集成学习——组合不同的模型
集成学习(ensemble method)的目标是:将不同的分类器组合成为一个元分类器,与包含于其中的单个分类器相比,元分类器具有更好的泛化性能。
多数投票原则(majority voting):将大多数分类器预测的结果作为最终类标,也就是说,将得票率超过50%的结果作为类标。多类标分类选择得票最多的类别。

基于训练集,首先训练 m 个不同的成员分类器 (C1,...,Cm) ( C 1 , . . . , C m ) ,在多数投票原则下,可集成不同的分类算法,,如决策树、支持向量机、逻辑回归等。此外,也可以使用相同的成员分类算法拟合不同的训练子集,这种方法典型的例子就是随机森林算法,它组合了不同的决策树分类器。

想要通过简单的多数投票原则对类标进行预测,要汇总所有分类器 Cj C j 的预测类标,并选出得票率最高的类别 y^ y ^ :

假定二类别分类中的 n 个成员分类器都有相同的出错率 ε ε ,此外,假定每个分类器都是独立的,且出错率之间是不相关的。基于这些假设,可以将成员分类器集成后的出错概率简单地表示为二项分布的概率密度函数:

from scipy.misc import comb
import math
def ensemble_error(n_classifier, error):
k_start = math.ceil(n_classifier / 2.0)
probs = [comb(n_classifier, k) * error ** k * (1 - error) ** (n_classifier - k) for k in range(k_start, n_classifier + 1)]
return sum(probs)
print(ensemble_error(n_classifier=11, error=0.25))执行结果如下:
0.03432750701904297实现 ensemble_error 函数后,在成员分类器出错概率介于0.0到1.0范围内,可以计算对应集成分类器的出错率。
import numpy as np
error_range = np.arange( 0.0, 1.0, 0.01)
ens_error = [ensemble_error(n_classifier=11, error=error) for error in error_range]
import matplotlib.pyplot as plt
plt.plot(error_range, ens_error, label='Ensemble error', linewidth=2)
plt.plot(error_range, error_range, linestyle='--', label='Base error', linewidth=2)
plt.xlabel('Base error')
plt.ylabel('Base/Ensemble error')
plt.legend(loc='upper left')
plt.grid()
plt.show()
从图中可见,当成员分类器出错率低于随机猜测时( ε<0.5 ε < 0.5 ),集成分类器的出错率要低于单个分类器。
实现简单多数投票分类器
集成算法允许我们使用单独的权重对不同算法进行组合。我们的目标是构建一个更加强大的元分类器,以特定的数据集上平衡单个分类器的弱点。通过更严格的数学概念,可将加权多数投票记为:

其中, wj w j 是成员分类器 Cj C j 对应的权重, y^ y ^ 为集成分类器的预测类标, χA χ A 为特征函数 [Cj(x)=i∈A] [ C j ( x ) = i ∈ A ] , A A 为类标的集合。
import numpy as np
print(np.argmax(np.bincount([0, 0, 1], weights=[0.2, 0.2, 0.6])))执行结果如下:
1scikit-learn 中的分类器可以返回样本属于预测类标的概率。如果集成分类器事先得到良好的修正,那么多数投票中使用预测类别的概率来替代类标会非常有用。使用类别概率进行预测的多数投票修改版本可记为:

其中, pij p i j 是第 j j 个分类器预测样本 i i 的概率。
假定有三个成员分类器 Cj(j∈1,2,3) C j ( j ∈ 1 , 2 , 3 ) ,分别用它们来预测样本 x x 的类标。
C1,C2 C 1 , C 2 的权重均为0.2, C3 C 3 的权重为0.6。下面集成这三个分类器,假定分类器 Cj C j 针对某一样本 x x 按照如下概率返回类标的预测结果:

