jvm调优实战笔记之基础知识简介
jvm调优实战笔记之基础知识简介
I. 背景
java后端,提供了一个svg渲染的服务,在qps较大时,会出现频繁的gc,而此时的服务器性能本身并没有达到瓶颈(cpu,load,io都不太高)因此考虑调整一下jvm的相关参数,看是否可以提升服务性能
jvm相关参数记录
-XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:CMSMaxAbortablePrecleanTime=5000 -XX:+CMSParallelRemarkEnabled -XX:+CMSScavengeBef
oreRemark -XX:+ExplicitGCInvokesConcurrent -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/xxx/java.hprof -XX:InitialCodeCacheSize=134217728 -XX:InitialHeapSize=4294967296 -XX:MaxDirectMemorySize=1073741824 -XX:MaxHeapSize=4294967296 -XX:MaxMetaspaceSize=268435456 -XX:MaxNewSize=2147483648 -XX:MetaspaceSize=268435456 -XX:NewSize=2147483648 -XX:OldPLABSize=16 -XX:+PrintGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:ReservedCodeCacheSize=268435456 -XX:SurvivorRatio=10 -XX:+UseCMSCompactAtFullCollection -XX:+UseCMSInitiatingOccupancyOnly -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseParNewGC2. 监控工具
使用tsar作为服务器性能监控工具,所以前提是先安装tsar
wget -O tsar.zip https://github.com/alibaba/tsar/archive/master.zip --no-check-certificate
unzip tsar.zip
cd tsar
make
make install监控命令
tsar --cpu --swap -i1 -l说明
tsar相关可以参考: Linux系统性能监控工具介绍之-tsar
II. 相关知识点简介
截取几条gc日志
2018-01-02T10:49:20.390+0800: 9.015: [GC (Allocation Failure) 2018-01-02T10:49:20.390+0800: 9.015: [ParNew: 1922431K->134118K(1922432K), 0.1486593 secs] 1934749K->201350K(4019584K), 0.1487460 secs] [Times: user=0.33 sys=0.05, real=0.14 secs]
2018-01-02T10:49:25.374+0800: 13.999: [GC (Allocation Failure) 2018-01-02T10:49:25.374+0800: 13.999: [ParNew: 1881830K->93708K(1922432K), 0.0910714 secs] 1949062K->197949K(4019584K), 0.0911833 secs] [Times: user=0.26 sys=0.01, real=0.09 secs]
2018-01-02T10:55:53.013+0800: 401.639: [GC (GCLocker Initiated GC) 2018-01-02T10:55:53.013+0800: 401.639: [ParNew: 1841429K->142552K(1922432K), 0.0629031 secs] 1945670K->246793K(4019584K), 0.0630512 secs] [Times: user=0.14 sys=0.01, real=0.06 secs]
2018-01-02T10:55:55.076+0800: 403.701: [GC (GCLocker Initiated GC) 2018-01-02T10:55:55.076+0800: 403.701: [ParNew: 1890281K->59983K(1922432K), 0.0661778 secs] 1994522K->201875K(4019584K), 0.0663176 secs] [Times: user=0.15 sys=0.01, real=0.07 secs]
2018-01-02T11:47:25.271+0800: 3493.897: [GC (Allocation Failure) 2018-01-02T11:47:25.271+0800: 3493.897: [ParNew: 1807695K->20975K(1922432K), 0.0193077 secs] 1949587K->162867K(4019584K), 0.0195351 secs] [Times: user=0.04 sys=0.00, real=0.02 secs]
2018-01-02T11:56:50.621+0800: 4059.247: [GC (GCLocker Initiated GC) 2018-01-02T11:56:50.622+0800: 4059.247: [ParNew: 1774543K->108899K(1922432K), 0.0401606 secs] 1916434K->250791K(4019584K), 0.0403586 secs] [Times: user=0.10 sys=0.00, real=0.04 secs]1. CMS GC日志格式分析
截取上面日志中的第一条,分别说明每一项是什么意思
2018-01-02T10:49:20.390+0800: 9.015: [GC (Allocation Failure) 2018-01-02T10:49:20.390+0800: 9.015: [ParNew: 1922431K->134118K(1922432K), 0.1486593 secs] 1934749K->201350K(4019584K), 0.1487460 secs] [Times: user=0.33 sys=0.05, real=0.14 secs]
- 2018-01-02T10:49:20.390+0800 :发生gc的时间
- 9.015 - GC开始,相对JVM启动的相对时间,单位是秒
- GC - 区别FullGC和MinorGC的标识,此处表示为MinorGC
- (Allocation Failure) - 发生gc的原因,此处表示空间不足,导致分配失败
- ParNew – 收集器的名称,它预示了年轻代使用一个并行的 mark-copy stop-the-world 垃圾收集器
- 1922431K->134118K – 收集前后年轻代的使用情况,未回收之前,大小为1922431K, 回收完毕之后,大小为134118K, 所以回收大小为: 1922431K - 134118K
- (1922432K) - 整个年轻代的容量
- 0.1486593 secs - 这个解释用原滋原味的解释:Duration for the collection w/o final cleanup.
