【学习笔记】用Hadoop在MapReduce中WordCount简单程序运行详细流程
1、首先在电脑上安装配置Hadoop环境
具体的环境配置可以参考我上传的文档:
Hadoop安装手册 Hadoop-2.5.2:http://download.csdn.net/download/m0_37885286/9859619
,里面的内容十分详尽,按照里面的内容配置,简单高效,里面所需要用到的centOS6.5的镜像在网上搜一个,我用的是:CentOS-6.5-x86_64-bin-DVD1.iso,我的Hadoop是两台虚拟机,一台是master,一台是slave,都是1G内存的。如果有资源的话,可以扩建内存和多创几个虚拟机,这样可以跑更大的数据,而且跑起来也快。
2、配置好环境后,需要WordCount的程序:
我的程序是用:
Hadoop的词频统计源代码WordCount:
http://download.csdn.net/download/m0_37885286/9859625
2.1先就自己的理解介绍一下该程序
1、首先,在该程序中,先是导入了一些jar包
2、然后,在该WordCount程序中有一个WrodCount的类,该类里面又有2个静态的类:WrodCountMap类和WordCountReduce类。
3、在WroCountMap类中,它继承了Mapper接口,在Mapper借口中,定义了该文件的输入的格式是LongWritable, Text;输出的格式是Text, IntWritable。其中,LongWritable, Text是输入的key和value,而Text, IntWritable是输出的key和value.

4、private final IntWritable one = new IntWritable(1);
private final IntWritable one表示初始化“one”这个变量,这个“one”变量的类型是IntWritable,并且表示单词出现了1次。而在
while(token.hasMoreTokens()){
word.set(token.nextToken());
context.write(word,one);
}的作用是一个截断分词,每发现一个词,就写入一个one;
5、然后是Reducer接口,它主要是对相同的key值进行累加。
6、最后是一个主函数,main(),里面是配置这个MapReduce作业所需要的一些类。以及作业的名字为wordcount,job.setJobName(“wordcount”);
具体在程序中,给到一个输入路径和输出路径如下图:
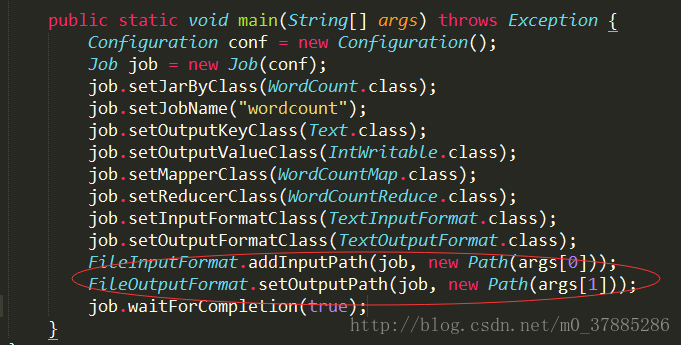
这里面的Text是指使用UTF8格式存储的文本(txt);
2.2如何将WordCount.java在Hadoop环境下运行
主要步骤如下:
1、首先,将WordCount.java程序进行编译成 .class 文件,编译好之后将其打包成一个jar文件;
2、然后将jar提交到hadoop中进行运行,并且指定输入文件和输出文件。
1、首先,我们第一步,确认Hadoop是否在运行,在桌面上运行终端,在终端中输入jps,出现jps,SecondaryNameNode,NameNode则说明Hadoop已经运行成功了。
具体如下图:

1.1如果Hadoop没有在运行的话,我们就要运行Hadoop,使用如下代码:
cd ~/hadoop-2.5.2
sbin/start-all.sh2、创建一个目录,比如小编在此创建的是example_MapReduce,并且将上面的源代码编写入该文件夹中:

3、然后将java程序进行编译
用 javac WordCount.java -d word_count_class/执行后会得到3个.class文件,这是后面可以执行的java文件。
在本步骤中,因为hadoop-2.5.2的jar包不是全放在hadoop-core-1.0.1.jar
所以,我们需要将 Hadoop 的 classhpath 信息添加到 CLASSPATH 变量中,在 ~/.bashrc 中增加如下几行:
先用 vim ~/.bashrc编译,然后再编译进去的bashrc中增加如下几行:
export HADOOP_HOME=/usr/local/hadoop export
CLASSPATH= ( HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
然后执行,source ~/.bashrc将它保存
具体可以参考这个文档,里面有详细说明:
http://www.powerxing.com/hadoop-build-project-by-shell/
4、然后我们将当前目录下所有class都打成一个jar包
执行 jar -cvf wordcount.jar *.class added manifest5、紧接着我们开始创建一个input文件夹,然后里面包含着我们需要输入的文件,文件保存的格式都是文本格式。
如:我创建的input文件,里面有file1和file2

6、【这一步特别注意!】将file1和file2提交到hadoop的hdfs中去。
首先要创建一个输入文件夹:
hadoop fs -mkdir /input_wordcount然后将file1和file2存入input_wordcount文件夹中:
hadoop fs -put input/* /input_wordcount/
在这一步要特别注意!!!!
在运行hadoop fs -put input/* /input_wordcount/ 的时候,千万不要在root用户下,因为我们之前按照文档配置的是我们用户cmq能够使用hdfs,而root是没有权限能够用hdfs的,所以,我们在这里就不能在root用户下输入该命令。
在root用户下输入该命令会报错:
mkdir: Permission denied: user=root, access=WRITE, inode="/":cmq:supergroup:drwxr-xr-x这就说明root用户没有权限。

7、最后就是提交任务到hadoop中
使用 hadoop jar word_count_class/wordcount.jar WordCount /input_wordcount /output_wordcount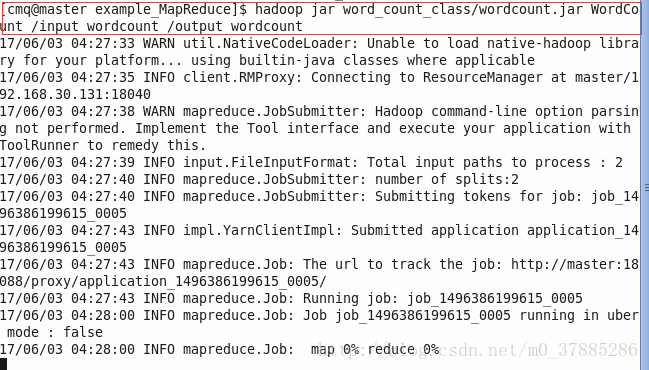
8、最后使用如下命令查看结果:
hadoop fs -ls /output_wordcount查看输出文件里包含的文件
然后再输入如下命令查看结果:
hadoop fs -cat /output_wordcount/part-r-00000最终结果如下图:

到此,在MapReduce中WordCount简单程序就执行完了!