ex = np.array([[0.9, 0.1],
[0.8, 0.2],
[0.4, 0.6]])
p = np.average(ex, axis=0, weights=[0.2, 0.2, 0.6])
print(p)
print(np.argmax(p))执行结果如下:
[0.58 0.42]
0python实现 MajorityVoteClassifier 类:
from sklearn.base import BaseEstimator
from sklearn.base import ClassifierMixin
from sklearn.preprocessing import LabelEncoder
from sklearn.externals import six
from sklearn.base import clone
from sklearn.pipeline import _name_estimators
import numpy as np
import operator
class MajorityVoteClassifier(BaseEstimator, ClassifierMixin):
"""
A majority vote ensemble classifier
Parameters
----------
classifiers: array-like, shape = [n_classifiers]
Different classifiers for ensemble
vote: str, {'classlabel', 'probability'}
Default: 'classlabel'
If 'classlabel' the prediction is based on the
argmax of class labels. Else if 'probability',
the argmax of the sum of probabilities is used
to predict the class label(recommended for calibrated
classifiers).
weights: array-like, shape = [n_classifiers]
Optional, default: None
If a list of 'int' or 'float' values are provided, the
classifiers are weighted by importance; Uses uniform
weights if 'weights=None'.
"""
def __init__(self, classifiers, vote='classlabel', weights=None):
self.classifiers = classifiers
self.named_classifiers = {key: value for key, value in _name_estimators(classifiers)}
self.vote = vote
self.weights = weights
def fit(self, X, y):
"""
Fit classifiers.
Parameters
----------
X: {array-like, sparse matrix}, shape = [n_samples, n_features]
Matrix of training samples.
y: array-like, shape = [n_samples]
Vector of target class labels.
Returns
-------
self: object
"""
# Use LabelEncoder to ensure class labels start with 0, which is
# important for np.argmax call in self.predict
self.labelenc_ = LabelEncoder()
self.labelenc_.fit(y)
self.classes_ = self.labelenc_.classes_
self.classifiers_ = []
for clf in self.classifiers:
fitted_clf = clone(clf).fit(X, self.labelenc_.transform(y))
self.classifiers_.append(fitted_clf)
return self
def predict_proba(self, X):
"""
Predict class probabilities fo X.
Parameters
----------
X: {array-like, sparse matrix}, shape = [n_samples, n_features]
Training vectors, where n_samples is the number of samples and
n_features is the number of features.
Returns
-------
avg_proba: array-like, shape = [n_samples, n_classes]
Weighted average probability for each class per sample.
"""
probas = np.asarray([clf.predict_proba(X) for clf in self.classifiers_])
avg_proba = np.average(probas, axis=0, weights=self.weights)
return avg_proba
def predict(self, X):
"""
Predict class labels for X.
Parameters
----------
X: {array-like, sparse matrix}, shape = [n_samples, n_features]
Matrix of training samples.
Returns
-------
maj_vote: array-like, shape = [n_samples]
Predicted class labels.
"""
if self.vote == 'probability':
maj_vote = np.argmax(self.predict_proba(X), axis=1)
else: # 'classlabel' vote
# Collect results from clf.predict calls
predictions = np.asarray([clf.predict(X) for clf in self.classifiers_]).T
maj_vote = np.apply_along_axis(lambda x: np.argmax(np.bincount(x, weights=self.weights)), axis=1, arr=predictions)
maj_vote = self.labelenc_.inverse_transform(maj_vote)
return maj_vote
def get_params(self, deep=True):
"""
Get classifier parameter names for GridSearch
"""
if not deep:
return super(MajorityVoteClassifier, self).get_params(deep=False)
else:
out = self.named_classifiers.copy()
for name, step in six.iteritems(self.named_classifiers):
for key, value in six.iteritems(step.get_params(deep=True)):
out['%s_%s' % (name, key)] = value
return out
基于多数投票原则组合不同的分类算法
from sklearn import datasets
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
iris = datasets.load_iris()
X, y = iris.data[50:, [1, 2]], iris.target[50:]
le = LabelEncoder()
y = le.fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=1)使用 predict_proba 计算概率值:决策树中,此概率是通过训练时为每个节点创建的频度向量(frequency vector)来计算,此向量收集对应节点中通过类标分布计算得到各类标频率值,进而频率归一化处理,使得它们的和为1。k 近邻算法中,收集各样本最相邻的 k 个邻居的类标,并返回归一化的类标频率。虽然决策树和 k 近邻分类器都返回了与逻辑回归模型类似的概率值,但是,这些值并非通过概率密度函数计算得到。
