【论文笔记】CVPR 2017 ORAL --MDNET
最近一直在看的一篇论文,因为要做的方向基本和他类似,并且我们做的一些工作也是在他的基础上实现的。所以这篇文章我会看的很仔细,也做了大量的思考笔记,但我想,毕竟医疗图像领域的做的人会少一些,所以看的人也估计不是太多,anyway,也算是自己思路在重新梳理一遍。
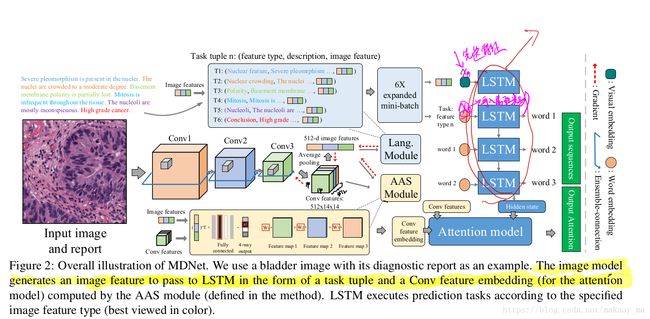
MDNET: 他实现的主要功能,主要就是三个部分:IMage_model,attention_model,language_model .这三个model是被集成在一个网络中的(end to end )。实现了由cnn提取特征,然后分属性标签送入lstm,得到对于一张病理图片的诊断报告以及诊断结论,并且在图片上可视化注意力区域,对于病理图像的诊断报告给予可解释性视觉支持。并且尽可能的提高诊断结论的判断。
首先,我觉得读懂这篇论文基础是建立在:
1. xu (2015)的show and tell 以及show attent and tell 这两篇论文是读懂这篇论文的关键,这两篇论文在csdn上已经有很多解释了,这里我就不在详细复述了。
2 由于我们的复现此篇论文的相关工作是建立pytorch基础上的,所以采用的基础代码是交大的若天学长
接下里就是正文部分,大致顺着MD论文的行文思路来解释下整篇论文。
Abstract:
这里主要是大致解释了下MDnet 的论文功能: MDnet 在病理图片以及诊断报告之间建立了多重的映射关系,这个网络可以读图,然后产生相应的诊断报告,并且可以产生注意力区域,为诊断过程提供相应的视觉可解释性。并且整个网络是端到端的进行,他们建立了自己的数据集,基于膀胱病理学的图片和诊断报告,并且夸自己的模型取得了“国家级的艺术表现”在cifar数据集上。

1 / Introduction/
大致介绍了下目前深度学习的应用场景以及现状(虽然都是废话,不过还是得说)。
然后指出现在给出诊断模型的常用的是分类,但是呢,分类存在缺点:1)这种分类模型掩盖了得到结论的根本逻辑性,并且缺少对他们下诊断结论的支持过程。所以呢,在医学上,最重要的还是语义解释以及视觉解释并存的方式是比较好的。
然后解释了下,病理图像和自然图像的区别,这样的话,我们只能采用MDnet的方法去实现相关的病理诊断。同时,他们介绍了下相关的数据集:细胞核的改变,密度的改变,以及xx的改变都会导致癌变的发生。 但是呢,对于医生来说,就算是很专业的医生,他们也无法明确的描述他们怎么诊断的相关过程,(makaay内心OS:原来医生的诊断过程也是黑箱操作啊,哈哈哈,不过从我们和上海相关医院的联系了解来看,这个确实可信,都是基于大量的经验来判断的)。所以我们需要用机器学习的方法,来尽可能支持医生的诊断结论,MDnet在于挖掘最具有判别力的信息(从诊断报告中挖掘),而且这些特征,在诊断报告中是隐含的,不明确的。(makaay内心:可能他是想说,数据集是没有bbox等位置信息的标注的)。