- 1934749K->201350K - 收集前后整个堆的使用情况
- (4019584K) - 整个堆的容量
- 0.1487460 secs – ParNew收集器标记和复制年轻代活着的对象所花费的时间(包括和老年代通信的开销、对象晋升到老年代时间、垃圾收集周期结束一些最后的清理对象等的花销);
- [Times: user=0.78 sys=0.01, real=0.11 secs] – GC事件在不同维度的耗时,具体的用英文解释起来更加合理:
- user – Total CPU time that was consumed by Garbage Collector threads during this collection
- sys – Time spent in OS calls or waiting for system event
- real – Clock time for which your application was stopped. With Parallel GC this number should be close to (user time + system time) divided by the number of threads used by the Garbage Collector. In this particular case 8 threads were used. Note that due to some activities not being parallelizable, it always exceeds the ratio by a certain amount.
2. CMS简介
后端服务选用的就是CMS,那么就有必要看一下这个CMS到底是个什么东西
CMS
Concurrent Mark Sweep 收集器,是一种以获取最短回收停顿时间为目标的收集器,核心就是标签-清除算法
步骤划分
- 初始标记 (CMS initial mark) : 标记GC Roots能直接关联到的对象,速度很快,会暂停
- 并发标记 (CMS concurrent mark) : 进行 GC Roots Tracing的过程
- 重新标记 (CMS remark) : 为了修正并发标记期间,因为程序继续运作导致标记变动的那一部分对象的标记记录,一般会长于初始标记时间,远小于并发标记的时间
- 并发清除 (CMS concurrent sweep) :
说明,初始标记和重新标记的时候,会暂停服务;后面两个则是并发修改
标记清除算法
一句话描述:
标记所有需要回收的对象,在标记完成后,统一回收所有被标记的对象
常见的两个问题: 效率不高;回收后大量的碎片
3. 内存分配和回收策略
a. 对象优先在Eden分配
大多数场景下,对象在新生代Eden区分配,当Eden去没有足够的空间进行分配时,虚拟机发起一次 Minor GC
- 新生代MinorGC : 发生在新生代的垃圾收集动作,因为java对象大多都具备朝生夕灭的特性是,所以一般MinorGC非常频繁,一般回收速度也很快
- 老年代MajorGC(FullGC) : 发生在老年代的GC,通常就伴随至少一次的MinorGC(非绝对),一般较慢,是MinorGC的十倍以上
b. 大对象直接进入老年代
需要大量连续内存空间的Java对象,通常是数组,同构 -XX:PretenuresizeThreshold 参数,来设置大对象的阀值,超过这个阀值的直接分配在年老代,避免在Eden区及两个Survivor区指尖发生大量的内存复制
c. 长期存活的对象将进入老年代
既然虚拟机采用分代收集的思想来管理内存,在回收时,就必须能识别哪些对象应放在新生代,那些对象应放在老年代中
每个对象都有个Age的计数器,对象在Eden出生并经过第一次MinorGC后仍存在,且可以被Survivor容纳的话,会被移动到Survivor空间中,并设置Age为1
对象在Survivor区没多经过一次MinorGC,则age+1
当age超过阀值(默认15),就会晋升到老年代
阀值可以通过 -XX:MaxTenuringThreshold来设置
d. 动态对象年龄判定
如果在Survivor空间中相同年龄所有对象的大小的总和,大于Survivor空间的一半,则年龄大于或等于该年龄的对象就可以进入老年代,无序等Age达到阀值
e. 空间分配担保
在发生MinorGC之前,虚拟机会先检查老年代最大可用的连续空间是否大于新生代所有对象总空间,如果成立,则Minor GC可以确保总是安全的;
否则,查看 HandlePromotionFailure参数,是否允许担保失败
若允许,则继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,若大于,则尝试MinorGC
否则进行FullGC
3. jstat 命令简介
既然问题是频繁的gc引起的,那么观察新生代,老年代对象占用空间的情况就不可避免了,所以jstat命令不得不出现了
截一个线程图
$ jstat -gcutil 11573 1000 5
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 34.39 24.68 68.01 98.12 96.30 3051 170.096 242 18.429 188.525
0.00 34.39 26.29 68.01 98.12 96.30 3051 170.096 242 18.429 188.525
0.00 34.39 27.45 68.01 98.12 96.30 3051 170.096 242 18.429 188.525
0.00 34.39 28.32 68.01 98.12 96.30 3051 170.096 242 18.429 188.525
0.00 34.39 29.93 68.01 98.12 96.30 3051 170.096 242 18.429 188.525a. 参数说明
