Spiking-YOLO : 前沿性研究,脉冲神经网络在目标检测的首次尝试 | AAAI 2020
论文提出Spiking-YOLO,是脉冲神经网络在目标检测领域的首次成功尝试,实现了与卷积神经网络相当的性能,而能源消耗极低。论文内容新颖,比较前沿,推荐给大家阅读
来源:晓飞的算法工程笔记 公众号
论文: Spiking-YOLO: Spiking Neural Network for Energy-Efficient Object Detection

- 论文地址:http://arxiv.org/abs/1903.06530
Introduction
脉冲神经网络(Spiking neural network, SNN)将脉冲神经元作为计算单元,能够模仿人类大脑的信息编码和处理过程。不同于CNN使用具体的值(continuous)进行信息传递,SNN通过脉冲序列(discrete)中每个脉冲发射时间(temporal)进行信息的传递,能够提供稀疏但强大的计算能力。脉冲神经元将输入累积到膜电压,当达到具体阈值时进行脉冲发射,能够进行事件驱动式计算。由于脉冲事件的稀疏性以及事件驱动的计算形式,SNN能提供卓越的能源利用效率,是神经形态结构的首选神经网络
尽管SNN有很多好处,但目前仅能处理相对简单的任务,由于神经元复杂的动态性以及不可导的操作,暂时没有一个可扩展的训练方法。DNN-to-SNN是近期广泛的SNN训练方法,该方法将目标DNN转化成SNN的中间DNN网络进行训练,然后转成SNN并复用其训练的参数,在小数据集分类上能达到不错的性能,但是在大数据集上分类结果不太理想
论文打算使用DNN-to-SNN转化方法将SNN应用到更复杂的目标检测领域中,图片分类只需要选择分类就好,而目标检测则需要神经网络进行高度准确的数字预测,难很多。在深入分析后,论文实现YOLO的转换主要面临以下两个问题:
- 常用的SNN归一化方法过于低效,导致脉冲发射频率过低。由于SNN需要设定阈值进行脉冲发射,所以要对权值进行归一化,这样有利于阈值的设定,而常用的SNN归一化方法在目标检测中显得过于低效,后面会详细阐述
- 在SNN领域,没有高效leaky-ReLU的实现,因为要将YOLO转换为SNN,YOLO中包含大量leaky-ReLU,这是很重要的结构,但目前还没有高效的转换方法
为此,论文使用channel-wise归一化(Channel-wise normalization)和阈值不平衡的有符号神经元(signed neuron with imbalanced threshold)来分别解决以上问题,搭建了基于SNN的目标检测模型Spiking-YOLO,论文的贡献总结如下:
- 深度SNN在目标检测领域的第一次尝试
- channel-wise归一化,深度SNN的细粒度归一化方法,使得多个神经元更高但仍然合适的频率发射脉冲,进而让SNN信息传递更快且更准确
- 阈值不平衡的有符号神经元,提出leaky-ReLU在SNN领域的高效实现,在神经芯片上也能够轻量级集成
SNN神经元简述

SNN使用脉冲序列进行神经元间的信息传递,IF(integrate-and-fire)神经元累积输入 z z z到膜电压 V m e m V_{mem} Vmem

第 l l l层的第 j j j个神经元的膜电压计算如公式1, Θ j l ( t ) \Theta_j^l(t) Θjl(t)为脉冲, V t h V_{th} Vth为临界电压, z k l ( t ) z_k^l(t) zkl(t)为神经元的输入
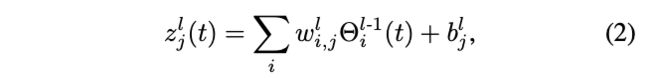
z k l ( t ) z_k^l(t) zkl(t)由多个输入累加, w w w和 b b b为权重和偏置

当膜电压 V m e m V_{mem} Vmem大于临界电压 V t h V_{th} Vth时产生脉冲 Θ \Theta Θ, U U U为单位阶跃函数(unit step function),满足输出1,不满足则输出0。由于SNN是事件驱动的,能源利用率相当高,但难以训练是SNN在所有应用上的主要障碍
Methods
论文直接使用DNN-to-SNN转换方法将SNN应用到目标检测中,发现性能下降得十分严重,在分析性能下降原因后,得出两个主要原因:a) 大量神经元的脉冲发射频率过低 b) SNN缺少leaky-ReLU的高效实现
Channel-wise data-based normalization
-
Conventional normalization methods
在SNN中,根据输入的幅度产生脉冲序列进行无损的内容传递是极为重要的。但在固定时间,激活过度或激活不足的神经元内将可能导致内容损失,这和临界电压 V t h V_{th} Vth的设置有关。设置过高,神经元需要累积很长时间的电压才能发射脉冲,相反则会过多地发射脉冲。发射频率通常定义为 N T \frac{N}{T} TN, N N N为 T T T个timestep的脉冲发射总数,最大的发射率为100%,即每个timestep都发射脉冲