from sklearn.cross_validation import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import Pipeline
import numpy as np
clf1 = LogisticRegression(penalty='l2', C=0.001, random_state=0)
clf2 = DecisionTreeClassifier(max_depth=1, criterion='entropy', random_state=0)
clf3 = KNeighborsClassifier(n_neighbors=1, p=2, metric='minkowski')
pipe1 = Pipeline([
('sc', StandardScaler()),
('clf', clf1)
])
pipe3 = Pipeline([
('sc', StandardScaler()),
('clf', clf3)
])
clf_labels = ['Logistic Regression', 'Decision Tree', 'KNN']
print('10-fold cross validation:\n')
for clf, label in zip([pipe1, clf2, pipe3], clf_labels):
scores = cross_val_score(estimator=clf, X=X_train, y=y_train, cv=10, scoring='roc_auc')
print('ROC AUC: %.2f (+/- %.2f) [%s]' % (scores.mean(), scores.std(), label))
使用训练数据集训练三种不同类型的分类器:逻辑回归分类、决策树分类器及 k 近邻分类器。
执行结果如下:
10-fold cross validation:
ROC AUC: 0.92 (+/- 0.20) [Logistic Regression]
ROC AUC: 0.92 (+/- 0.15) [Decision Tree]
ROC AUC: 0.93 (+/- 0.10) [KNN]不同于决策树,逻辑回归与 k 近邻算法并不是 scale-invariant,所以需要对特征进行标准化处理。
基于多数投票原则,在 MajorityVoteClassifier 中组合各成员分类器:
mv_clf = MajorityVoteClassifier(classifiers=[pipe1, clf2, pipe3])
clf_labels += ['Majority Voting']
all_clf = [pipe1, clf2, pipe3, mv_clf]
for clf, label in zip(all_clf, clf_labels):
scores = cross_val_score(estimator=clf, X=X_train, y=y_train, cv=10, scoring='roc_auc')
print('Accuracy: %.2f (+/- %.2f) [%s]' % (scores.mean(), scores.std(), label))执行结果如下:
Accuracy: 0.92 (+/- 0.20) [Logistic Regression]
Accuracy: 0.92 (+/- 0.15) [Decision Tree]
Accuracy: 0.93 (+/- 0.10) [KNN]
Accuracy: 0.97 (+/- 0.10) [Majority Voting]可见,以10-fold 交叉验证作为评估标准,MajorityVoteClassifier 的性能与单个成员分类器相比有着质的提高。
评估与调优集成分类器
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
colors = ['black', 'orange', 'blue', 'green']
linestyle = [':', '--', '-.', '-']
for clf, label, clr, ls in zip(all_clf, clf_labels, colors, linestyle):
# assuming the label of the positive class is 1
y_pred = clf.fit(X_train, y_train).predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_true=y_test, y_score=y_pred)
roc_auc = auc(x=fpr, y=tpr)
plt.plot(fpr, tpr, color=clr,linestyle=ls, label='%s (auc = %.2f)' % (label, roc_auc))
plt.legend(loc='lower right')
plt.plot([0, 1], [0, 1], linestyle='--', color='gray', linewidth=2)
plt.xlim([-0.1, 1.1])
plt.ylim([-0.1, 1.1])
plt.grid()
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()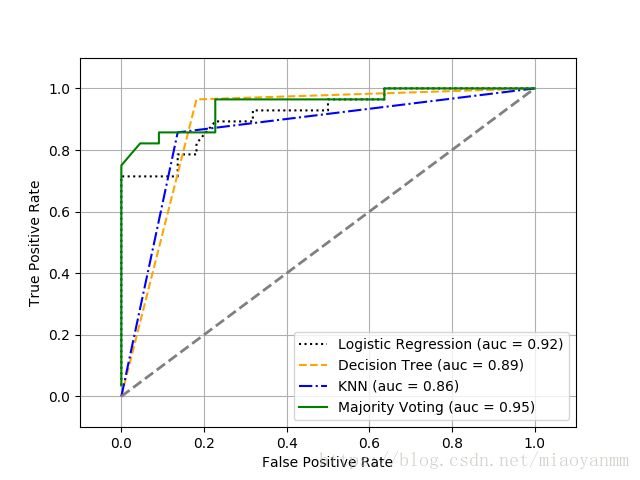
由 ROC 结果可以看到,集成分类器在测试集上表现优秀(ROC AUC=0.95),而 k 近邻分类器对于训练数据有些过拟合(训练集上的ROC AUC=0.93,测试集上的ROC AUC=0.86)
绘制分类器决策区域
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
from itertools import product
x_min = X_train_std[:, 0].min() - 1
x_max = X_train_std[:, 0].min() + 1
y_min = X_train_std[:, 1].min() - 1
y_max = X_train_std[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1), np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=2, ncols=2, sharex='col', sharey='row', figsize=(7, 5))
for idx, clf, tt in zip(product([0, 1], [0, 1]), all_clf, clf_labels):
clf.fit(X_train_std, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx[0], idx[1]].contourf(xx, yy, Z, alpha=0.3)
axarr[idx[0], idx[1]].scatter(X_train_std[y_train == 0, 0], X_train_std[y_train == 0, 1],
c='blue', marker='^', s=50)
axarr[idx[0], idx[1]].scatter(X_train_std[y_train == 1, 0], X_train_std[y_train == 1, 1],
c='red', marker='o', s=50)
axarr[idx[0], idx[1]].set_title(tt)
plt.text(-3.5, -4.5, s='Sepal width [standardized]', ha='center', va='center', fontsize=12)
plt.text(-10.5, 4.5, s='Patal length [standardized]', ha='center', va='center', fontsize=12, rotation=90)
plt.show()
调用 get_param 方法,访问 GridSearch 对象内的参数:
print(mv_clf.get_params())执行结果如下:
{'pipeline-1_clf__verbose': 0, 'pipeline-1_sc': StandardScaler(copy=True, with_mean=True, with_std=True), 'pipeline-1_steps': [('sc', StandardScaler(copy=True, with_mean=True, with_std=True)), ('clf', LogisticRegression(C=0.001, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=0, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False))], 'pipeline-1_sc__with_mean': True, 'pipeline-2_memory': None, 'decisiontreeclassifier_splitter': 'best', 'pipeline-2': Pipeline(memory=None,
