即上篇文章Hadoop基础之HA(高可用)之后,本文将介绍HDFS HA的搭建与配置。参考官方文档:http://hadoop.apache.org/docs/r2.7.4/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html#Configuration_details
1.主要步骤
- 时间同步(ntp时间同步) 网络 hosts 防火墙关闭等
时间同步命令:
yum install ntp
ntpdate -u s1a.time.edu.cn
ntp时间服务器列表:http://www.ntp.org.cn/
关于网络配置请参考:Virtualbox配置centos7网络
- 安装jdk1.7以上
- 上传 解压
- 需要做免密钥,两天NameNode之间一定要做免密钥。
node1到node1-4
node2到node1-4
关于免密钥,参考文章:centos7设置SSH免密码登录教程
- 修改配置文件(需要先停止hdfs集群)
如果是1.x中的,需要手动删除masters文件(一定要保证每台服务器都删除)
etc/profile: HADOOP_HOME
hadoop-env.sh 中的JAVA_HOME
core-site.xml:hadoop.tmp.dir配置,需要保证每台服务器的该目录不存在或者为空目录
hdfs-site.xml: HA不需要SNN
slaves 指定datanode
同步配置文件到各个节点
格式化之前必须先启动journalnode:
hadoop-daemon.sh start journalnode
8.格式化namenode:在一台NameNode上执行格式化命令
hdfs namenode -format
格式化完成后,需要启动当前服务器的NameNode (node1):
hadoop-daemon.sh start namenode
- 同步fsimage,其他没有格式化的NameNode上执行命令(node2):
hdfs namenode -bootstrapStandby
- 安装ZK,启动Zookeeper集群(node1 node2 node3)
Zookeeper集群安装请参考:Zookeeper 安装、配置、使用
zkServer.sh start
- 格式化ZK:
hdfs zkfc -formatZK(在其中一台NameNode上)
- 启动hdfs:
start-dfs.sh
- 第二次启动集群的时候只需要以下命令:
1.启动ZK集群
2.start-dfs.sh
2.HA节点分布

需要注意的是:ZKFC无需配置,只需要确定了NameNode节点位置,ZKFC就自动确定了。建议:DN与JN在相同的节点上。
3.配置hdfs-site.xml
dfs.nameservices
lyx
dfs.ha.namenodes.lyx
nn1,nn2
dfs.namenode.rpc-address.lyx.nn1
master:8020
dfs.namenode.rpc-address.lyx.nn2
slave1:8020
dfs.namenode.http-address.lyx.nn1
