Facebook蓝光存储数据中心的节能应用
Facebook蓝光存储数据中心的节能应用
我们一般接触到的存储是机械硬盘HDD或固态硬盘SSD,其实还有磁带库、蓝光等海量存储介质,比如 Facebook数据中心就采用了蓝光存储。

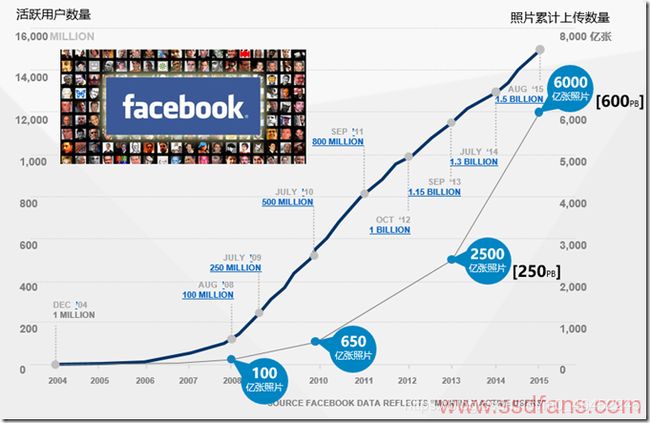
facebook是世界上最大的图片分享网站 :
• 2013年活跃用户的数量达到11.5亿人,每天上传照片数量超过3.5亿张。
• 2015年活跃用户的数量超过15亿人,单日使用量突破10亿人次facebook保存了
数目庞大的照片数据。
• 目前累计上传照片数量超过6000亿张。
• 对于每张照片,facebook存储大小不同的四个版本 (在某些场景下只需展示缩略图), 意味着:facebook服务器上存储着2.4万亿张照片。
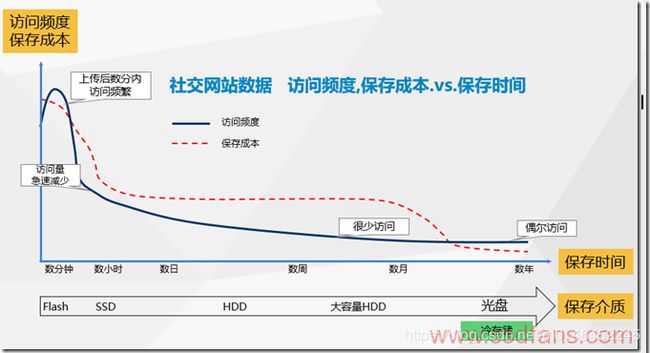
下图是社交网站图片的访问频率随时间的变化趋势,刚上传后访问频率最高,后面逐渐降低,一年后就成了偶尔访问。存储介质也是分级存储,从全闪存、SSD到HDD、光盘。
• facebook保存大量图像数据。为了满足实时性要求,在Hadoop系统 (注1)上
保存图像数据。
• 作为Hadoop发生故障时的候补,在光存储系统上存储Hadoop的备份。
• 为了提升备份效率,使用Reed Solomon符号在光盘上分散记录。

facebook最终采用了蓝光光盘作为冷存储介质:
• 用户照片等数据需要长期保存,现有介质成本高、可靠性低。
• 与硬盘相比整体成本削减50%以上 [成本包括:设备成本、能耗成本、网络成
本、机房成本、人员成本、运营成本]。
• 不需要大量空调冷却系统。
耗电量降低80%以上 [光盘库工作功耗远低于硬盘,不需要大量空调冷却系统。
• 废止数据中心内的冗余设计(2套系统供电、2套UPS、自备电源、2套回路
等等),数据中心大幅降低成本。

facebook异地备份方案 :
• 在冷存储更新频度低的前提下,地理上分离的多个场所间作数据冗余
• 以冷数据为对象搭载异地备份(Geo Replication)功能
• 进行数据中心间的冗余功能,废止数据中心内的冗余。
• facebook已在Prineville的Forest City进行商用,Google已在Spanner上实现
异地备份使可用性和吞吐量性能同时实现