steps=[('sc', StandardScaler(copy=True, with_mean=True, with_std=True)), ('clf', KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform'))]), 'decisiontreeclassifier_max_depth': 1, 'decisiontreeclassifier_min_impurity_decrease': 0.0, 'pipeline-1_clf__solver': 'liblinear', 'decisiontreeclassifier_max_leaf_nodes': None, 'decisiontreeclassifier_presort': False, 'decisiontreeclassifier_min_weight_fraction_leaf': 0.0, 'pipeline-2_clf__leaf_size': 30, 'pipeline-1_clf__warm_start': False, 'decisiontreeclassifier_max_features': None, 'pipeline-1_clf': LogisticRegression(C=0.001, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=0, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False), 'pipeline-2_clf__metric': 'minkowski', 'pipeline-2_sc__copy': True, 'pipeline-2_clf__n_neighbors': 1, 'pipeline-2_sc__with_mean': True, 'pipeline-1_clf__max_iter': 100, 'pipeline-1_memory': None, 'pipeline-1_sc__copy': True, 'pipeline-2_sc': StandardScaler(copy=True,with_mean=True, with_std=True), 'pipeline-1_clf__fit_intercept': True, 'pipeline-2_clf__metric_params': None, 'pipeline-2_clf__n_jobs': 1, 'pipeline-1_clf__n_jobs': 1, 'pipeline-1': Pipeline(memory=None,
steps=[('sc', StandardScaler(copy=True, with_mean=True, with_std=True)), ('clf', LogisticRegression(C=0.001, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=0, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False))]), 'pipeline-2_clf__p': 2, 'pipeline-1_clf__multi_class': 'ovr', 'pipeline-1_clf__tol': 0.0001, 'decisiontreeclassifier_class_weight': None, 'pipeline-2_clf__algorithm': 'auto', 'pipeline-1_clf__class_weight': None, 'pipeline-1_clf__intercept_scaling': 1, 'decisiontreeclassifier': DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=1,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=0,
splitter='best'), 'decisiontreeclassifier_min_impurity_split': None, 'pipeline-1_clf__penalty': 'l2', 'pipeline-1_clf__dual': False, 'pipeline-1_clf__random_state': 0, 'decisiontreeclassifier_random_state': 0, 'pipeline-2_clf': KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform'), 'pipeline-2_sc__with_std': True, 'decisiontreeclassifier_min_samples_split': 2, 'pipeline-2_steps': [('sc', StandardScaler(copy=True, with_mean=True, with_std=True)), ('clf', KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform'))], 'pipeline-1_sc__with_std': True, 'decisiontreeclassifier_criterion': 'entropy', 'pipeline-1_clf__C': 0.001, 'decisiontreeclassifier_min_samples_leaf': 1, 'pipeline-2_clf__weights': 'uniform'}得到 get_params 方法的返回值后,便可以访问成员分类器的属性额。
from sklearn.grid_search import GridSearchCV
params = {'decisiontreeclassifier__max_depth': [1, 2],
'pipeline-1__clf__C': [0.001, 0.1, 100.0]}
grid = GridSearchCV(estimator=mv_clf, param_grid=params, cv=10, scoring='roc_auc')
grid.fit(X_train, y_train)
for params, mean_score, scores in grid.grid_scores_:
print('%.3f+/-%.2f %r' % (mean_score, scores.std() / 2, params))
print('Accuracy: %.2f' % (grid.best_score_))执行结果如下:
0.967+/-0.05 {'decisiontreeclassifier__max_depth': 1, 'pipeline-1__clf__C': 0.001}
0.967+/-0.05 {'decisiontreeclassifier__max_depth': 1, 'pipeline-1__clf__C': 0.1}
1.000+/-0.00 {'decisiontreeclassifier__max_depth': 1, 'pipeline-1__clf__C': 100.0}
0.967+/-0.05 {'decisiontreeclassifier__max_depth': 2, 'pipeline-1__clf__C': 0.001}
0.967+/-0.05 {'decisiontreeclassifier__max_depth': 2, 'pipeline-1__clf__C': 0.1}
1.000+/-0.00 {'decisiontreeclassifier__max_depth': 2, 'pipeline-1__clf__C': 100.0}
Accuracy: 1.00正如结果所示,当选择正则化强度较小时(C = 100.0),能够得到最佳的交叉验证结果,而决策树的深度似乎对性能没有任何影响,这意味着使用单层决策树足以对数据进行划分。
上面实现的多数投票方法有时也称为堆叠(stacking)。不过,堆叠算法更典型地应用于组合逻辑回归模型,以各独立分类器的输出作为输入,通过对这些输入结果的继承来预测最终的类标。
bagging——通过 bootstrap 样本构建集成分类器
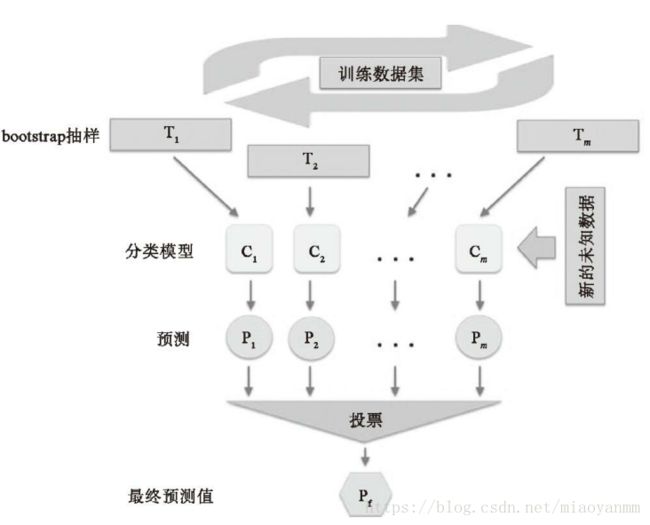
此算法没有使用相同的训练集拟合集成分类器中的单个成员分类器。由于原始训练集使用了bootstrap 抽样(有放回的随机抽样),这也是 bootstrap 被称为bootstrap aggregating 的原因。

