Kaggle泰坦尼克号之灾
kaggle比赛地址:
Titanic: Machine Learning from Disaster
相关比赛背景、数据等都可在网站查看。
1、环境配置
- windows 10
- python 3.6
- pandas
- numpy
- jupyter notebook
- seaborn
2、数据分析
# 载入pandas包来读取csv格式的数据集
import pandas as pd
import numpy as np
# 把csv格式的数据集导入到DataFrame对象中
df_train = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')
all_data = pd.concat([df_train, df_test], ignore_index = True)
all_data.head() 输出结果
特征属性解释
| Variable | Definition | Key | Description | 意义 |
|---|---|---|---|---|
| PassengerId | Passenger Id | 乘客ID | ||
| Survived | Survival | 0 = No, 1 = Yes |
是否获救 | |
| Pclass | Ticket class | 1 = 1st, 2 = 2nd, 3 = 3rd |
A proxy for socio-economic status (SES) 1st = Upper 2nd = Middle 3rd = Lower |
乘客等级 |
| Name | Name | 乘客姓名 | ||
| Sex | Sex | 性别 | ||
| Age | Age in years | Age is fractional if less than 1. If the age is estimated, is it in the form of xx.5 | 年龄 | |
| SibSp | # of siblings / spouses aboard the Titanic | The dataset defines family relations in this way... Sibling = brother, sister, stepbrother, stepsister Spouse = husband, wife (mistresses and fiancés were ignored) |
配偶和兄弟姐妹人数 | |
| Parch | # of parents / children aboard the Titanic | The dataset defines family relations in this way... Parent = mother, father Child = daughter, son, stepdaughter, stepson Some children travelled only with a nanny, therefore parch=0 for them. |
父母与小孩人数 | |
| Ticket | Ticket number | 船票号码 | ||
| Fare | Passenger fare | 票价 | ||
| Cabin | Cabin number | 客舱号码 | ||
| Embarked | Port of Embarkation | C = Cherbourg, Q = Queenstown, S = Southampton |
