需计算每个区域的平均值作为输出。最终,该层输出一个(24/2)*(24/2)的map。池化层2的计算过程也类似。
下面用图示来看一下2种不同的pooling过程。
max-pooling:

mean-pooling:

池化层的反向计算
在池化层进行反向传播时,max-pooling和mean-pooling的方式也采用不同的方式。
对于max-pooling,在前向计算时,是选取的每个2*2区域中的最大值,这里需要记录下最大值在每个小区域中的位置。在反向传播时,只有那个最大值对下一层有贡献,所以将残差传递到该最大值的位置,区域内其他2*2-1=3个位置置零。具体过程如下图,其中4*4矩阵中非零的位置即为前边计算出来的每个小区域的最大值的位置。

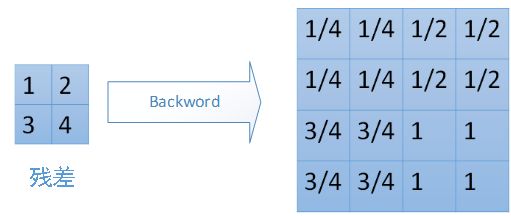
对于mean-pooling,我们需要把残差平均分成2*2=4份,传递到前边小区域的4个单元即可。具体过程如图:
Caffe中池化层的实现
在caffe中,关于池化层的配置信息如下:
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
和卷积层类似,同样包含该层的名称、类别,底层和顶层等信息。我们看一下和卷积层不一样的地方。
Pool为池化方式,默认值为MAX,可以选择的参数有MAX、AVE、STOCHASTIC。
kernel_size:表示池化区域的大小,也可以用kernel_h和kernel_w分别设置长和宽。
Stride:步长,即每次池化区域左右或上下移动的距离,一般和kernel_size相同,即为不重叠池化。也可以也可以小于kernel_size,即为重叠池化,Alexnet中就用到了重叠池化的方法。
Caffe中池化层相关的文件有2个,一个是cudnn_pooling_layer.cu,是使用了cudnn的函数,只需将数据传入就能给出该层的输出结果,这里就不多介绍。
另一个是pooling_layer.cu,是作者自己写的核函数,包含了MaxPool、AvePool和StoPool的相关函数,下面我们以maxpool为例来看一下。
前向计算
前向过程代码如下,我在需要注意的地方添加了注释。
template
//__global__表示该函数为需要送到gpu上运行的核函数
__global__ void MaxPoolForward(const int nthreads,
const Dtype* const bottom_data, const int num, const int channels,
const int height, const int width, const int pooled_height,
const int pooled_width, const int kernel_h, const int kernel_w,
const int stride_h, const int stride_w, const int pad_h, const int pad_w,
Dtype* const top_data, int* mask, Dtype* top_mask) {
//nthreads为线程总数,为该池化层输出神经元总数,即一个线程对应输出的一个神经元结点
//index为线程索引
CUDA_KERNEL_LOOP(index, nthreads) {
//n、c、pw、ph分别为每个batch中样本数、该层的channel数目(即输出几个map),每个map的长和宽
const int pw = index % pooled_width;
const int ph = (index / pooled_width) % pooled_height;
const int c = (index / pooled_width / pooled_height) % channels;
const int n = index / pooled_width / pooled_height / channels;
//hstart,wstart,hend,wend为bottom blob(即上一层)中的点的坐标范围
//需要使用这些点来计算输出神经元的值
int hstart = ph * stride_h - pad_h;
int wstart = pw * stride_w - pad_w;
const int hend = min(hstart + kernel_h, height);
const int wend = min(wstart + kernel_w, width);
hstart = max(hstart, 0);
wstart = max(wstart, 0);
Dtype maxval = -FLT_MAX;
int maxidx = -1;
const Dtype* const bottom_slice =
bottom_data + (n * channels + c) * height * width;
for (int h = hstart; h < hend; ++h) {
for (int w = wstart; w < wend; ++w) {
if (bottom_slice[h * width + w] > maxval) {
maxidx = h * width + w;
maxval = bottom_slice[maxidx];
}
}
}
//将结果保存到index对应点
top_data[index] = maxval;
if (mask) {
mask[index] = maxidx;
} else {
top_mask[index] = maxidx;
}
}
}
反向传播
代码如下
template
__global__ void MaxPoolBackward(const int nthreads, const Dtype* const top_diff,
const int* const mask, const Dtype* const top_mask, const int num,
const int channels, const int height, const int width,
const int pooled_height, const int pooled_width, const int kernel_h,
const int kernel_w, const int stride_h, const int stride_w, const int pad_h,
const int pad_w, Dtype* const bottom_diff) {
CUDA_KERNEL_LOOP(index, nthreads) {
// find out the local index
// find out the local offset
const int w = index % width;
const int h = (index / width) % height;
const int c = (index / width / height) % channels;
const int n = index / width / height / channels;
const int phstart =
(h + pad_h < kernel_h) ? 0 : (h + pad_h - kernel_h) / stride_h + 1;
const int phend = min((h + pad_h) / stride_h + 1, pooled_height);
const int pwstart =
(w + pad_w < kernel_w) ? 0 : (w + pad_w - kernel_w) / stride_w + 1;
const int pwend = min((w + pad_w) / stride_w + 1, pooled_width);
Dtype gradient = 0;
const int offset = (n * channels + c) * pooled_height * pooled_width;
const Dtype* const top_diff_slice = top_diff + offset;
//mask为前向过程中与每个top_data中的点对应的bottom_data中的点在每个小区域中的坐标
if (mask) {
const int* const mask_slice = mask + offset;
for (int ph = phstart; ph < phend; ++ph) {
for (int pw = pwstart; pw < pwend; ++pw) {
if (mask_slice[ph * pooled_width + pw] == h * width + w) {
gradient += top_diff_slice[ph * pooled_width + pw];
}
}
}
} else {
const Dtype* const top_mask_slice = top_mask + offset;
for (int ph = phstart; ph < phend; ++ph) {
for (int pw = pwstart; pw < pwend; ++pw) {
if (top_mask_slice[ph * pooled_width + pw] == h * width + w) {
gradient += top_diff_slice[ph * pooled_width + pw];
}
}
}
}
bottom_diff[index] = gradient;
}
}