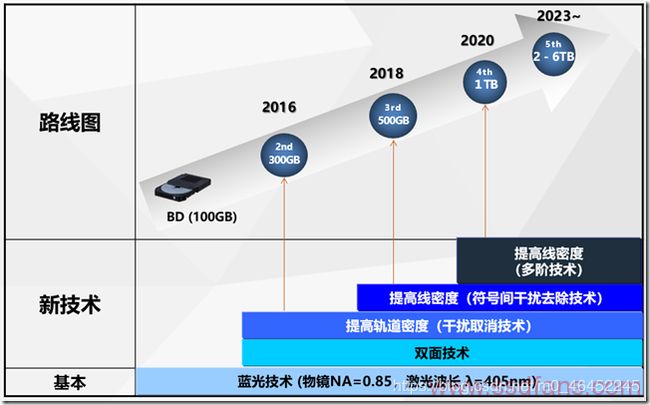
蓝光存储的發展與未来 :
先看看蓝光存储技术路线图,2023年单盘可以到几TB容量。
未来的光存储技术:
(1). 全息光存储技术
(1-3). 美国InPhase (InPhace 1.6TB/盘) 、
日本日立(日立2TB-8TB/盘)、日本NHK
(2). 双光束超分辨技术
(2-1). 实验装置水平: 可实现单盘15TB容量
(2-2). 最新实验结果:9nm特征尺寸 理论上可达单盘 1PB
(2-3). 澳大利亚,武汉光电国家实验室
(3). 多维技术 (英国南开普敦大学)
(3-1). 开发成功采用纳米晶玱璃的5维光盘,存储寿命可超过亿年,实现永久存储.
(3-2). In glass 5D: 369TB/disc
Facebook 蓝光存储数据中心的节能總結 :
(1). 蓝光存储介质工作功耗低、耗电量降低80%以上。
(2). 不需要大量空调冷却系统。
(3). 进行数据中心间的冗余功能,废止数据中心内的冗余(冗余设计 : 2套系统供
电、2套UPS、自备电源、2套回路 等等)。

注1 :
(1). 认识大数据的黄色小象帮手 –– Hadoop
继云端运算(Cloud Computing)之后,大数据(Big Data)接棒成为最热门的科技潮字,和大数据有关的技术和科技接二连三成为科技圈注目的焦点,如果你也关注云端跟大数据的信息,Hadoop 这个字出现频率一定挺高的,这个黄色小象 Logo 也应该经常亮相。究竟 Hadoop 是什么?能够用来解决什么问题?又为什么重要?
继云端运算(Cloud Computing)之后,大数据(Big Data)接棒成为最热门的科技潮字,和大数据有关的技术和科技接二连三成为科技圈注目的焦点。如果你也关注云端跟大数据的信息,Hadoop 这个字出现频率一定挺高的,这个黄色小象 Logo 也应该经常亮相。
究竟 Hadoop 是什么?能够用来解决什么问题?又为什么重要?比起解释一大堆技术上的细节,倒不如从 Hadoop 处理巨量数据的角度切入了解,看 Hadoop 能够带来什么好处,同时也从这个方向反过来理解大数据。
(1-1). Hadoop 简史:
Hadoop 的雏形 Nutch 最初是由 Doug Cutting 和 Mike Cafarella 针对网页相关的数据搜寻而开发,2006 年 Doug Cutting 进入 Yahoo 后成立了专业的团队继续研究发展这项技术,正式命名为 Hadoop。
Hadoop 这个名称并不代表任何英文字汇或者缩写代号,「Hadoop」来自于 Doug Cutting 儿子的一个黄色大象填充玩具
1,主要原因是开发过程中他需要为这套软件提供一个代号方便沟通,而 Hadoop 这个名字发音简单拼字容易,且毫无意义、也没有在任何地方使用过,因此雀屏中选,黄色小象也因而成为 Hadoop 的标志。
值得一提的是,在 Hadoop 之后所发展的几个相关软件和模块也都参考了这样的命名方式,名称不会与主要功能实际相关,而是采用与大象或其他动物有关的名称作为其开发代号,像是 Pig、Hive、ZooKeeper 等等。
(1-2). 什么是 Hadoop ?
首先,想象有个档案大小超过 PC 能够储存的容量,那便无法储存在你的计算机里,对吧?
Hadoop 不但让你储存超过一个服务器所能容纳的超大档案,还能同时储存、处理、分析几千几万份这种超大档案,所以每每提到大数据,便会提到 Hadoop 这套技术。
简单来说,Hadoop 是一个能够储存并管理大量数据的云端平台,为 Apache 软件基金会底下的一个开放原始码、社群基础、而且完全免费的软件,被各种组织和产业广为采用,非常受欢迎。
(1-3). Hadoop主要的两项功能:
Hadoop 如何储存数据(Store)
Hadoop 怎么处理数据(Process)