master:50070
dfs.namenode.http-address.lyx.nn2
slave1:50070
dfs.namenode.shared.edits.dir
qjournal://slave1:8485;slave2:8485;slave3:8485/lyx
dfs.client.failover.proxy.provider.lyx
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.automatic-failover.enabled
true
dfs.journalnode.edits.dir
/usr/local/hadoop/current/journal/data
dfs.webhdfs.enabled
true
dfs.permissions.superusergroup
staff
dfs.permissions.enabled
false
4.配置core-site.xml
fs.defaultFS
hdfs://lyx
hadoop.tmp.dir
/usr/local/hadoop/current/tmp
ha.zookeeper.quorum
master:2181,slave1:2181,slave2:2181
5.同步配置文件
scp hdfs-site.xml slave1://usr/local/hadoop/etc/hadoop
scp hdfs-site.xml slave2://usr/local/hadoop/etc/hadoop
scp hdfs-site.xml slave3://usr/local/hadoop/etc/hadoop
scp core-site.xml slave1://usr/local/hadoop/etc/hadoop
scp core-site.xml slave2://usr/local/hadoop/etc/hadoop
scp core-site.xml slave3://usr/local/hadoop/etc/hadoop
6.启动journalnode(node2-4)
hadoop-daemon.sh start journalnode

7.格式化namenode
在一台NameNode(node1)上执行格式化命令:
hdfs namenode -format
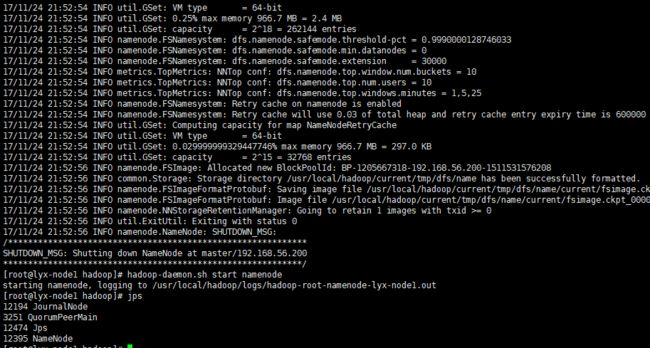
格式化完成后,需要启动当前服务器的NameNode :hadoop-daemon.sh start namenode
8.同步fsimage
其他没有格式化的NameNode上执行命令(node2):
hdfs namenode -bootstrapStandby
此时若没有先执行上面的启动Namenode操作(在node1上),则会报以下错误:
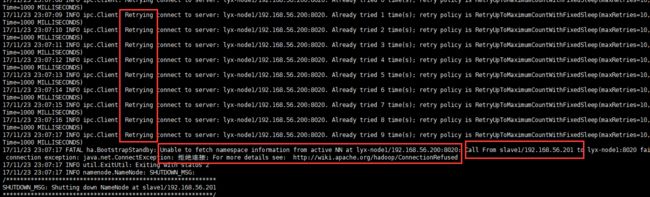
所以必须在格式化后先启动NameNode(node1):hadoop-daemon.sh start namenode
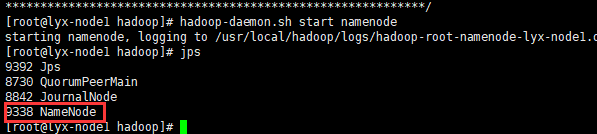
