Ubuntu16.04下 tensorflow1.60安装
本方法是通过Anaconda安装tensorflow.
Ubuntu16.04 + python3.5 + tensorflow1.6 + cuda9.0 + cuDNN7.0 + Anaconda3-5.1.0 + nvidia384 + GeForce GTX 1060 3GB
几个注意事项。
由于安装tensorflow需要安装cuda,cuDNN,所以需要注意之间的版本对应关系,事先在tensorflow的github中的release note中查询,网址为https://github.com/tensorflow/tensorflow/releases
不要装太新的,要装稳定的组合,python3.6下的tensorflow1.60一直出错,包也装里,conda list里也有tensorflow-gpu,可是import tensorflow时一直出错,无语。。。
版本判断
cuda_9.0.176_384.81_linux.run # cuda 9.0 nvidia驱动 384
cudnn-9.0-linux-x64-v7.tgz # 与cuda 9.0对应的cudnn 7.0
https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.6.0-cp35-cp35m-linux_x86_64.whl #python 3.5
安装nvidia驱动程序
-
禁用系统默认的集成驱动,倘若安装过nvidia驱动可以跳过
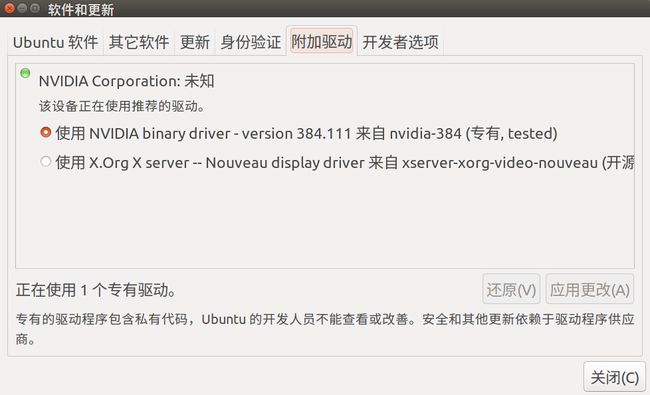 2018-03-13 16-21-14屏幕截图.png
2018-03-13 16-21-14屏幕截图.png
上图是安装nvidia驱动后的状态,如果是驱动是第二个则需要进行此步骤
Ubuntu系统集成的显卡驱动程序是nouveau,它是第三方为NVIDIA开发的开源驱动,我们需要先将其屏蔽才能安装NVIDIA官方驱动。
将驱动添加到黑名单blacklist.conf中,但是由于该文件的属性不允许修改。所以需要先修改文件属性。
查看属性
$sudo ls -lh /etc/modprobe.d/blacklist.conf
修改属性
$sudo chmod 666 /etc/modprobe.d/blacklist.conf
用gedit打开
$sudo gedit /etc/modprobe.d/blacklist.conf
在该文件后添加以下几行:
blacklist vga16fb
blacklist nouveau
blacklist rivafb
blacklist rivatv
blacklist nvidiafb
- 开始安装
卸载已有nvidia驱动,在终端中运行:
sudo apt-get remove --purge nvidia*
卸载完成后,按Ctrl+Alt+F1进入命令行模式,关闭图形系统
$sudo service lightdm stop
安装N卡驱动程序(我的显卡推荐的是nvidia-384) ,从 系统设置->软件更新->附加驱动 查看
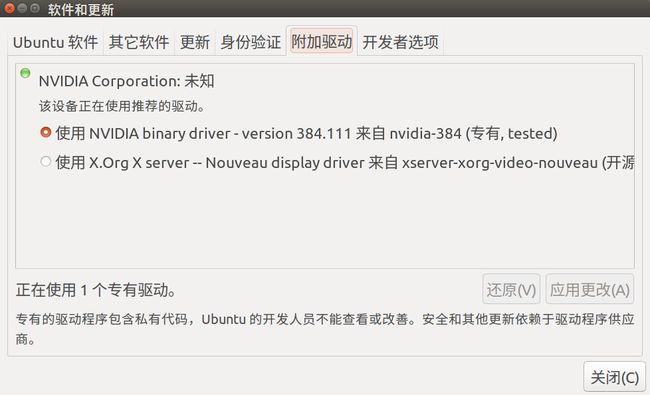
$sudo apt-get install nvidia-384
安装完成后,启动图形系统
$sudo service lightdm start
上面的命令执行后会自动转到图形界面,因为之前Ubuntu系统集成的显卡驱动程序nouveau被禁用了,这时候可能无法显示图形界面,此时再按下Ctrl+Alt+F1进入命令行模式,输入reboot 重启计算机即可。
通过 nvidia-smi 查看是否成功安装,如果正确,会输出类似以下的信息
(tensorflow) ajm@ajm-zju:~$ nvidia-smi
Tue Mar 13 13:21:14 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.111 Driver Version: 384.111 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 106... Off | 00000000:01:00.0 On | N/A |
| 27% 27C P8 9W / 120W | 408MiB / 3012MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1074 G /usr/lib/xorg/Xorg 151MiB |
| 0 1933 G compiz 138MiB |
| 0 2071 G fcitx-qimpanel 9MiB |
| 0 2359 G ...-token=F8442C0855613A1C9ED488250D0EE24D 107MiB |
+-----------------------------------------------------------------------------+