Hadoop 是一个丛集系统(cluster system),也就是由单一服务器扩充到数以千计的机器,整合应用起来像是一台超级计算机。而数据存放在这个丛集中的方式则是采用 HDFS 分布式文件系统(Hadoop Distributed File System)。
HDFS 的设计概念是这样的,丛集系统中有数以千计的节点用来存放数据,如果把一份档案想成一份藏宝图,机器中会有一个机器老大(Master Node)跟其他机器小弟(Slave/Worker Node),为了妥善保管藏宝图,先将它分割成数小块(block),通常每小块的大小是 64 MB,而且把每小块拷贝成三份(Data replication),再将这些小块分散给小弟们保管。机器小弟们用「DataNode」这个程序来放藏宝图,机器老大则用「NameNode」这个程序来监视所有小弟们藏宝图的存放状态。
如果老大的程序 NameNode 发现有哪个 DataNode 上的藏宝图遗失或遭到损坏(例如某位小弟不幸阵亡,顺带藏宝图也丢了),就会寻找其他 DataNode 上的副本(Replica)进行复制,保持每小块的藏宝图在整个系统都有三份的状态,这样便万无一失。
透过 HDFS,Hadoop 能够储存上看 TB(Tera Bytes)甚至 PB(Peta Bytes)等级的巨量数据,也不用担心单一档案的大小超过一个磁盘区的大小,而且也不用担心某个机器损坏导致数据遗失。
(1-4). Yahoo 的 Hadoop cluster 系统:

