机器学习——决策树算法的应用
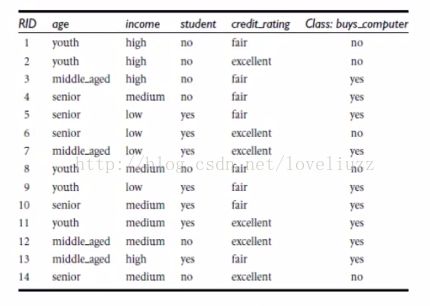
对于买电脑的示例,在Python数据包sk-learn中利用决策树算法实现数据分类,并画出决策树的结构
1、准备工作
(1)安装Graphviz(数据可视化软件),并配置好环境变量,加入到path中,
我的环境变量配置为:D:\Program Files\graphviz-2.38\release\bin,转化dot文件至pdf可视化决策树:dot _Tpdf inis.dot -o output.pdf
(2)将数据存储到文件后缀为.csv中,与代码文件在同一路径下面,我的路径为:F:\PythonCode\project\AllElectronicsData.csv
特别注意:在excel中将数据罗列出来之后,一定是另存为.csv文件,并且将文件编码由默认的GB2312修改为utf-8,否则直接修改后缀会导致后边代码中打开CSV文件时,出现编码相关的错误。具体设置参考网址:http://jingyan.baidu.com/article/90bc8fc87a78e0f653640ce8.html

2、sk-learn对于数据的输入格式要求
所有的属性或特征值(features)以及类必须是数值型的值而不能是类别的值,所以需要一个转化。举例:文件中第一行的转化格式如下:
![]()
对于年龄age有三种情况,第一行是youth,所以youth为1,middle_aged和senior都为0;同理,收入income里面的high为1,low和medium为0;学生students里面的no为1,yes为0;信用credit_rating里面的fair为1,excellent为0;分类class里面的no代表0,得到下面的数据转化。
![]()
sk-learn自带数据包(from sklearn.feature_extraction import DictVectorizer)可以实现将dict类型的list数据,转换成numpy array,特征值数据如下:
[{'age': 'youth', 'student': 'no', 'credit_rating': 'fair', 'income': 'high'}, {'age': 'youth', 'student': 'no', 'credit_rating': 'excellent', 'income': 'high'}, {'age': 'middle_aged', 'student': 'no', 'credit_rating': 'fair', 'income': 'high'}, {'age': 'senior', 'student': 'no', 'credit_rating': 'fair', 'income': 'medium'}, {'age': 'senior', 'student': 'yes', 'credit_rating': 'fair', 'income': 'low'}, {'age': 'senior', 'student': 'yes', 'credit_rating': 'excellent', 'income': 'low'}, {'age': 'middle_aged', 'student': 'yes', 'credit_rating': 'excellent', 'income': 'low'}, {'age': 'youth', 'student': 'no', 'credit_rating': 'fair', 'income': 'medium'}, {'age': 'youth', 'student': 'yes', 'credit_rating': 'fair', 'income': 'low'}, {'age': 'senior', 'student': 'yes', 'credit_rating': 'fair', 'income': 'medium'}, {'age': 'youth', 'student': 'yes', 'credit_rating': 'excellent', 'income': 'medium'}, {'age': 'middle_aged', 'student': 'no', 'credit_rating': 'excellent', 'income': 'medium'}, {'age': 'middle_aged', 'student': 'yes', 'credit_rating': 'fair', 'income': 'high'}, {'age': 'senior', 'student': 'no', 'credit_rating': 'excellent', 'income': 'medium'}]经过DictVectorizer数据包转化成numpy数组后,为:
[[ 0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
[ 0. 0. 1. 1. 0. 1. 0. 0. 1. 0.]
[ 1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
[ 0. 1. 0. 0. 1. 0. 0. 1. 1. 0.]
[ 0. 1. 0. 0. 1. 0. 1. 0. 0. 1.]
[ 0. 1. 0. 1. 0. 0. 1. 0. 0. 1.]
[ 1. 0. 0. 1. 0. 0. 1. 0. 0. 1.]
[ 0. 0. 1. 0. 1. 0. 0. 1. 1. 0.]
[ 0. 0. 1. 0. 1. 0. 1. 0. 0. 1.]