为了防止神经元的激活过度和激活不足,权值和临界电压都需要精心地选择。为此,很多研究提出了归一化的方法,比如常用的Layer-wise normalization(layer-norm)。该方法通过该层的最大化激活值来归一化层的权值,如公式4, w w w和 b b b为权重, λ \lambda λ为输出特征图最大值。经过归一化后,神经元的输出就归一到 [ 0 , 1 ] [0,1] [0,1],方便设定临界电压。由于最大激活值 λ \lambda λ从训练集得到的,所以测试集和训练集需要有相同的分布,但论文实验发现这种常规的归一化方法在目标检测任务上会导致明显的性能下降
-
Analysis of layer-norm limitation
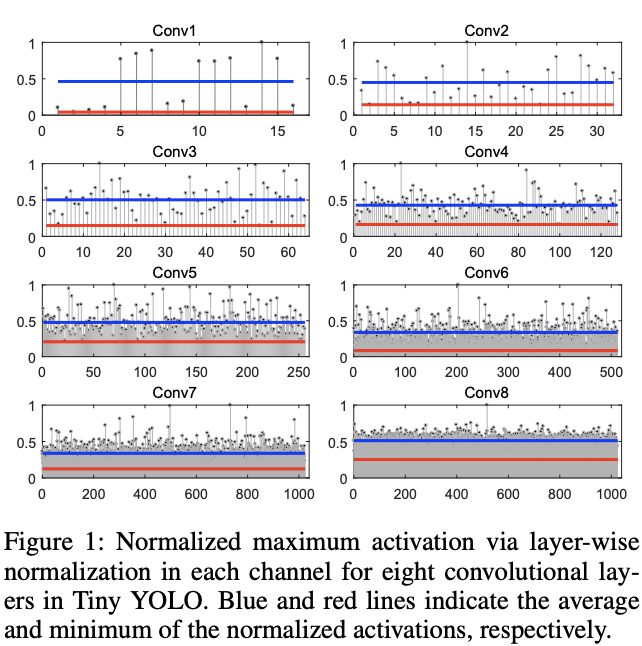
图1展示了通过layer-norm后的各层每个channel的最大激活值,蓝色和红色的线分别为每层的平均激活值和最小激活值。可以看到每层的归一化后的激活值偏差较大,总体而言,layer-norm使得神经元的channel偏向激活不足,这在仅需选择分类的图片分类任务是不被察觉的,但对于需要预测准确值的检测任务的回归则不一样。比如传递0.7,则需要在10个timestep脉冲7次,0.007则需要在1000timestep脉冲7次。当tempstep本身就很少时,过低的发射率可能会因发射不到足够的脉冲而导致信息丢失
-
Proposed normalization method
论文提出更细力度的归一化方法,channel-wise normalization(channel-norm),该方法在每层的channel维度上,使用最大激活值对权值进行归一化

channel-wise归一化方法如公式5, i i i和 j j j为维度下标, l l l层权值 w w w通过在每个channel使用最大激活值 λ j l \lambda_j^l λjl进行归一化,该值依然是从训练集计算的。对于非首层中,归一化的激活值必须乘上 λ i l − 1 \lambda_i^{l-1} λil−1来将输入还原为上一层归一化前的值,再进行本层的归一化,不然传递的信息会越来越小


具体的逻辑如图2和算法1,channel-wise的归一化方法能够消除激活值特别小的问题,即得到更高但合适的发射频率,在短时间内也能准确地传递信息
-
Analysis of the improved firing rate

如图3所示,对于channel-norm,大多数的神经元能接近80%的发射率,而对于layer-norm,大多数的神经元的发射率在0到3.5%之间,这明显表明channel-norm避免了过小的激活值使得更多神经发射频率更高且合适