如上图,7个不同的训练样例(使用索引1~7来表示),在每一轮的 bagging 循环中,它们都被可放回随机抽样。每个 bootstrap 抽样都被用于分类器 Cj C j 的训练,这就是一棵典型的未剪枝的决策树。
实际上,随机森林是 bagging 的一个特例,它使用了随机的特征子集去拟合单棵决策。bagging 可以提高不稳定模型的准确率,并且可以降低拟合的程度。
import pandas as pd
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data', header=None)
df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins',' Color intensity', 'Hue', 'OD280/oD315 of diluted wines',
'Proline']
df_wine = df_wine[df_wine['Class label'] != 1]
y = df_wine['Class label'].values
X = df_wine[['Alcohol', 'Hue']].values
from sklearn.preprocessing import LabelEncoder
from sklearn.cross_validation import train_test_split
le = LabelEncoder()
y = le.fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.40, random_state=1)
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy', max_depth=None)
bag = BaggingClassifier(base_estimator=tree, n_estimators=500, max_samples=1.0, max_features=1.0, bootstrap=True,
bootstrap_features=False, n_jobs=1, random_state=1)
从 sklearn 中的 ensemble 子模块导入 BaggingClassifier 算法。使用未经剪枝的决策树作为成员分类器,并在训练数据集上通过不同的 bootstrap 抽样拟合 500 棵决策树。
比较 bagging 分类器与单棵未经剪枝决策树的性能:
from sklearn.metrics import accuracy_score
tree = tree.fit(X_train, y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train, y_train_pred)
tree_test = accuracy_score(y_test, y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train, tree_test))
bag = bag.fit(X_train, y_train)
y_train_pred = bag.predict(X_train)
y_test_pred = bag.predict(X_test)
bag_train = accuracy_score(y_train, y_train_pred)
bag_test = accuracy_score(y_test, y_test_pred)
print('Bagging train/test accuracies %.3f/%.3f' % (bag_train, bag_test))执行结果如下:
Decision tree train/test accuracies 1.000/0.854
Bagging train/test accuracies 1.000/0.896结果可见,未经剪枝的决策树准确地预测了训练数据的所有类标;但是,测试数据上极低的准确率表明该模型方差过高(过拟合)。
虽然决策树与 bagging 分类器在训练数据集上的准确率相似,但是 bagging 分类器在测试数据上的泛化性能稍有胜出。