登船港口 |
查看数据详情
all_data.info()
打印结果
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 12 columns):
Age 1046 non-null float64
Cabin 295 non-null object
Embarked 1307 non-null object
Fare 1308 non-null float64
Name 1309 non-null object
Parch 1309 non-null int64
PassengerId 1309 non-null int64
Pclass 1309 non-null int64
Sex 1309 non-null object
SibSp 1309 non-null int64
Survived 891 non-null float64
Ticket 1309 non-null object
dtypes: float64(3), int64(4), object(5)
memory usage: 122.8+ KB 数据大小为1309行*12列,但不少属性包含空值
再看看具体描述,数值型特征属性详情
all_data.describe()输出结果
Age Fare Parch PassengerId Pclass \
count 1046.000000 1308.000000 1309.000000 1309.000000 1309.000000
mean 29.881138 33.295479 0.385027 655.000000 2.294882
std 14.413493 51.758668 0.865560 378.020061 0.837836
min 0.170000 0.000000 0.000000 1.000000 1.000000
25% 21.000000 7.895800 0.000000 328.000000 2.000000
50% 28.000000 14.454200 0.000000 655.000000 3.000000
75% 39.000000 31.275000 0.000000 982.000000 3.000000
max 80.000000 512.329200 9.000000 1309.000000 3.000000
SibSp Survived
count 1309.000000 891.000000
mean 0.498854 0.383838
std 1.041658 0.486592
min 0.000000 0.000000
25% 0.000000 0.000000
50% 0.000000 0.000000
75% 1.000000 1.000000
max 8.000000 1.000000 乘客平均存活率约0.39,平均年龄约29.7岁
再看非数值型特征属性详情
all_data.describe(include=['O'])输出
Cabin Embarked Name Sex Ticket
count 295 1307 1309 1309 1309
unique 186 3 1307 2 929
top C23 C25 C27 S Kelly, Mr. James male CA. 2343
freq 6 914 2 843 11
使用图表直观分析数据,调用matplotlib库
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