安装cuda
在https://developer.nvidia.com/cuda-downloads里选择机器环境后下载runfile(local)文件
切换到相应目录,在终端中运行
sudo sh cuda_9.0.176_384.81_linux.run
在询问是否安装Nvidia驱动时,由于前一步已经安装好了驱动,选择no,最后会报错没有Nvidia drivers,但这没有关系。其余的问题都是yes
安装完成后需要添加环境变量
网上推荐的方法大都如下
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64$LD_LIBRARY_PATH
并通过 source /etc/profile生效
但是,这种方法只是临时设置,电脑重启等情况下又会失效,所以永久设置的方法如下:
sudo gedit /etc/profile #对所有用户永久设置
#在文件末尾加上以下两行
export PATH="$PATH:/usr/local/cuda/bin" #以:分隔,注意如果原来已经有这一行,则将:/usr/local/cuda/bin添加到后面
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda-9.0/lib64"
并通过
source /etc/profile
生效,否则需重启才能生效
测试是否成功安装:
cd /usr/local/cuda/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
若成功安装,会输出类似以下的信息
(tensorflow) ajm@ajm-zju:/usr/local/cuda/samples/1_Utilities/deviceQuery$ ./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GTX 1060 3GB"
CUDA Driver Version / Runtime Version 9.0 / 9.0
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 3013 MBytes (3158900736 bytes)
( 9) Multiprocessors, (128) CUDA Cores/MP: 1152 CUDA Cores
GPU Max Clock rate: 1734 MHz (1.73 GHz)
Memory Clock rate: 4004 Mhz
Memory Bus Width: 192-bit
L2 Cache Size: 1572864 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 9.0, CUDA Runtime Version = 9.0, NumDevs = 1
Result = PASS
安装cuDNN
在https://developer.nvidia.com/cudnn内点击download,需要注册并登录后才可以下载cuDNN的包,这里下载的是cuDNN v7.1.1 Library for Linux
在终端中,解压下好的cuDNN包:
tar -xvf cudnn-9.0-linux-x64-v7.tgz
接下来只需把头文件和库文件加入到安装的cuda目录下:
sudo cp cuda/include/cudnn.h /usr/local/cuda/include/
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn.h //对所有用户加上读取权限
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*
cuDNN安装完毕
安装Anaconda
- 下载
通过 https://www.anaconda.com/download/#linux选择需要的Anaconda版本,下载安装包,也可以在清华大学Anaconda下载,本文下载的是 Anaconda3-5.1.0-Linux-x86_64.sh
- 安装
# 切换到软件包的目录下
bash Anaconda3-5.1.0-Linux-x86_64.sh
- 添加清华镜像
因为国外网址访问可能会很慢,可以在conda配置文件添加清华镜像网址清华大学Anaconda 镜像,配置如下
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes
并通过
gedit ~/.condarc
删除 default那一行
通过Anaconda安装tensorflow
通过conda命令添加tensorflow运行环境
# 我装的时候 python3.6环境下一直有问题,所以选择python3.5
$ conda create -n tensorflow python=3.5 # or python=3.3,2.7 ...
