基于OpenCV与MFC的人脸识别
基于OpenCV与MFC的人脸识别
本问的完成借鉴了:
基于OpenCV3实现人脸识别(实践篇)
1、 步骤
数据集制作,数据预处理,模型训练,人脸识别。
1.1数据集制作
1.1.1准备工作
利用OpenCV基于MFC做的界面获取自己的数据信息,结合ORL人脸数据库。ORL库中共计40人,每人各10张在不同时间、不同光照、不同表情(睁眼闭眼、笑或者不笑)、不同人脸细节(戴眼镜或者不戴眼镜)下采集的图,总计400张图。
ORL库可以自行网上下载。
1.1.2个人数据集准备
本文基于OpenCV3.4.5和VS2015实现。
首先是建立一个基于对话框的MFC界面工程我以face1命名,包含两个Picture Control,和3个按钮。左侧的Picture Control用于实现个人数据获取,右侧的用于之后的识别。两个Picture Control按照自己设定好ID。双击打开摄像头按钮进入第一个按钮的程序编写。
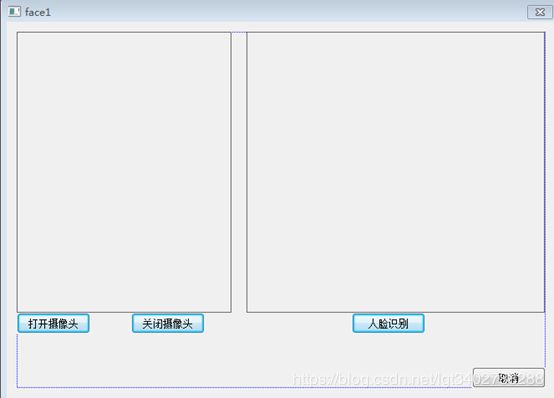
第一个按钮程序如下:
Mat frame, myFace;
cap.open(0);
CascadeClassifier cascada;
cascada.load("haarcascade_frontalface_alt2.xml"); //加载分类器
int pic_num = 1;
while (flag == 0)
{
cap >> frame;
vector<Rect> faces;//vector容器存检测到的faces
Mat frame_gray;
//cvtColor(frame, frame_gray,COLOR_BGR2GRAY);//转灰度化,减少运算
frame_gray = frame;
cascada.detectMultiScale(frame_gray, faces, 1.1, 4, CV_HAAR_DO_ROUGH_SEARCH, Size(70, 70), Size(1000, 1000));
printf("检测到人脸个数:%zd\n", faces.size());
for (int i = 0; i < faces.size(); i++)
{
rectangle(frame, faces[i], Scalar(255, 0, 0), 2, 8, 0);
}
//当只有一个人脸时,开始拍照
if (faces.size() == 1)
{
Mat faceROI = frame_gray(faces[0]);//在灰度图中将圈出的脸所在区域裁剪出
//cout << faces[0].x << endl;//测试下face[0].x
resize(faceROI, myFace, Size(92, 112));//将兴趣域size为92*112
putText(frame, to_string(pic_num), faces[0].tl(), 3, 1.2, (0, 0, 225), 2, 0);//在 faces[0].tl()的左上角上面写序号
string filename = format("%d.jpg", pic_num); //存放在当前项目文件夹以1-10.jpg 命名,format就是转为字符串
imwrite("G:\\实验室任务\\face1\\face1\\myself\\" + filename, myFace);//存在当前目录下
imshow(filename, myFace);//显示下size后的脸
waitKey(500);//等待500us
destroyWindow(filename);//:销毁指定的窗口
pic_num++;//序号加1
if (pic_num == 11)
{
break;//当序号为11时退出循环
}
}
ShowMat(frame, GetDlgItem(IDC_SHOW)->GetSafeHwnd());
waitKey(30);
}
这部分程序的使用还要进行如下操作,先包含如下头文件,使用相应的命名空间以及建立一个全局变量。
#include 因为使用的是MFC的picture control显示,而我们所用的是OpenCV的Mat来定义图片变量,要想在picture control上显示出来需要做变换把Mat转换为合适的类型。网上用的最多的是已经消失在opencv3中的"Cvvimage.h"来完成,但是大多数都不好用,因此本文中采用的是在查询了多为大佬后的文章得到的一个方法建立了一个函数转换成CImage图来显示在picture中。(当然我们也可以通过opencv的一个函数的两次调用也能解决但不方便我们理解原理)