………………
………………
………………
plt.show()
分别根据不同特征属性分析获救情况
def Survived():
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
# 查看总体获救情况
all_data['Survived'].value_counts().plot(kind='bar')
plt.title(u"是否获救情况(1为获救)")
plt.ylabel(u"人数")
Survived()
由于客观因素船上救生艇不足,导致大部分人没有获救
def Pclass():
# 查看不同Pclass获救情况
sur_pcl1 = all_data['Pclass'][all_data['Survived'] == 1].value_counts()
sur_pcl0 = all_data['Pclass'][all_data['Survived'] == 0].value_counts()
sur_pcl = pd.DataFrame({u'获救':sur_pcl1,u'未获救':sur_pcl0})
sur_pcl.plot(kind='bar', stacked=True)
plt.title(u"不同乘客等级的获救情况")
plt.xlabel(u"乘客等级")
plt.ylabel(u"人数")
Pclass()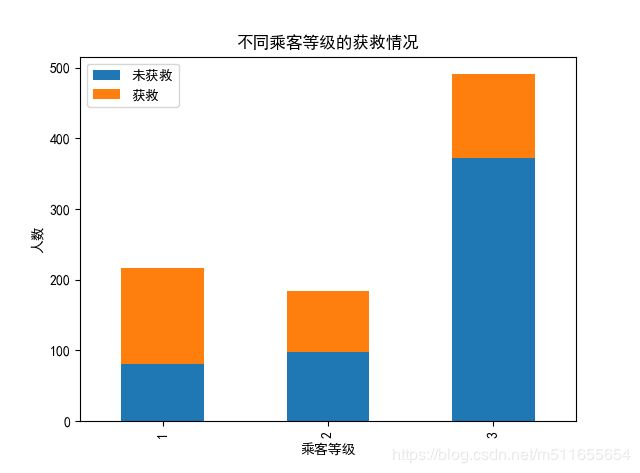
sns.barplot(x="Pclass", y="Survived", data=all_data) 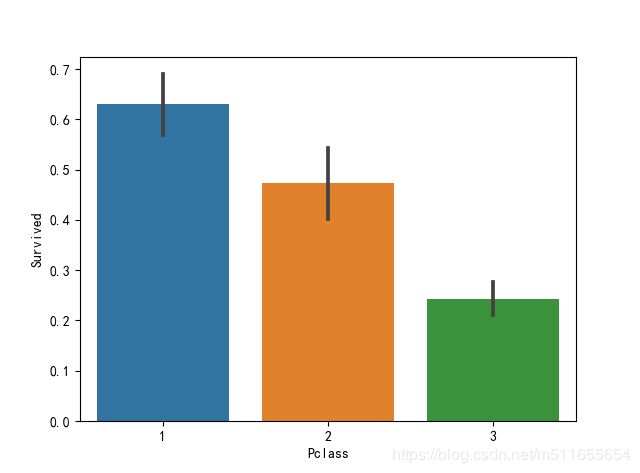
乘客等级为1的乘客获救率最高,社会等级高的人获救几率高
def Sex():
# 查看不同Sex获救情况
sur_sex1 = all_data['Sex'][all_data['Survived'] == 1].value_counts()
sur_sex0 = all_data['Sex'][all_data['Survived'] == 0].value_counts()
sur_sex = pd.DataFrame({u'获救':sur_sex1,u'未获救':sur_sex0})
print(sur_sex)
sur_sex.plot(kind='bar', stacked=True)
plt.title(u"不同性别的获救情况")
plt.xlabel(u"性别")
plt.ylabel(u"人数")
# # fig = plt.figure()(6)
Sex()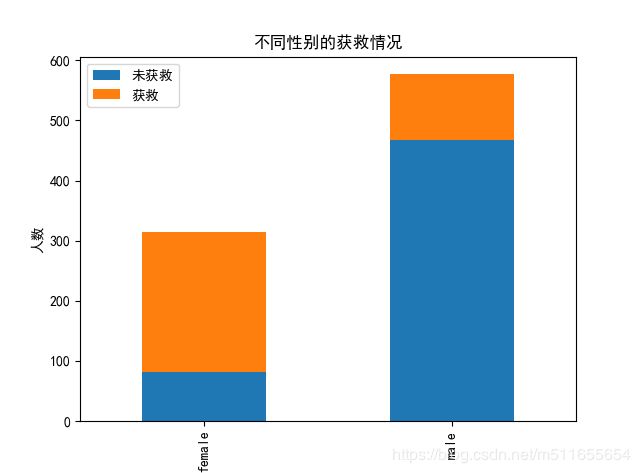
sns.barplot(x="Sex", y="Survived", data=all_data) 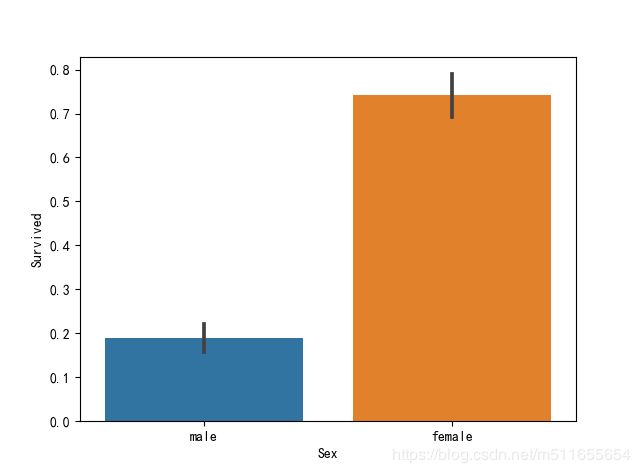
救援时先救女性,再救男性,所以女性存活率高
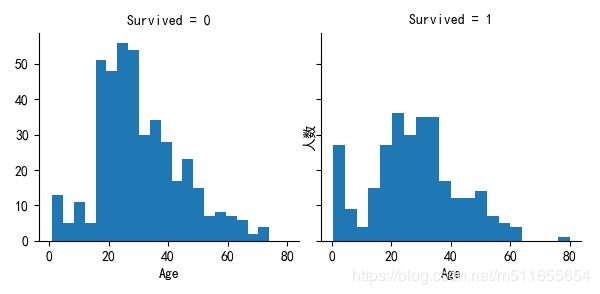
# 查看不同Age获救情况
sur_age = sns.FacetGrid(all_data, col='Survived')
sur_age.map(plt.hist, 'Age', bins=20)
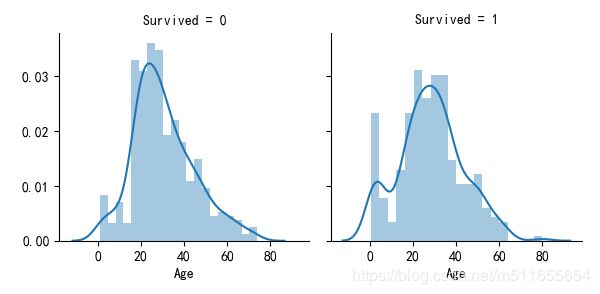
sur_age.map(sns.distplot, 'Age', bins=20)