[ 0. 1. 0. 0. 1. 0. 0. 1. 0. 1.]
[ 0. 0. 1. 1. 0. 0. 0. 1. 0. 1.]
[ 1. 0. 0. 1. 0. 0. 0. 1. 1. 0.]
[ 1. 0. 0. 0. 1. 1. 0. 0. 0. 1.]
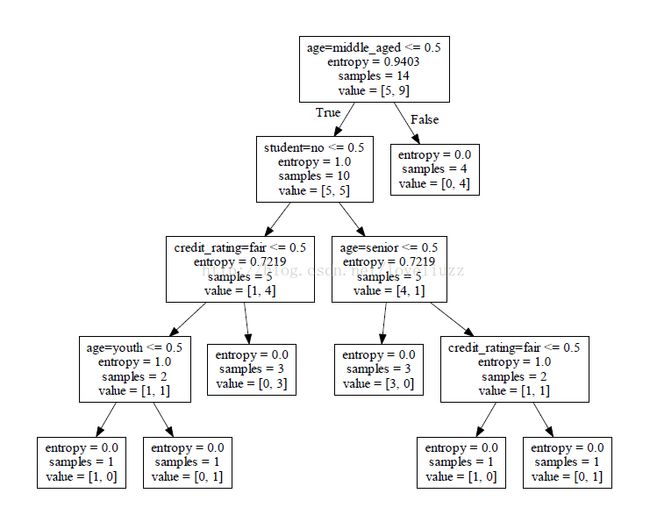
[ 0. 1. 0. 1. 0. 0. 0. 1. 1. 0.]]3、ID3算法构建决策树模型并用Graphviz画出决策树

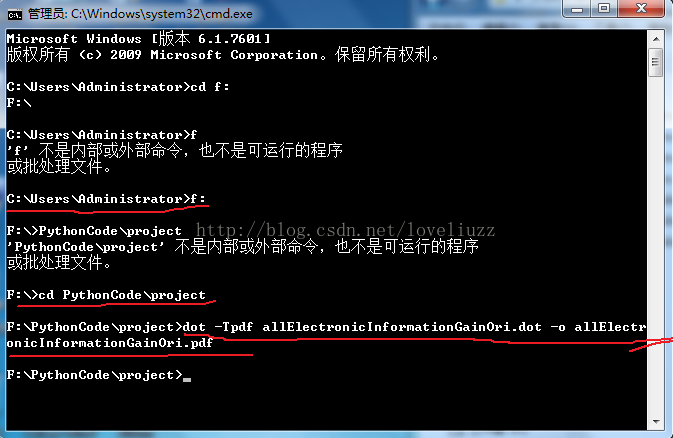
以写的方式创建打开文件allElectronicInformationGainOri.dot,并用可视化软件Graphviz保存决策树相关的结构信息。
在dos环境下,将.dot文件通过命令dot _Tpdf allElectronicInformationGainOri.dot -o allElectronicInformationGainOri.pdf转化成pdf文件打印出决策树。如下图:
4、代码实现
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
from sklearn.feature_extraction import DictVectorizer
import csv #原始数据存放在CSV文件中
from sklearn import preprocessing
from sklearn import tree
from sklearn.externals.six import StringIO
#读取csv文件
allElectronicsData = open("AllElectronicsData.csv","r",encoding="utf-8")
reader = csv.reader(allElectronicsData)
headers = next(reader) #第一行
print(headers)
#分类器对数据输入的格式有要求
featureList = [] #特征值列表
labelList = [] #类别列表
for row in reader:
#按行遍历
labelList.append(row[len(row)-1]) #将每行最后一个值作为分类class逐个装入到类别列表里面
rowDict = {} #初始化字典
for i in range(1,len(row)-1):
#print(row[i])
rowDict[headers[i]] = row[i] #headers[i]为键key,为键赋键值value
featureList.append(rowDict) #特征值列表
print(featureList)
#将特征值转dict类型的list数据转化成numpy数组
vec = DictVectorizer() #实例化
dummyX = vec.fit_transform(featureList) .toarray() #将dict类型的list数据,转换成numpy array
print("dummyX:"+str(dummyX))
print(vec.get_feature_names()) #打印特征值的种类
print("LabelList:"+str(labelList)) #打印标签列表
#将分类标签转化成numpy数组
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY:"+str(dummyY))
#创建决策树分类器
clf = tree.DecisionTreeClassifier(criterion="entropy") #ID3算法信息获取量作为属性选择判断
clf = clf.fit(dummyX,dummyY) #训练数据拟合构建决策树模型
print("clf:"+str(clf))
#利用数据可视化软件Graphviz打印出决策树
with open("allElectronicInformationGainOri.dot",'w') as f:
f = tree.export_graphviz(clf,feature_names=vec.get_feature_names(),out_file=f)
#利用构建出的决策树进行预测
oneRowX = dummyX[0,:] #取第一行
print("oneRowX:"+str(oneRowX))
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX:"+str(newRowX))
predictedY = clf.predict(newRowX)
print("predictedY:"+str(predictedY))['RID', 'age', 'income', 'student', 'credit_rating', 'Class_buys_computer']