程序如下:
int Cface1Dlg::ShowMat(cv::Mat img, HWND hWndDisplay)
{
RECT rect;
::GetClientRect(hWndDisplay, &rect);
cv::Mat imgShow(abs(rect.top - rect.bottom), abs(rect.right - rect.left), CV_8UC3);
resize(img, imgShow, imgShow.size());
//在控件上显示要用到的CImage类图片
int w = imgShow.cols;//宽
int h = imgShow.rows;//高
int channels = imgShow.channels();//通道数
CI.Create(w, h, 8 * channels);
//CI像素的复制
uchar *pS;
uchar *pImg = (uchar *)CI.GetBits();//得到CImage数据区地址
int step = CI.GetPitch();
if (1 == channels)//调色板改变单通道灰度转化使得灰度图可以显示
{
RGBQUAD* rgbquadColorTable;
int nMaxColors = 256;
rgbquadColorTable = new RGBQUAD[nMaxColors];
CI.GetColorTable(0, nMaxColors, rgbquadColorTable);
for (int nColor = 0; nColor < nMaxColors; nColor++)
{
rgbquadColorTable[nColor].rgbBlue = (uchar)nColor;
rgbquadColorTable[nColor].rgbGreen = (uchar)nColor;
rgbquadColorTable[nColor].rgbRed = (uchar)nColor;
}
CI.SetColorTable(0, nMaxColors, rgbquadColorTable);
delete[]rgbquadColorTable;
}
for (int i = 0; i < h; i++)
{
pS = imgShow.ptr<uchar>(i);
for (int j = 0; j < w; j++)
{
if (1 == channels)
{
*(pImg + i* step + j) = pS[j];
}
else
if (3 == channels)
{
for (int k = 0; k < 3; k++)
*(pImg + i*step + j * 3 + k) = pS[j * 3 + k];
}
//注意到这里的step不用乘以3
}
}
//在控件显示图片
HDC dc;
dc = ::GetDC(hWndDisplay);
CI.Draw(dc, 0, 0);
::ReleaseDC(hWndDisplay, dc);
CI.Destroy();
return 0;
}
当然我们需要先再MFC界面这个类也就是Cface1Dlg.h中添加函数声明
int Cface1Dlg::ShowMat(cv::Mat img, HWND hWndDisplay);
然后准备部分的工作就完成了。
当然上述的按钮中添加的程序还包括了接下来说的数据预处理工作。
1.2数据预处理
在得到自己的人脸照片之后,还需要对这些照片进行一些预处理才能拿去训练模型。所谓预处理,其实就是检测并分割出人脸,并改变人脸的大小与下载的数据集中图片大小一致。
调用opencv训练好的分类器和自带的检测函数检测人脸人眼等的步骤简单直接:
1.加载分类器,当然分类器事先要放在工程目录中去。分类器本来的位置是在*\opencv\sources\data\haarcascades(harr分类器,也有其他的可以用,也可以自己训练)这个分类器的可以复制到MFC工程文件夹的目录中,或者直接复制他的路径调用。
2.调用detectMultiScale()函数检测,调整函数的参数可以使检测结果更加精确。
3.把检测到的人脸等用矩形(或者圆形等其他图形)画出来。
下图来自CSDN的博主快乐成长吧的博客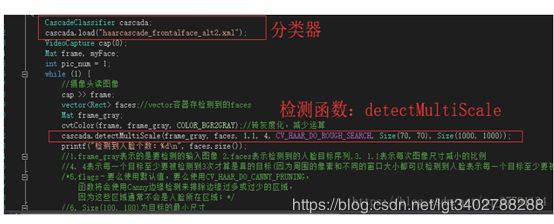
运行看看可以得到:

框上面的数字对应正在获得的图为第几张。
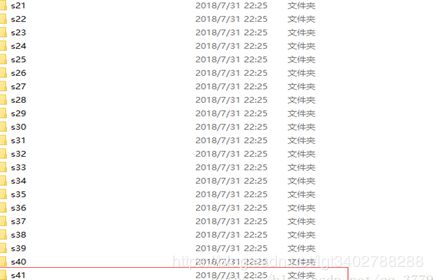