sur_age = sns.FacetGrid(all_data, hue="Survived",aspect=2)
sur_age.map(sns.kdeplot,'Age',shade= True)
sur_age.set(xlim=(0, all_data['Age'].max()))
sur_age.add_legend()
plt.xlabel('Age')
plt.ylabel('density') 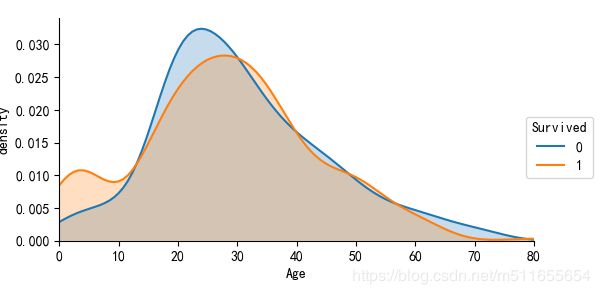
年龄小于15岁的存货超过半数,获救率更高,一般救援时,妇女儿童是首先需要救援的对象,也符合上面的规律
def Embarked():
# 查看不同Embarked获救情况
sur_emb1 = all_data['Embarked'][all_data['Survived'] == 1].value_counts()
sur_emb0 = all_data['Embarked'][all_data['Survived'] == 0].value_counts()
sur_emb = pd.DataFrame({u'获救':sur_emb1,u'未获救':sur_emb0})
sur_emb.plot(kind='bar', stacked=True)
plt.title(u"不同登陆港口的获救情况")
plt.xlabel(u"登陆港口")
plt.ylabel(u"人数")
Embarked()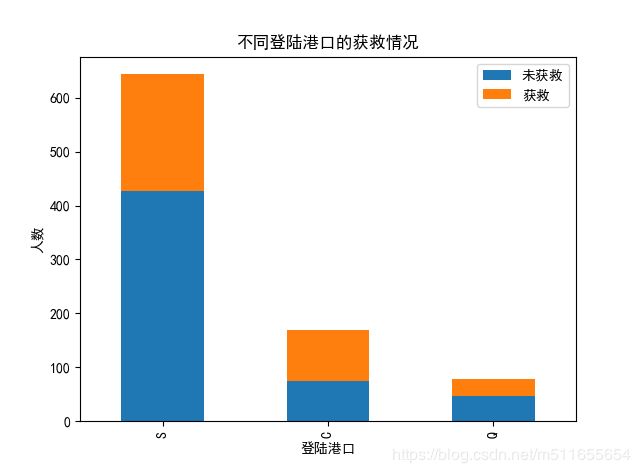
sns.barplot(x="Embarked", y="Survived", data=all_data) 
C港口登陆的乘客一半以上获救,获救率最高
sns.barplot(x="SibSp", y="Survived", data=all_data) 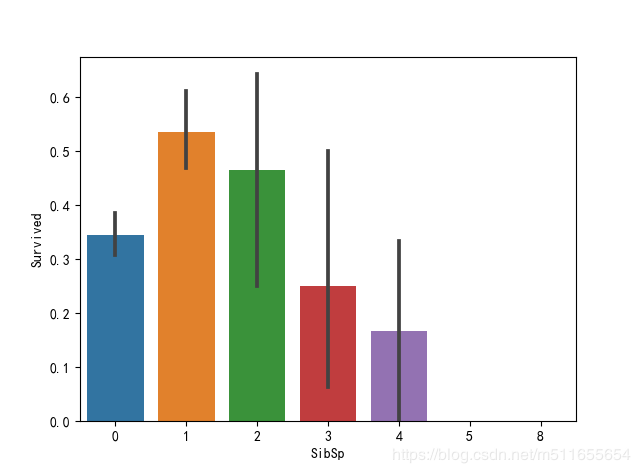
配偶和兄弟姐妹人数适中获救率更高
sns.barplot(x="Parch", y="Survived", data=all_data) 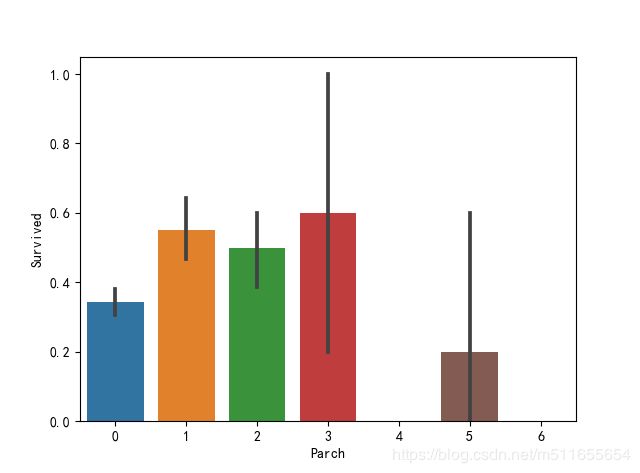
父母和子女人数适中获救率更高,但总体差异不大
# 查看不同Name的称呼的获救情况
all_data['Title'] = all_data['Name'].apply(lambda x:x.split(',')[1].split('.')[0].strip())
sns.barplot(x="Title", y="Survived", data=all_data) 
称谓包含这几种
{'Capt', 'Sir', 'Miss', 'Mlle', 'Don', 'Ms', 'Jonkheer', 'Mme', 'Col', 'Dr', 'Major', 'Rev', 'the Countess', 'Mrs', 'Lady', 'Master', 'Mr'}对其进行归类
Title_Dict = {}
Title_Dict.update(dict.fromkeys(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer'))
Title_Dict.update(dict.fromkeys(['Don', 'Sir', 'the Countess', 'Dona', 'Lady'], 'Royalty'))
Title_Dict.update(dict.fromkeys(['Mme', 'Ms', 'Mrs'], 'Mrs'))