- -gcutil : 监视Java对状况,包括Eden区、两个survivor区,老年代,永久代等,已用空间,gc时间等
- 11573: java进程号
- 1000: 每1s刷新一次
- 5: 一共查询5次
b. 输出说明
- S0, S1: 表示两个 survivor区
- E(Eden) : 新生代Eden
- O(Old) : 老年代Old
- M(metaspace) : 元空间,本地内存, 在1.8移除了永久代改成这个
- YGC : 程序运行以来,发生Minor GC(Young GC)次数
- YGCT : Minor GC 总耗时(单位s)
- FGC : Full GC的总次数
- FGCT : Full GC的总耗时 (单位s)
- GCT : 所有GC的总耗时 (单位s)
III. 监控测试
0. 准备
a. 首先是获取对应的进程号
jps -l
jinfo xxx抓图
$ jps -l
30916 sun.tools.jps.Jps
2909 org.apache.catalina.startup.Bootstrapb. 服务器性能监控命令
## 主要查看cpu和nginx访问的监控
tsar --cpu --nginx -i1 -l抓图:
Time -----------------------cpu---------------------- ----------------------------------nginx---------------------------------
Time user sys wait hirq sirq util accept handle reqs active read write wait qps rt
03/01/18-11:29:37 16.54 1.50 0.00 0.00 0.00 18.05 2.00 2.00 6.00 15.00 0.00 1.00 14.00 6.00 89.50
03/01/18-11:29:38 26.07 1.75 0.00 0.00 0.00 27.82 3.00 3.00 10.00 15.00 0.00 1.00 14.00 10.00 47.10
03/01/18-11:29:39 19.60 1.01 0.00 0.00 0.00 20.60 4.00 4.00 11.00 15.00 0.00 1.00 14.00 11.00 37.82
03/01/18-11:29:40 28.75 2.50 0.00 0.00 0.25 31.50 2.00 2.00 10.00 15.00 0.00 1.00 14.00 10.00 79.30
03/01/18-11:29:41 14.07 1.51 0.00 0.00 0.00 15.58 1.00 1.00 10.00 15.00 0.00 3.00 12.00 10.00 51.30
03/01/18-11:29:42 20.60 1.01 0.00 0.00 0.00 21.61 6.00 6.00 13.00 15.00 0.00 1.00 14.00 13.00 44.69c. jvm内存的监控
jstat -gcutil 4354 1000抓图:
$ jstat -gcutil 2909 1000
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
29.03 0.00 66.34 16.34 98.57 96.32 200 6.393 0 0.000 6.393
29.03 0.00 66.37 16.34 98.57 96.32 200 6.393 0 0.000 6.393
29.03 0.00 66.50 16.34 98.57 96.32 200 6.393 0 0.000 6.393
29.03 0.00 66.54 16.34 98.57 96.32 200 6.393 0 0.000 6.393d. 查看内存中对象的个数和大小
jmap -histo 4354抓图
num #instances #bytes class name
----------------------------------------------
1: 78179 181546608 [I
2: 1259 175880312 [S
3: 35915 65527520 [B
4: 242125 40558408 [C
5: 571604 13718496 java.util.concurrent.atomic.AtomicLong
6: 233282 5598768 java.lang.String
7: 55177 5296992 java.util.jar.JarFile$JarFileEntry
8: 119906 3836992 java.util.HashMap$Node
9: 33327 2932776 java.lang.reflect.Method
10: 1147 2303216 [Ljava.util.concurrent.atomic.AtomicLong;e. 压测模拟工具
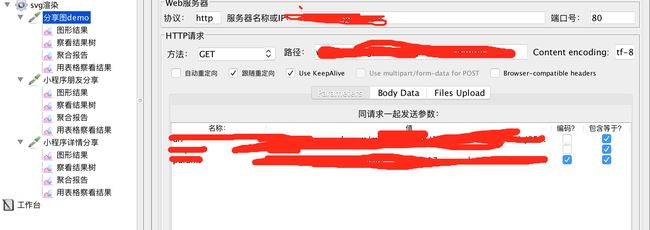
Jmetter
- 添加线程组
- 新增http请求
- 添加监听器中,结果的监控:图形结果,聚合报告,查看结果树,用表格查看结果
- http请求中配置参数
- 协议
- 域名or IP + 端口号
- 编码: utf-8
- 请求方法 + 请求路径
- 请求参数,支持文件上传,注意编码方式
IV. 参考
- Linux系统性能监控工具介绍之-tsar
- tsar使用说明
- JVM调优——之CMS GC日志分析
- jvm的GC日志分析
- JVM 运行时内存使用情况监控
- 《深入理解JVM虚拟机》
V. 其他
声明
尽信书则不如,已上内容,纯属一家之言,因本人能力一般,见解不全,如有问题,欢迎批评指正
扫描关注,java分享