[{'credit_rating': 'fair', 'age': 'youth', 'student': 'no', 'income': 'high'}, {'credit_rating': 'excellent', 'age': 'youth', 'student': 'no', 'income': 'high'}, {'credit_rating': 'fair', 'age': 'middle_aged', 'student': 'no', 'income': 'high'}, {'credit_rating': 'fair', 'age': 'senior', 'student': 'no', 'income': 'medium'}, {'credit_rating': 'fair', 'age': 'senior', 'student': 'yes', 'income': 'low'}, {'credit_rating': 'excellent', 'age': 'senior', 'student': 'yes', 'income': 'low'}, {'credit_rating': 'excellent', 'age': 'middle_aged', 'student': 'yes', 'income': 'low'}, {'credit_rating': 'fair', 'age': 'youth', 'student': 'no', 'income': 'medium'}, {'credit_rating': 'fair', 'age': 'youth', 'student': 'yes', 'income': 'low'}, {'credit_rating': 'fair', 'age': 'senior', 'student': 'yes', 'income': 'medium'}, {'credit_rating': 'excellent', 'age': 'youth', 'student': 'yes', 'income': 'medium'}, {'credit_rating': 'excellent', 'age': 'middle_aged', 'student': 'no', 'income': 'medium'}, {'credit_rating': 'fair', 'age': 'middle_aged', 'student': 'yes', 'income': 'high'}, {'credit_rating': 'excellent', 'age': 'senior', 'student': 'no', 'income': 'medium'}]
dummyX:[[ 0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
[ 0. 0. 1. 1. 0. 1. 0. 0. 1. 0.]
[ 1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
[ 0. 1. 0. 0. 1. 0. 0. 1. 1. 0.]
[ 0. 1. 0. 0. 1. 0. 1. 0. 0. 1.]
[ 0. 1. 0. 1. 0. 0. 1. 0. 0. 1.]
[ 1. 0. 0. 1. 0. 0. 1. 0. 0. 1.]
[ 0. 0. 1. 0. 1. 0. 0. 1. 1. 0.]
[ 0. 0. 1. 0. 1. 0. 1. 0. 0. 1.]
[ 0. 1. 0. 0. 1. 0. 0. 1. 0. 1.]
[ 0. 0. 1. 1. 0. 0. 0. 1. 0. 1.]
[ 1. 0. 0. 1. 0. 0. 0. 1. 1. 0.]
[ 1. 0. 0. 0. 1. 1. 0. 0. 0. 1.]
[ 0. 1. 0. 1. 0. 0. 0. 1. 1. 0.]]
['age=middle_aged', 'age=senior', 'age=youth', 'credit_rating=excellent', 'credit_rating=fair', 'income=high', 'income=low', 'income=medium', 'student=no', 'student=yes']
LabelList:['no', 'no', 'yes', 'yes', 'yes', 'no', 'yes', 'no', 'yes', 'yes', 'yes', 'yes', 'yes', 'no']
dummyY:[[0]
[0]
[1]
[1]
[1]
[0]
[1]
[0]
[1]
[1]
[1]
[1]
[1]
[0]]
clf:DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')
oneRowX:[ 0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
newRowX:[ 1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
predictedY:[1]