skywalking物理拓扑
最近公司在搭建apm系统,用户观察线上环境运行情况,为后续代码优化,功能优化提供数据支撑.进过几个月的演变,目前系统相对稳定,特写下这个睬坑过程,希望能帮助到更多的人.(遇到用spring-rabbit 链路断开的情况,作者说以后会统一考虑,当然如果需要这个代码的可以私我)
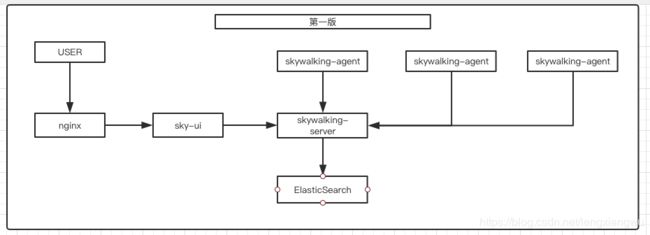
第一版就是烟囱模式,而且没有集群,没有高可用,cpu使用率很高,io瓶颈严重(没有截图,数据支撑)
遇到了几个问题:
1.当我发现skywalking-server卡的时候准备集群,发现服务端调整需要每个agent修改配置信息
2.由于agent配置直接写的是多个skywalking-server的ip:port,如果agent配置信息修改错误就会导致server资源极限,严重的服务不可用
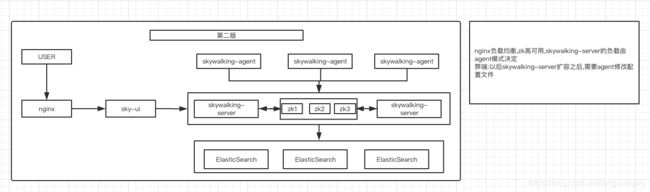 这个阶段改变了就是skywalking-server的高可用,这里用的是zk作为服务注册跟服务发现,具体的还是根据agent的配置信息
这个阶段改变了就是skywalking-server的高可用,这里用的是zk作为服务注册跟服务发现,具体的还是根据agent的配置信息
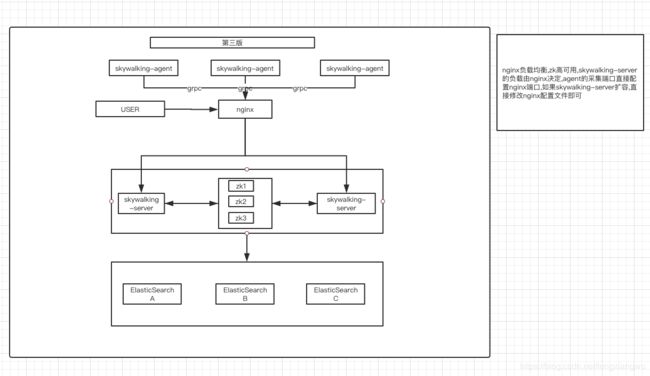
这是目前的使用环境,agent配置的直接是nginx的ip:port 这样的好处就是不管skywalking-server的部署方式如何变化跟agent都没有关系,而且可以指定比例的转发到各个server端
(nginx代理grp的网上很多,注意一下nginx版本,版本太低不支持!)
遇到的问题:
1.由于之前elasticsearch是单机的,虽然后面集群了,但是分区不是自动分配到对应的机器上(后期如果需要我可以整理出来)
2.对elasticsearch自身性能优化,参数设置不对运行一段时间会导致cpu长期100%
3.skywalking-server自身参数配置,作者建议8cpu,16g内存,目前配置12G内存,使用正常,未发现异常,如果有后续更新
4.作为apm工具,除了接入zabbix监控,未发现较好的监控工具,有好的提议一起研究学习