至此,我们就得到和ORL人脸数据库人脸大小一致的自己的人脸数据集。得到图能在工程文件夹中找到,然后我们把自己的作为第41个人,在我们下载的人脸文件夹下建立一个s41的子文件夹,把自己的人脸数据放进去。就成了这样下面这样,最后一个文件夹里面是我自己的头像照片:
(附本文学习时并未使用ORL数据集,只是按起样子自己准备了一些人物数据,因此并未达到40余人的数据集,这段话也是应引用博主快乐成长吧的博客)。
这里有一点值得注意:保存的图像格式是*.jpg的,而不是跟原数据集一样是*.pgm的。经测试仍然可以训练出可以正确识别我和其他准备识别的人脸的模型来。但是如果大小不一致会报错,所以大小:92*112。
1.3模型训练
模型训练也要做准备工作,首先我们要得到处理后数据集的csv文件,当我们写人脸模型的训练程序的时候,我们需要读取人脸和人脸对应的标签。直接在数据库中读取显然是低效的。所以我们用csv文件读取。csv文件中包含两方面的内容,一是每一张图片的位置所在,二是每一个人脸对应的标签,就是为每一个人编号。这个at.txt就是我们需要的csv文件。引用他人的图做介绍:
![]()
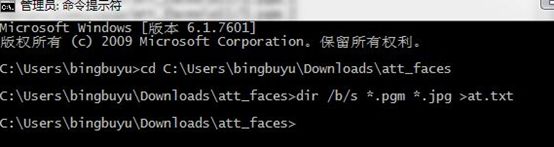
前面是图片的位置,后面是图片所属人脸的人的标签。对于大量的数据时,要生成这样一个文件直接用手工的方式一个一个输入显然不可取的,我们先利用cmd窗口,进入到存放我们的人脸数据的文件夹,然后利用输入:
dir /b/s *.pgm *.jpg >at.txt生成一个at.txt文件。图如下(引用他人图)
这个文件中只有路径但是没有标签,因此选择利用opencv的python脚本加标签。opencv教程里面为我们提供了自动生成csv文件的脚本。
路径类似这样:
\opencv345\opencv_contrib-3.4.5\modules\face\samples\etc\create_csv.py。
但是opencv_contrib-3.4.5这个属于拓展库需要自行去下载以及利用CMake添加生成。这里就不说明了。如果没安装我们也可以创建一个create_csv.py文件:程序如下:
import sys
import os.path
if __name__ == "__main__":
#if len(sys.argv) != 2:
# print ("usage: create_csv ")
# sys.exit(1)
BASE_PATH="数据集的路径"
SEPARATOR=";"
fh=open("数据集中at.txt的路径",'w')
label = 0
for dirname, dirnames, filenames in os.walk(BASE_PATH):
for subdirname in dirnames:
subject_path = os.path.join(dirname, subdirname)
for filename in os.listdir(subject_path):
abs_path = "%s/%s" % (subject_path, filename)
print ("%s%s%d" % (abs_path, SEPARATOR, label))
fh.write(abs_path)
fh.write(SEPARATOR)
fh.write(str(label))
fh.write("\n")
label = label + 1
fh.close
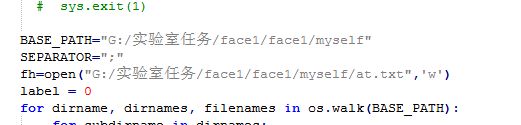
填写如图然后保存,我们安装了python3环境的话直接右键选择打开方式为python即可运行产生at.txt在对应的数据集的文件夹中。
接下来在准备工作完成后,开始训练模型。
在训练前我们要现在自己下载自己装的opencv对应的扩展库opencv_contrib否则无法使用opencv的人脸识别模型,因为现在的opencv功能愈发庞大愈发杂,因此都开始修改为opencv+扩展库两部分按需下载。这个可以搜索解决。
现在数据集、csv文件都已经准备好了。接下来要做的就是训练模型了。
这里我们用到了opencv的Facerecognizer类。opencv中所有的人脸识别模型都是来源于这个类,这个类为所有人脸识别算法提供了一种通用的接口。文档里的一个小段包含了我们接下来要用到的几个函数:

OpenCV 自带了三个人脸识别算法:Eigenfaces(特征脸),Fisherfaces 和局部二进制模式直方图 (LBPH)。先不深究算法。直接用。接下来就分别训练这三种人脸模型。Facerecognizer的强大是因为每一种模型的训练只需要三行代码:
我们可以新建立一个win32控制台程序专门做训练用,修改只要把at.txt的路径改成自己的即可,程序如下:
#include运行后,模型训练完,会测试三个模型,产生三个结果。借用大佬图:
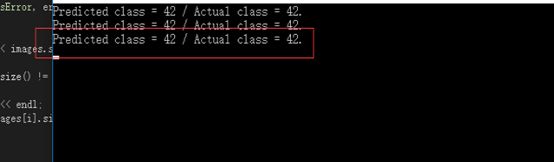
1.4人脸识别:
基本流程如下:
1.打开摄像头。
2.加载人脸检测器,加载人脸模型。
3.人脸检测
4.把检测到的人脸与人脸模型里面的对比,找出这是谁的脸。
5.如果人脸是自己拍照的人脸,显示自己的名字。
此处的代码我们在MFC对话框中的人脸识别按钮中加入,双击这份按钮进入响应函数中写代码。
对比如下的头文件和命名空间将没有的补充。
#include按钮中的代码如下:
VideoCapture cap(0); //打开默认摄像头
if (!cap.isOpened())
{
return ;
}
Mat frame;
Mat gray;
//这个分类器是人脸检测所用
CascadeClassifier cascade;
bool stop = false;
//训练好的文件名称,放置在可执行文件同目录下
cascade.load("haarcascade_frontalface_alt2.xml");//感觉用lbpcascade_frontalface效果没有它好,注意哈!要是正脸
model = FisherFaceRecognizer::create();
//1.加载训练好的分类器
model->read("G:\\实验室任务\\myface\\MyFaceFisherModel.xml");// opencv2用load
//3.利用摄像头采集人脸并识别
while (1)
{
cap >> frame;
vector<Rect> faces(0);//建立用于存放人脸的向量容器
cvtColor(frame, gray, CV_RGB2GRAY);//测试图像必须为灰度图
//gray=frame;
equalizeHist(gray, gray); //变换后的图像进行直方图均值化处理
//检测人脸
cascade.detectMultiScale(gray, faces,
1.1, 4, 0
//|CV_HAAR_FIND_BIGGEST_OBJECT
| CV_HAAR_DO_ROUGH_SEARCH,
//| CV_HAAR_SCALE_IMAGE,
Size(70, 70), Size(1000, 1000));
Mat* pImage_roi = new Mat[faces.size()]; //定以数组
Mat face;
Point text_lb;//文本写在的位置
//框出人脸
string str;
for (int i = 0; i < faces.size(); i++)
{
pImage_roi[i] = gray(faces[i]); //将所有的脸部保存起来
text_lb = Point(faces[i].x, faces[i].y);
if (pImage_roi[i].empty())
continue;
switch (Predict(pImage_roi[i])) //对每张脸都识别
{
case 0:str = "XXX",; break; //case后的数字调整为自己的人脸数据对应的标签号码。如标签为0,str对应相应的名字。
case 1:str = "XXX"; break;
case 2:str = "XXX"; break;
case 3:str = "XXX"; break;
default: str = "Error"; break;
}
Scalar color = Scalar(g_rng.uniform(0, 255), g_rng.uniform(0, 255), g_rng.uniform(0, 255));//所取的颜色任意值
rectangle(frame, Point(faces[i].x, faces[i].y), Point(faces[i].x + faces[i].width, faces[i].y + faces[i].height), color, 3, 8);//放入缓存
putText(frame, str, text_lb, FONT_HERSHEY_COMPLEX, 2, Scalar(0, 0, 255));//添加文字
}
delete[]pImage_roi;
ShowMat(frame, GetDlgItem(IDC_SHOW2)->GetSafeHwnd());
waitKey(200);
}
最后结果如图:

2、原理
参考:基于OpenCV3实现人脸识别(原理篇)