Title_Dict.update(dict.fromkeys(['Mlle', 'Miss'], 'Miss'))
Title_Dict.update(dict.fromkeys(['Mr'], 'Mr'))
Title_Dict.update(dict.fromkeys(['Master','Jonkheer'], 'Master'))
all_data['Title'] = all_data['Title'].map(Title_Dict)
sns.barplot(x="Title", y="Survived", data=all_data)
除了之前分析的女性生存率高,登记时登记['Don', 'Sir', 'the Countess', 'Dona', 'Lady']的贵族生存率也很高
# 家庭成员数
all_data['FamilySize'] = all_data['SibSp'] + all_data['Parch'] + 1
sns.barplot(x="FamilySize", y="Survived", data=all_data) 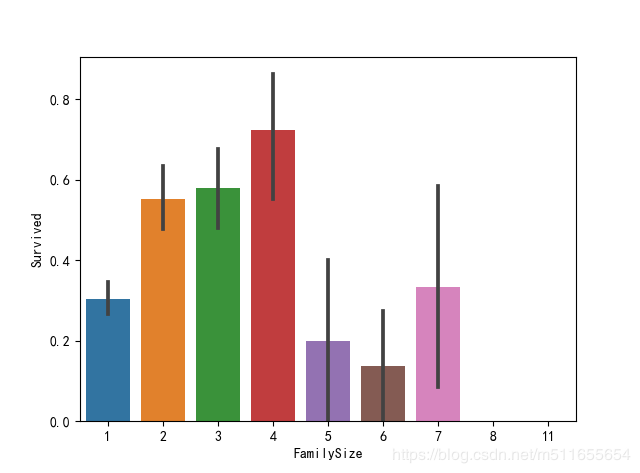
把家庭成员人数分成4类,单身狗、一般夫妻或一般家庭、兄弟姐妹孩子有点多家庭、大家族。。。
def Fam_label(s):
if (s == 1):
return 1
elif (2 <= s <= 4):
return 2
elif (4 < s <= 7):
return 3
elif (s > 7):
return 4
all_data['FamilyLabel'] = all_data['FamilySize'].apply(Fam_label)
sns.barplot(x="FamilyLabel", y="Survived", data=all_data) 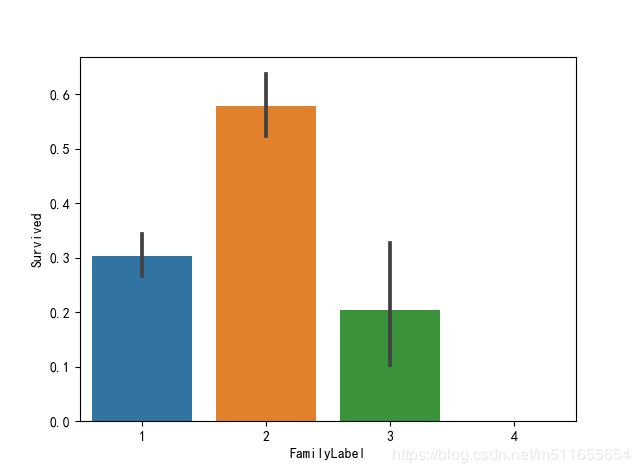
一般家庭生存率比较高
# 不同船舱分析
all_data['Cabin'] = all_data['Cabin'].fillna('Unknown')
all_data['Deck'] = all_data['Cabin'].str.get(0)
sns.barplot(x="Deck", y="Survived", data=all_data) 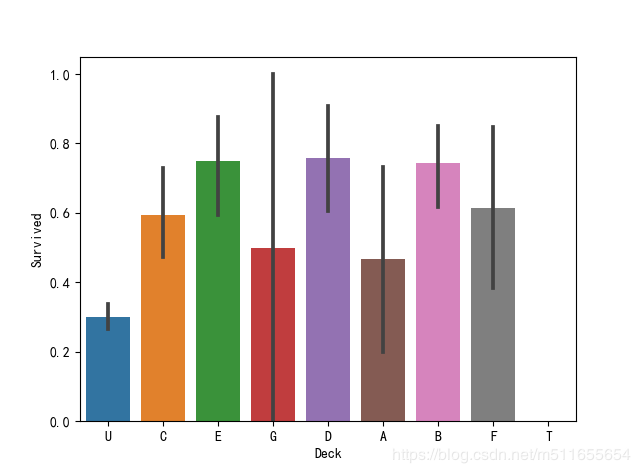
不同船舱距离救生船附近的距离不同,可能导致离得近的或者高级舱存活率高
# 共票人数分析
Ticket_Count = dict(all_data['Ticket'].value_counts())
all_data['TicketGroup'] = all_data['Ticket'].apply(lambda x:Ticket_Count[x])
sns.barplot(x='TicketGroup', y='Survived', data=all_data) 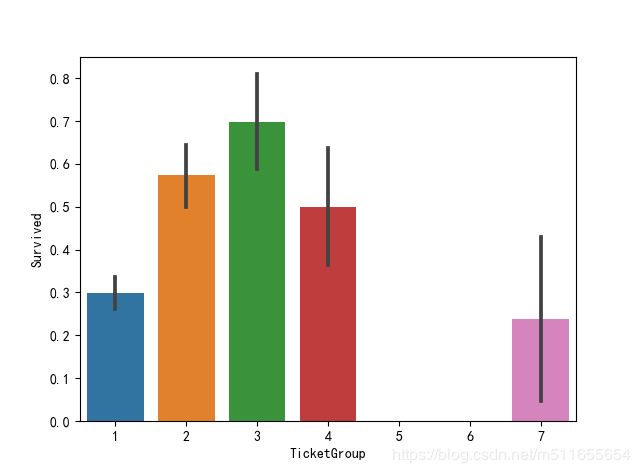
把共票人数分组
def Ticket_Label(s):
if (s == 1):
return 1
elif (2 <= s <= 4):
return 2
elif (4 < s <= 7):
return 3
elif (s > 7):
return 4
all_data['TicketGroup'] = all_data['TicketGroup'].apply(Ticket_Label)