(1-4-1). Map Reduce 平行运算架构
上一段提到,HDFS 将数据分散储存在 Hadoop 计算机丛集中的数个机器里,现在我们要谈谈 Hadoop 如何用 MapReduce 这套技术处理这些节点上的数据。
在函数程序设计(Functional programming)3 中很早就有了 Map(映射)和 Reduce(归纳)的观念,类似于算法中个别击破(Divide and Conquer)的作法,也就是将问题分解成很多个小问题之后再做总和。
Map Reduce 顾名思义是以 Map 跟 Reduce 为基础的应用程序。一般我们进行数据分析处理时,是将整个档案丢进程序软件中做运算出结果,而面对巨量数据时,Hadoop 的做法是采用分布式计算的技术处理各节点上的数据。
在各个节点上处理数据片段,把工作分散、分布出去的这个阶段叫做 Mapping;接下来把各节点运算出的结果直接传送回来归纳整合,这个阶段就叫做 Reducing。这样多管齐下、在上千台机器上平行处理巨量数据,可以大大节省数据处理的时间。
黄色小象以及小象的朋友们
总和来看,Hadoop 透过 HDFS 和 MapReduce 这两项核心功能,解决了档案存放的问题、解决了系统扩张的问题、解决了系统备份的问题、解决了数据处理的问题,非常适合应用于大数据储存和大数据分析,因此被广泛接受成为大数据的主流技术。
当然 Hadoop 并没有解决所有巨量数据带来的难题,所以许多与 Hadoop 相关的技术被开发来应付巨量数据的其他需求 4。像是用来处理数据的 Script 语言「Pig」、类似 SQL 语法查询功能的「Hive」、专门用在 Hadoop 上的数据库系统「HBase」等。
(1-5). Hadoop 生态系:
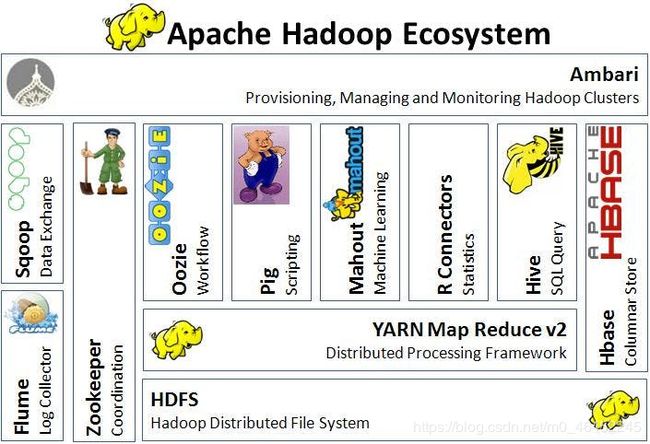
(2). Hadoop和Spark的差异
谈到大数据,相信大家对Hadoop 和Apache Spark 这两个名字并不陌生。但我们往往对它们的理解只是提留在字面上,并没有对它们进行深入的思考,下面不妨跟我一块看下它们究竟有什么异同。
1.解决问题的层面不一样
首先,Hadoop 和Apache Spark 两者都是大数据框架,但是各自存在的目的不尽相同。 Hadoop 实质上更多是一个分布式数据基础设施: 它将巨大的数据集分派到一个由普通计算器组成的集群中的多个节点进行存储,意味着您不需要购买和维护昂贵的服务器硬件。
同时,Hadoop 还会索引和跟踪这些数据,让大数据处理和分析效率达到前所未有的高度。 Spark,则是那么一个专门用来对那些分布式存储的大数据进行处理的工具,它并不会进行分布式数据的存储。
2.两者可合可分
Hadoop 除了提供为大家所共识的HDFS 分布式数据存储功能之外,还提供了叫做Map Reduce 的数据处理功能。所以这里我们完全可以抛开Spark,使用Hadoop 自身的Map Reduce 来完成数据的处理。
相反,Spark 也不是非要依附在Hadoop 身上才能生存。但如上所述,毕竟它没有提供文件管理系统,所以,它必须和其他的分布式文件系统进行集成才能运作。这里我们可以选择Hadoop 的HDFS,也可以选择其他的基于云的数据系统平台。但Spark 默认来说还是被用在Hadoop 上面的,毕竟,大家都认为它们的结合是最好的。
以下是天地会珠海分舵网上摘录的对Map Reduce 的最简洁明了的解析:
『我们要数图书馆中的所有书。你数 1 号书架,我数 2 号书架。这就是“Map”。我们人越多,数书就更快。
现在我们一起,把所有人的统计数加在一起。这就是“Reduce”。』
3. Spark 数据处理速度秒杀 Map Reduce
Spark 因为其处理数据的方式不一样,会比Map Reduce 快上很多。 Map Reduce 是分步对数据进行处理的: ”从集群中读取数据,进行一次处理,将结果写到集群,从集群中读取更新后的数据,进行下一次的处理,将结果写到集群,等等…“ Booz Allen Hamilton 的数据科学家Kirk Borne 如此解析。
反观Spark,它会在内存中以接近“实时”的时间完成所有的数据分析:“从集群中读取数据,完成所有必须的分析处理,将结果写回集群,完成。 Spark 的批处理速度比Map Reduce 快近10 倍,内存中的数据分析速度则快近100 倍。
如果需要处理的数据和结果需求大部分情况下是静态的,且你也有耐心等待批处理的完成的话,Map Reduce 的处理方式也是完全可以接受的。
但如果你需要对流数据进行分析,比如那些来自于工厂的传感器收集回来的数据,又或者说你的应用是需要多重数据处理的,那么你也许更应该使用Spark 进行处理。
大部分机器学习算法都是需要多重数据处理的。此外,通常会用到Spark 的应用场景有以下方面:实时的市场活动,在线产品推荐,网络安全分析,机器日记监控等。
4. 灾难恢复
两者的灾难恢复方式迥异,但是都很不错。因为Hadoop 将每次处理后的数据都写入到磁盘上,所以其天生就能很有弹性的对系统错误进行处理。
Spark 的数据对象存储在分布于数据集群中的叫做弹性分布式数据集(RDD: Resilient Distributed Dataset)中。 “这些数据对象既可以放在内存,也可以放在磁盘,所以RDD 同样也可以提供完成的灾难恢复功能。
本文感謝 www.ssdfans.com 及 Wikipedia 的資料 .