启动完成后,再在node2上执行同步命令就正常了
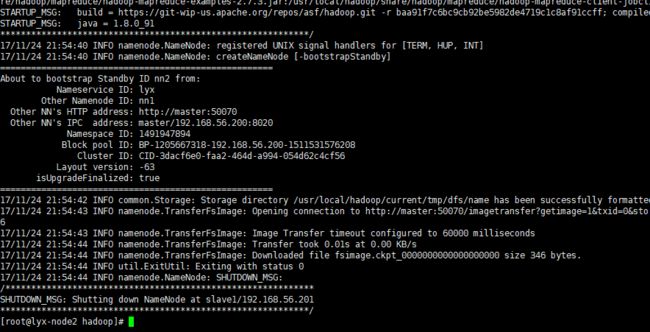
9.启动zk
hdfs zkfc -formatZK(在其中一台NameNode上)
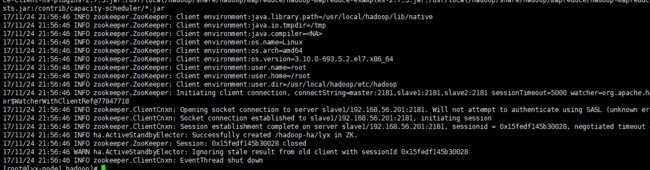
10.启动hdfs
start-dfs.sh
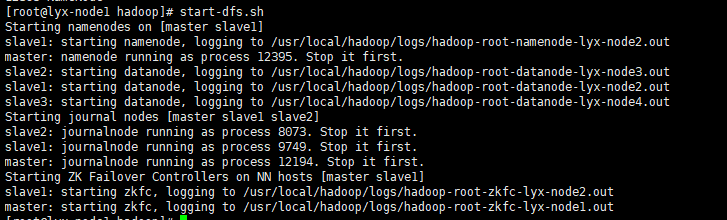
以上,因为在之前启动了JN和NN,故出现stop it first,下一次启动就不会出现了。
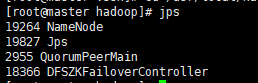
启动完成。在node1和node2节点,有如下进程:
node1含有NN,ZK,ZKFC:
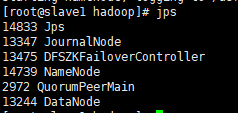
node2含有NN,ZK,ZKFC,DN,JN:
node3含有DN,JN,ZK:
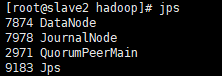
node4含有DN,JN,ZK:
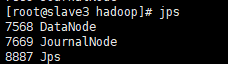
符合最初设定的节点设置。
11.网页查看情况
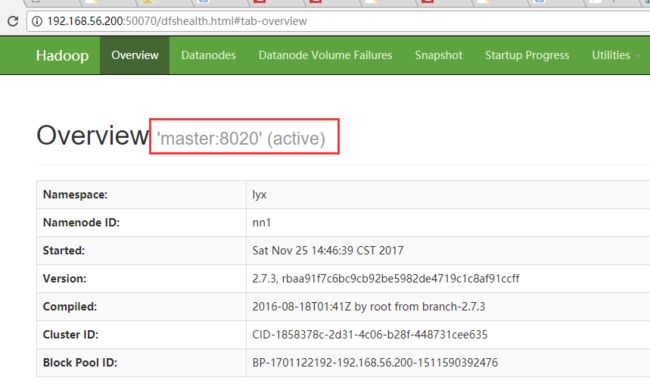
查看node1(master)节点,目前是active状态
node2(slave1)是standby状态:
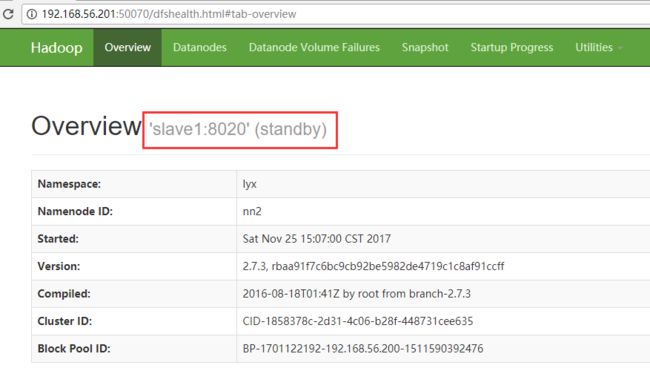
处于standby状态,HDFS文件系统也是进不去的:

12.发现问题
12.1 问题
把node1中的namenode进程关掉:hadoop-daemon.sh stop namenode,此时,发现node2状态还是standby,不会自动切换,然后重新启动namenode1,则恢复正常,namenode1变为standby,namenode2变为active。


查看node1中的hadoop-root-zkfc-master.log日志文件发现:
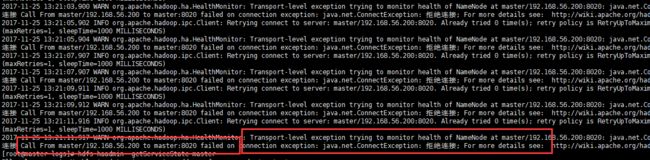
查看node2中的hadoop-root-zkfc-slave1.log日子文件发现:
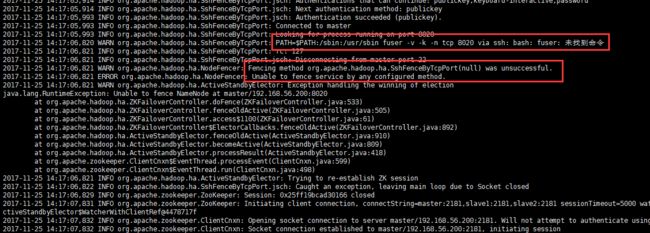
12.2 原因查找
由slave1上的错误日志信息可以看出,fuser: 未找到命令,在做主备切换时执行fuser命令失败了。
查看hdfs-site.xml配置文件,
dfs.ha.fencing.methods
sshfence
hdfs-site.xml通过参数dfs.ha.fencing.methods来实现,在出现故障时通过哪种方式登录到另一个namenode上进行接管工作。
12.3 dfs.ha.fencing.methods参数解释
系统在任何时候只有一个namenode节点处于active状态。在主备切换的时候,standby namenode会变成active状态,原来的active namenode就不能再处于active状态了,否则两个namenode同时处于active状态会有问题。所以在failover的时候要设置防止2个namenode都处于active状态的方法,可以是Java类或者脚本。