sns.barplot(x='TicketGroup', y='Survived', data=all_data) 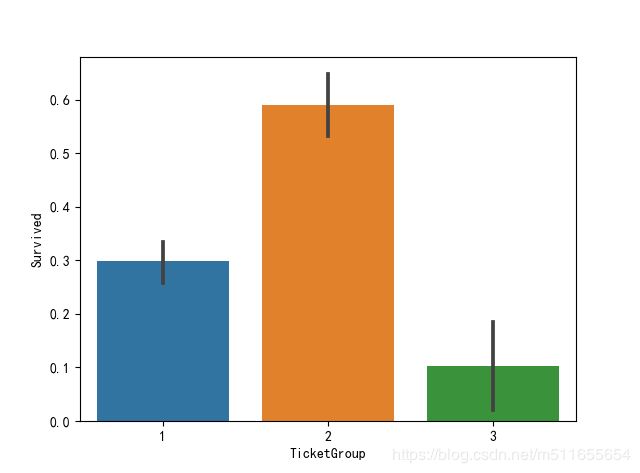
一般共票的都是家庭票居多
3、数据清洗
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 12 columns):
Age 1046 non-null float64
Cabin 295 non-null object
Embarked 1307 non-null object
Fare 1308 non-null float64
Name 1309 non-null object
Parch 1309 non-null int64
PassengerId 1309 non-null int64
Pclass 1309 non-null int64
Sex 1309 non-null object
SibSp 1309 non-null int64
Survived 891 non-null float64
Ticket 1309 non-null object
dtypes: float64(3), int64(4), object(5)
memory usage: 122.8+ KB Age缺失值较多,缺少1309-1046=263,需要补值,此处采用随机森林生成空值的方法,选取Pcalss、Sex、Title三个特征建模
from sklearn.ensemble import RandomForestRegressor
age_df = all_data[['Age', 'Pclass','Sex','Title']]
# 利用get_dummies()进行独热编码,将拥有不同值的变量转换为0/1数值
age_df = pd.get_dummies(age_df)
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
y = known_age[:, 0]
X = known_age[:, 1:]
# 随机森林,n_estimators建立子树的数量,random_state指定随机生成一个确定的结果,n_jobs使用多少引擎处理
rfr = RandomForestRegressor(random_state=0, n_estimators=100, n_jobs=-1)
rfr.fit(X, y)
predictedAges = rfr.predict(unknown_age[:, 1::])
all_data.loc[ (all_data.Age.isnull()), 'Age' ] = predictedAgesEmbarked的缺失值很少,缺少2个,打印相关信息
TicketGroup()
output:
Age Cabin Embarked Fare Name \
61 38.0 B28 NaN 80.0 Icard, Miss. Amelie
829 62.0 B28 NaN 80.0 Stone, Mrs. George Nelson (Martha Evelyn)
Parch PassengerId Pclass Sex SibSp Survived Ticket Title \
61 0 62 1 female 0 1.0 113572 Miss
829 0 830 1 female 0 1.0 113572 Mrs
FamilySize FamilyLabel Deck TicketGroup