接下里是介绍具体的模型,cnn部分使用的的是resnet 然后语言模型部分采用的是LSTM,这里都是些常规的模型操作,和ruotian学长复现的模型都是一样的。但是他们在lstm的部分进行的相关的变化,这个后面我会详细的结束。
2 /Related Work/
在这里,作者就介绍了现在大家基本都是采用images和language的模型进行操作,然后介绍了相关了一些网络,比如cnn部分的Googlenet,以及语言模型的RNN等等。同时,作者也提到了,在自然图像领域,使用预先训练的CNN模型,能够提高相应的表现,但是在病理图像领域,这种预先训练的模型并不能带来相关的表现提升。然后又解释了下注意力区域的必要性,并且,给出了to date,病理领域就只有放射线的那个(数据集公开了好像)。接下里又解释了下,resnet的skip-connection的作用,反正就是表现很好,(当然我们实验室的师兄复现的时候也采用了相应的操作。)
3 /Image model/
主要介绍了resnet的相关过程,然后在描述了他们在resnet上进行的更改,直接后面的直接进行全连接,也就是文章中提到的ensemble-connection。
(makaay注:因为这里从文章中得到,采用这样的更改,只在数据集上取得大概1%的提升,所以我们师兄在复现做的的时候并没有采用他们的思路,而是直接使用的resnet,这里不做太多的赘述)
4/Language modeling and network training /
语言模型中,我们常常采用LSTM来进行输出诊断报告,这里输出的时候采用的是 输出的单词在单词表中的概率。

(makaay:就比如若天学长复现的代码中,采用的coco数据集,共有9867个单词,而我们会得到一个1x9867的向量,里面分别填写了每个单词的概率。当然这已经是从512维的向量映射到词空间以后的事情了)
接下来作者提到了show attent and tell 这篇论文,他们采用的了其中的“soft”方式。就是我们从会从image中的特征和相应的权重相乘,会得到一个Zt,这里面包含了图片特征,然后我们会把这个和单词信息进行连接,和h一起作为输入,然后送到LSTM进行训练。
但是呢,作者在这里也发现了show attent and tell 的问题,发现很难训练,因为和结论并不相符,于是呢,他们就提出(AAS)模块,也是就是CNN输出的特征能够更加靠近最后的结论,然后取出这个单独的代表最后结论的向量(假如结论分为4类,从全连接层取出第三类的向量),然后在进行LSTm的操作,这样的话,我的结论会会更加靠近最后的诊断结论。
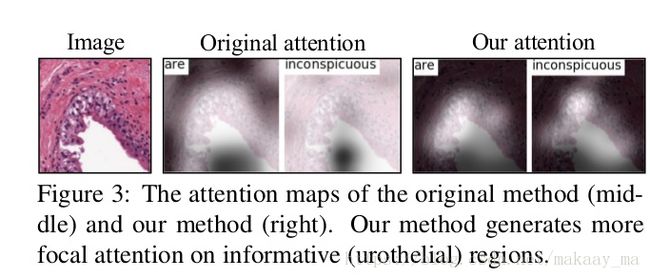
经过这么操作以后,作者给出了最后的与show attent and tell 的相关对比,确实变得更加准确了,这个全是因为ASS。
然后作者又对LSTM输入的顺序进行了相关的操作,对每一个属性输入的时候提前告知LSTM,我现在输入的是属性1还是属性2,这样的话,使的报告输出的话能够更加接近属性类别的顺序。
并且在4.3中,作者提到了联合训练的过程,就是使用两个部分的loss合并,然后一起进行反向传播,并且给每一个部分的loss 设置参数,使得前期的时候,模型更加专注的是提取特征,然后后期的时候,专注得到最后的诊断结论。
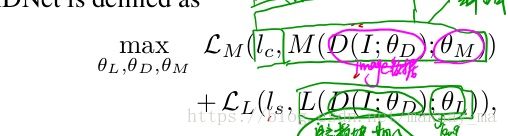

5/Experimental Result/
由于作者更改了resnet,所以他们使用更改的resnet在cifar10以及cifar100进行测试,发现自己的模型牛(hhhh,这个是肯定的,我没具体关注,可以看作者在cvpr上的oral报告,里面讲了怎么操作)