由上图可见,与深度为3的决策树线性分段边界相比,bagging 集成分类器的决策边界更平滑。
在实际中,分类任务更加复杂,数据集维度更高,使用单棵决策树很容易产生过拟合,这时 bagging 算法就可显示其优势了。bagging 算法是降低模型方差的一种有效方法。然而,bagging 在降低模型偏差方面的作用不大,这也是选择未经剪枝决策树等低偏差分类器作为集成算法分类器的原因。
自适应 boosting 提高弱学习机的性能
在 boosting 中,集成分类器包含多个非常简单的成员分类器,这些成员分类器性能仅稍好于随机猜测,常被称作弱学习机。典型的弱学习机例子就是单层决策树。boosting 主要针对难以区分的训练样本,也就是说,弱学习机通过在错误分类样本上的学习来提高集成分类的性能。与 bagging 不同,在 boosting 的初始化阶段,算法使用无放回抽样从训练样本中随机抽取一个子集。
原始的 boosting 过程可总结为如下四个步骤:

AdaBoost 与原始 boosting 过程不同,它使用整个训练集来训练弱学习机,其中训练样本在每次迭代中都会重新被赋予一个权重,在上一弱学习机错误的基础上进行学习进而构建一个更加强大的分类器。。
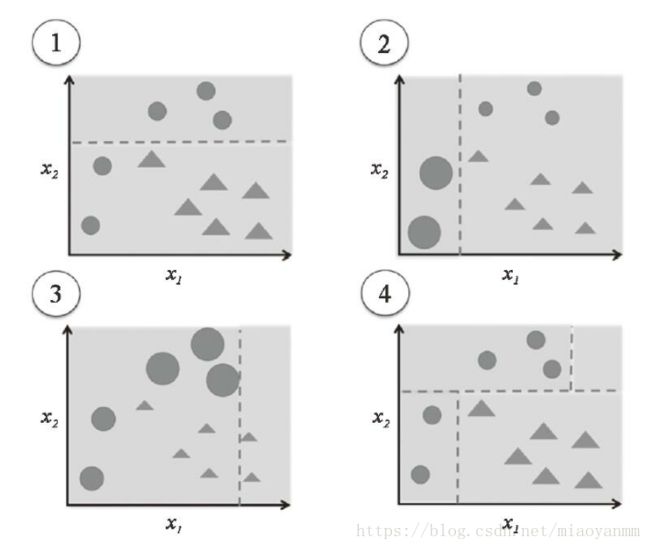
从子图1开始,它代表了一个二分类问题的训练集,其中所有的样本都被赋予相同的权重。基于此训练集,我们得到一棵单层决策树,它尝试尽可能通过最小代价函数划分两类样本(三角形和圆形)。在下一轮(子图2)中,为前面误分类的样本(圆形)赋予更高的权重。此外,我们还降低被正确分类样本的权重。下一棵单层决策树将更加专注于具有最大权重的训练样本,也就那些难以区分的样本。如子图2所示,弱学习机错误划分了圆形类的三个样本,它们在子图3中被赋予更大的权重。假定 AdaBoost 集成只包含3轮 boosting 过程,我们就能够用加权多数投票方式将不同重采样训练子集上得到的三个弱学习机进行组合,如子图4所示。
AdaBoost 集成算法步骤:

算法样例:
使用下面表格中的10个样本作为训练集


首先计算第5步中权重的错误率:
ε=0.1×0+0.1×0+0.1×0+0.1×0+0.1×0+0.1×0+0.1×1+0.1×1+0.1×1+0.1×0=0.3 ε = 0.1 × 0 + 0.1 × 0 + 0.1 × 0 + 0.1 × 0 + 0.1 × 0 + 0.1 × 0 + 0.1 × 1 + 0.1 × 1 + 0.1 × 1 + 0.1 × 0 = 0.3
下面计算相关系数 αj α j (第6步),该系数将在第7步权重更新及最后一个步骤多数投票预测中作为权重来使用。

在计算得到相关系数 αj α j 后,可根据下述公式更新权重向量:


from sklearn.ensemble import AdaBoostClassifier
tree = DecisionTreeClassifier(criterion='entropy', max_depth=1)
ada = AdaBoostClassifier(base_estimator=tree, n_estimators=500, learning_rate=0.1, random_state=0)
tree = tree.fit(X_train, y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train, y_train_pred)
tree_test = accuracy_score(y_test, y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train, tree_test))
ada = ada.fit(X_train, y_train)
y_train_pred = ada.predict(X_train)
y_test_pred = ada.predict(X_test)
ada_train = accuracy_score(y_train, y_train_pred)
ada_test = accuracy_score(y_test, y_test_pred)
print('AdaBoost train/test accuracies %.3f/%.3f' % (ada_train, ada_test))执行结果如下:
Decision tree train/test accuracies 0.845/0.854
AdaBoost train/test accuracies 1.000/0.875由结果可见,与未剪枝决策树相比,单层决策树对于训练数据过拟合的程度更加严重一点。
AdaBoost 模型准确预测了所有的训练集类标,与单层决策树相比,它在测试集上的表现稍好。

通过观察决策区域,可以看到 AdaBoost 的决策区域比单层决策树的决策区域复杂得多。
对集成技术做一个总结:与单独分类器相比,集成学习提高了计算复杂度。但在实践中,需要仔细权衡是否愿意为预测性能而付出更多的计算成本。
参考文献:
Python-Machine-Learning: Chapter 7: Combining Different Models for Ensemble Learning