fencing的方法目前有两种,sshfence和shell,sshfence方法是指通过ssh登陆到active namenode节点杀掉namenode进程,所以你需要设置ssh无密码登陆,还要保证有杀掉namenode进程的权限。
12.4 解决方案
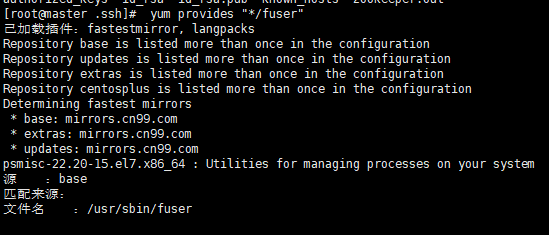
- 查找fuser
[root@master .ssh]# yum provides "*/fuser"
- 在namenode主、备节点上安装fuser(datanode节点不用安装)
[root@master .ssh]# yum -y install psmisc
[root@slave1 logs]# yum -y install psmisc
13.故障迁移测试
通过以上修正,则可以顺利的进行NameNode的自动切换。
把node1中的namenode进程关掉:hadoop-daemon.sh stop namenode
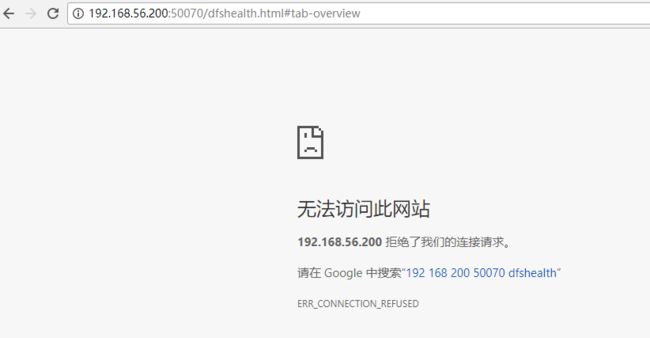
node1(master)不能访问了,而node2(slave1)就自动切换为了active状态。
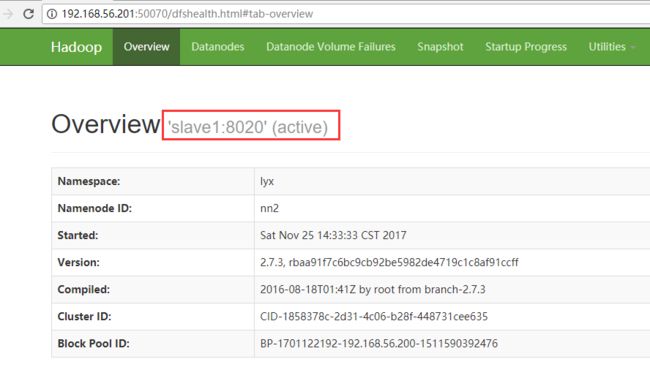
重新启动node1,hadoop-daemon.sh start namenode ,此时,master变为了standby状态
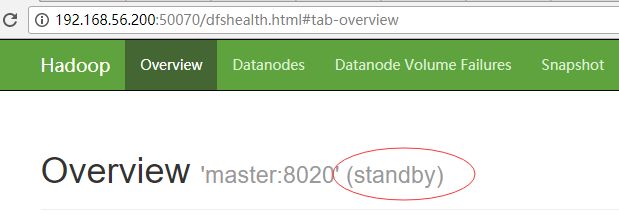
此时再次停止node2(slave1)的话,node1(master)节点就自动切换为active状态。
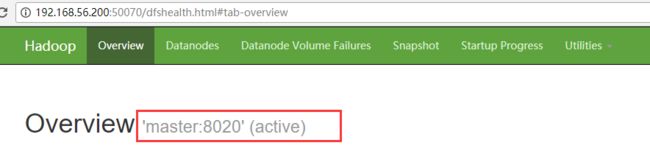
由上面的测试可知,hdfs ha集群环境已经搭建成功!
14.写在后面
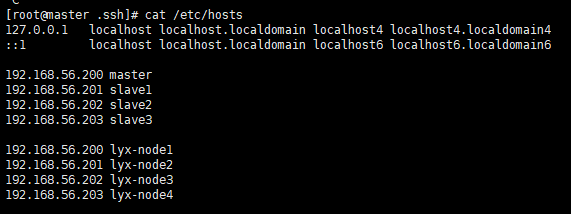
一开始故障迁移zkfc不会实行自动切换,找了很久,一开始怀疑SSH免密登录无效,可是我是配置了四台了主机都互通的,这条已经否定。后面怀疑,是不是必须要datanode和journalNode在一起,(一开始,我配置的journalnode是node1-node3节点),后面经证实,也非必须。到后面,竟然还怀疑,是不是我的hostname配置的有问题,(因为我配置了好几组的/etc/hosts),当时怀疑/etc/hostname中的配置的需要跟/etc/hosts中配置的一致,后面发现非必须。我的配置如下:
node1为例:
倒腾了半天后,从日志文件中找出错误信息,从而在网上找到类似的问题,进而找到解决方案。故,大数据环境出现问题,必须要看日志,必须得认真看日志。
15.延伸阅读
- Hadoop安装与集群配置
- Hadoop基本知识点之HDFS
- Hadoop之HDFS的Java实现
- Hadoop之YARN的安装与测试
- Hadoop基础之HA的安装与配置