然后呢,就是在他们自己数据集上的测试结果,是跟语言模型 netualtalk2进行对比,发现自己的比较牛。
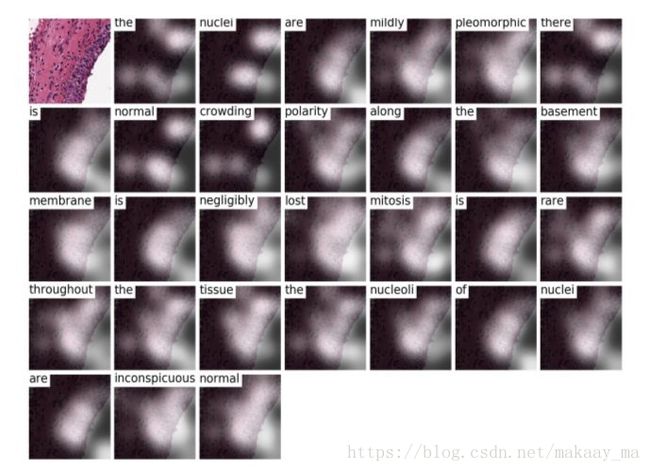
并且给出了两种展示模式。一种来自AAS的模块,一块来自最后的语言模块。
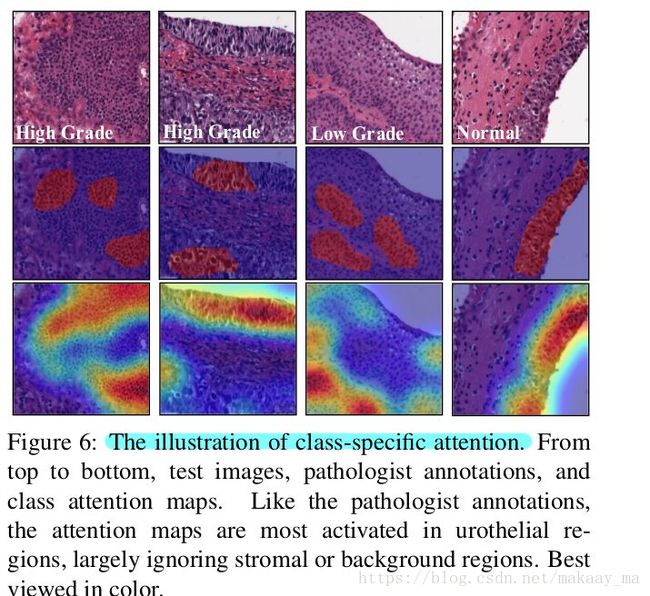
以上便是论文的关键部分的解释,差不多就这样了,我们对此进行了大部分内容的复现,复现的内容建立在若天学长
下面是大概的思路图,不会给的很详细,毕竟还有很多工作是没有完成的。有问题可以多多交流。
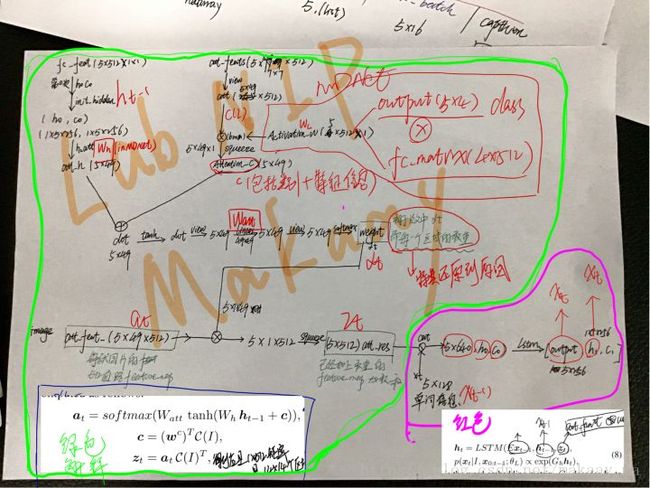
这篇论文是我最近看的比较仔细的一篇文章了,还请各位多给我提提意见什么的。
/纸上得来终觉浅,绝知此事要躬行/
以上。