61 1 1 B 2
829 1 1 B 2 这两位都是Pclass=1,女性,共票,Fare=80,Cabin=B28 ,SibSp=0,Parch=0,推测两个人可能是认识的
sns.countplot('Embarked',hue='Survived',data=all_data)
print(all_data.describe())
output:
Age Fare Parch PassengerId Pclass \
count 1309.000000 1308.000000 1309.000000 1309.000000 1309.000000
mean 29.519228 33.295479 0.385027 655.000000 2.294882
std 13.417745 51.758668 0.865560 378.020061 0.837836
min 0.170000 0.000000 0.000000 1.000000 1.000000
25% 21.000000 7.895800 0.000000 328.000000 2.000000
50% 28.226256 14.454200 0.000000 655.000000 3.000000
75% 36.500000 31.275000 0.000000 982.000000 3.000000
max 80.000000 512.329200 9.000000 1309.000000 3.000000
SibSp Survived FamilySize FamilyLabel TicketGroup
count 1309.000000 891.000000 1309.000000 1309.000000 1309.000000
mean 0.498854 0.383838 1.883881 1.473644 1.568373
std 1.041658 0.486592 1.583639 0.658014 0.716308
min 0.000000 0.000000 1.000000 1.000000 1.000000
25% 0.000000 0.000000 1.000000 1.000000 1.000000
50% 0.000000 0.000000 1.000000 1.000000 1.000000
75% 1.000000 1.000000 2.000000 2.000000 2.000000
max 8.000000 1.000000 11.000000 4.000000 4.000000
打印出不同Pclass、Embarked的票价中位数
print(all_data.groupby(by=["Pclass","Embarked"]).Fare.median())
output:
Pclass Embarked
1 C 76.7292
Q 90.0000
S 52.0000
2 C 15.3146
Q 12.3500
S 15.3750
3 C 7.8958
Q 7.7500
S 8.0500
Name: Fare, dtype: float64输出可以看出,Pclass=1、Fare=80的人群中,大概率从Embarked=C港口出发,填充C
all_data['Embarked'] = all_data['Embarked'].fillna('C')Cabin字段缺失值较多,考虑一部分确实可能是船上工作人员的房间,此处不作为特征进行预测,
4、建模预测
后续根据需要进行建模预测,选择随机森林、SVM等……