另外从图4可以看出,channel-norm在大多数的channel上能产生更高的发射频率,特别在channel 2
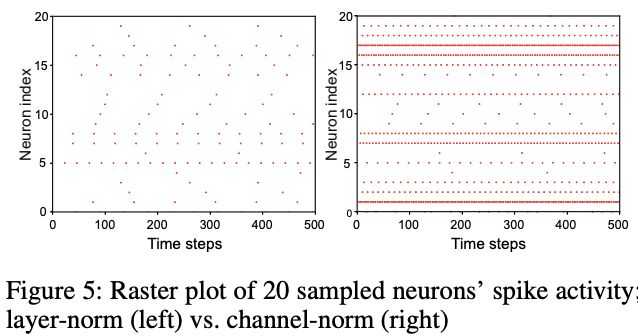
图5则随机采样了20个神经元,记录其脉冲活动,使用channel-norm使得大多数神经元能够更有规律地发射脉冲
从上面的分析可以看出,channle-norm能够避免过小的归一化激活值,从而保持较高的脉冲发射频率,使得神经元能够在短时间内准确地传递信息,是深度SNN在解决更高级的机器学习问题的一种可行解决方案
Signed neuron featuring imbalanced threshold
-
Limitation of leaky-ReLU implementation in SNNs
ReLU是最常用的激活函数,保留正值而去掉所有的负值,目前的DNN-to-SNN方法都专注于IF神经元与ReLU间的转换,忽略了激活函数中的负值,而在Tiny-YOLO中,负值激活占了51%。leaky-ReLU是目前最常用的激活,通过leakage项来保留负值 f ( x ) = α x f(x)=\alpha x f(x)=αx, α \alpha α一般为0.01,但目前还没有准确且高效的SNN实现方法。此前有研究提出负临界电压(-1),使得可以存在正负激活,然后在这基础乘以 α \alpha α来转换leaky-ReLU,但这违背了生物学(脉冲是离散信号),而在神经芯片上也需额外的模块进行浮点运算
-
The notion of imbalanced threshold
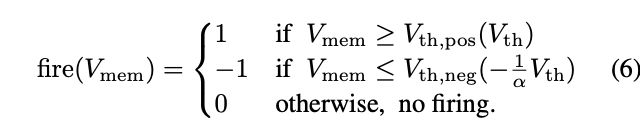
论文提出阈值不平衡的有符号神经元(IBT),在负值区域使用临界电压 V t h , n e g = − V t h α V_{th,neg}=-\frac{V_{th}}{\alpha} Vth,neg=−αVth,不仅可以传递正负激活值,保持离散型,还可以高效和准确地仿照leaky-ReLU的leakage项

如图6所示,假设 V t h , p o s = 1 V V_{th,pos}=1V Vth,pos=1V,在 α = 0.1 \alpha=0.1 α=0.1时, V t h , n e g = − 10 V V_{th,neg}=-10V Vth,neg=−10V,膜电压需要积累多10倍来发射负激活,类似于leaky-ReLU
Evaluation
Spiking-YOLO detection results
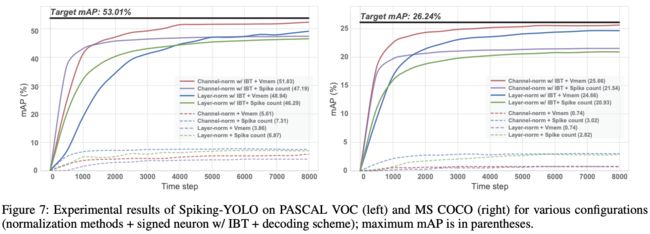
实验的目的是无损地将Tiny-YOLO的转移为SNN,结果如图7所示,使用channel-norm和IBT能有效地提升性能,且使用的timestep更少

论文尝试了不同的解码方式,分别为膜电压 V m e m V_{mem} Vmem和脉冲数 V m e m / V t h V_{mem}/V_{th} Vmem/Vth,由于脉冲数的余数要舍弃,这会带来误差和信息损失,所以基于膜电压进行解压会更准确

Spiking-YOLO energy efficiency
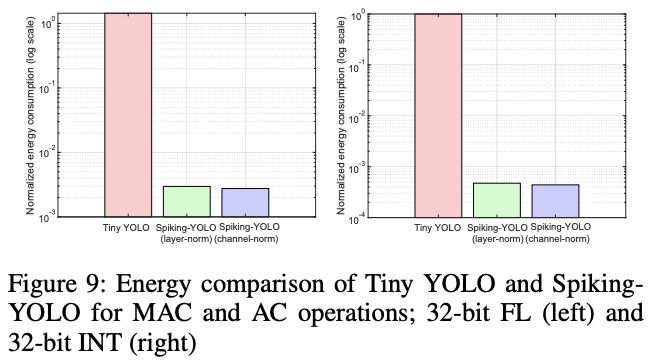
DNN主要使用相乘累积(multiply-accumulate , MAC)操作,而SNN则主要是累积操作(accumulate, AC),因为脉冲是二值的(1或-1),当接受到脉冲时,不用实时乘权重就可以知道结果。32-bit浮点型MAC和AC分别需要3.6pJ和0.9pJ,而32-bit整数型MAC和AC分别为3.2pJ和0.1pJ。如图9所示,不管使用哪种归一化方法,Spiking-YOLO的计算耗能仅为Tiny-YOLO的1/2000倍,能源利用十分高效

论文在实际设备上对比了Spiking-YOLO(TrueNorth chip)和Tiny-YOLO(Titan V100),因为channel-norm的发射率较高且合适,所以使用了更少的timestep,能源消耗最少
Conclusion
论文提出Spiking-YOLO,是脉冲神经网络在目标检测领域的首次成功尝试,实现了与卷积神经网络相当的性能,而能源消耗极低。论文内容新颖,比较前沿,推荐给大家阅读
参考内容
- Towards spike-based machine intelligence with neuromorphic computing (http://www.nature.com/articles/s41586-019-1677-2)
- Spiking Deep Convolutional Neural Networks for Energy-Efficient Object Recognition (http://link.springer.com/article/10.1007/s11263-014-0788-3)
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