通过一下命令激活该运行环境
$ source activate tensorflow
接着安装tensorflow:
(tensorflow)$ pip install --ignore-installed --upgrade tfBinaryURL
其中 tfBinaryURL 是需要安装的tensorflow 对应的URL.例如 https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.6.0-cp35-cp35m-linux_x86_64.whl
测试是否安装成功
- 安装完成后,需要运行一小段tensorflow脚本来测试安装是否正确。Tensorflow的官方教程里给出了两个阶段的测试,第一个是hello world性质的:
$ python
>>> import tensorflow as tf
>>> hello = tf.constant('Hello, TensorFlow!')
>>> sess = tf.Session()
>>> print(sess.run(hello))
Hello, TensorFlow!
>>> a = tf.constant(10)
>>> b = tf.constant(32)
>>> print(sess.run(a + b))
42
>>>
倘若出现以下错误
ImportError: libcublas.so.9.0: cannot open shared object file: No such file or directory
说明读取libcublas.so.9.0库文件错误,之前的LD_LIBRARY_PATH环境变量没有设置正确,通过
echo $PATH
echo $LD_LIBRARY_PATH
可以查看环境变量是否设置正确
- 运行CNN卷积神经网络,MNIST手写数字识别代码
代码来自zouxy09 Deep Learning-TensorFlow (1) CNN卷积神经网络_MNIST手写数字识别代码实现
# -*- coding: utf-8 -*-
import time
import tensorflow.examples.tutorials.mnist.input_data as input_data
import tensorflow as tf
'''''
权重w和偏置b
初始化为一个接近0的很小的正数
'''
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev = 0.1) # 截断正态分布
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape) # 常量0.1
return tf.Variable(initial)
'''''
卷积和池化,卷积步长为1(stride size),0边距(padding size)
池化用简单传统的2x2大小的模板max pooling
'''
def conv2d(x, W):
# strides[1,,,1]默认为1,中间两位为size,padding same为0,保证输入输出大小一致
return tf.nn.conv2d(x, W, strides=[1,1,1,1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1,2,2,1],
strides=[1,2,2,1], padding='SAME')
# 计算开始时间
start = time.clock()
# MNIST数据输入
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# 图像输入输出向量
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None,10])
# 第一层,由一个卷积层加一个maxpooling层
# 卷积核的大小为5x5,个数为32
# 卷积核张量形状是[5, 5, 1, 32],对应size,输入通道为1,输出通道为32
# 每一个输出通道都有一个对应的偏置量
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
# 把x变成一个4d向量,其第2、第3维对应图片的宽、高,最后一维代表图片的颜色通道数
x_image = tf.reshape(x, [-1, 28, 28, 1]) # -1代表None
# x_image权重向量卷积,加上偏置项,之后应用ReLU函数,之后进行max_polling
h_conv1 = tf.nn.relu(conv2d(x_image,W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# 第二层,结构不变,输入32个通道,输出64个通道
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# 全连接层
'''''
图片尺寸变为7x7(28/2/2=7),加入有1024个神经元的全连接层,把池化层输出张量reshape成向量
乘上权重矩阵,加上偏置,然后进行ReLU
'''
W_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# Dropout,用来防止过拟合
# 加在输出层之前,训练过程中开启dropout,测试过程中关闭
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 输出层, 添加softmax层,类别数为10
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2) + b_fc2)
# 训练和评估模型
'''''
ADAM优化器来做梯度最速下降,feed_dict加入参数keep_prob控制dropout比例
'''
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv)) # 计算交叉熵
# 使用adam优化器来以0.0001的学习率来进行微调
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 判断预测标签和实际标签是否匹配
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
# 启动创建的模型,并初始化变量
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# 开始训练模型,循环训练1000次
for i in range(1000):
batch = mnist.train.next_batch(50) # batch 大小设置为50
if i%100 == 0:
train_accuracy = accuracy.eval(session=sess,
feed_dict={x:batch[0], y_:batch[1], keep_prob:1.0})
print("step %d, train_accuracy %g" %(i,train_accuracy))
# 神经元输出保持keep_prob为0.5,进行训练
train_step.run(session=sess, feed_dict={x:batch[0], y_:batch[1], keep_prob:0.5})
# 神经元输出保持keep_prob为1.0,进行测试
print("test accuracy %g" %accuracy.eval(session=sess,
feed_dict={x:mnist.test.images, y_:mnist.test.labels, keep_prob:1.0}))
# 计算程序结束时间
end = time.clock()
print("running time is %g s" %(end-start))
将上述代码复制后保存到 test.py文件,在Anaconda中激活tensorflow环境
source activate tensorflow
(tensorflow) ajm@ajm-zju:~$ python test.py
若运行正确会输出以下结果:
(tensorflow) ajm@ajm-zju:~$ python test.py
Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
2018-03-13 15:02:30.015471: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2018-03-13 15:02:30.134023: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:898] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2018-03-13 15:02:30.134237: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1212] Found device 0 with properties:
name: GeForce GTX 1060 3GB major: 6 minor: 1 memoryClockRate(GHz): 1.7335
pciBusID: 0000:01:00.0
totalMemory: 2.94GiB freeMemory: 2.49GiB
2018-03-13 15:02:30.134251: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1312] Adding visible gpu devices: 0
2018-03-13 15:02:30.303165: I tensorflow/core/common_runtime/gpu/gpu_device.cc:993] Creating TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 2198 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1060 3GB, pci bus id: 0000:01:00.0, compute capability: 6.1)
step 0, train_accuracy 0.06
step 100, train_accuracy 0.92
step 200, train_accuracy 0.96
step 300, train_accuracy 0.92
step 400, train_accuracy 0.92
step 500, train_accuracy 1
step 600, train_accuracy 1
step 700, train_accuracy 0.96
step 800, train_accuracy 0.96
step 900, train_accuracy 0.98
2018-03-13 15:02:36.083316: W tensorflow/core/common_runtime/bfc_allocator.cc:219] Allocator (GPU_0_bfc) ran out of memory trying to allocate 747.68MiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2018-03-13 15:02:36.083361: W tensorflow/core/common_runtime/bfc_allocator.cc:219] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.59GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2018-03-13 15:02:36.083390: W tensorflow/core/common_runtime/bfc_allocator.cc:219] Allocator (GPU_0_bfc) ran out of memory trying to allocate 3.32GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2018-03-13 15:02:36.343473: W tensorflow/core/common_runtime/bfc_allocator.cc:219] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.42GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
test accuracy 0.9673
running time is 7.45613 s
其他问题
通过上述方法完成后,通过Ipython,jupyter notebook import tensorflow会出错,此时应该在tensorflow环境下重新安装
conda install jupter notebook
引用
- Deep Learning-TensorFlow (1) CNN卷积神经网络_MNIST手写数字识别代码实现
- ubuntu16.04下安装CUDA,cuDNN及tensorflow-gpu版本过程 - CSDN博客
- Tensorflow的GPU支持模式下的安装要点
- Installing TensorFlow on Ubuntu | TensorFlow