NLP之人机对话系统
人机对话系统
人机对话系统又称口语对话系统(spoken dialogue system)。一个典型的人机对话系统主要包括如下6个技术模块:①语音识别器(speech recognizer);②语言解析器(language parser);③问题求解(problem resolving)模块;④语言生成器(language generator);⑤对话管理(dialogue management)模块;⑥语音合成器(speech synthesizer)。
语音识别模块实现用户输入语音到文字的识别转换,识别结果一般以得分最高的前n(n≥1)个句子或词格(word lattice)形式输出。语言解析模块对语音识别结果进行分析,获得给定输入的内部表示。语言生成模块根据解析模块得到的内部表示,在对话管理机制的作用下生成自然语言句子。语音合成模块将生成模块生成的句子转换成语音输出。问题求解模块依据语言解析器的分析结果进行问题的推理或查询,求解用户问题的答案。对话管理模块是系统的核心,一个理想的对话管理器应该能够基于对话历史调度人机交互机制,辅助语言解析器对语音识别结果进行正确的理解,为问题求解提供帮助,并指导语言的生成过程。可以说,对话管理机制是人机对话系统的中心枢纽。
1.口语解析器
对于一个基于中间表示的口语翻译系统和人机对话系统来说,口语解析器的作用可以简要地用图16-1表示。语音识别模块首先将用户语音转换成文字串,口语解析模块对其分析、理解,并将其转换成中间表示格式。在口语翻译系统中,语言生成器基于中间表示生成目标语言句子,而在人机对话系统中,语言生成器在对话管理模块的指导和控制下生成系统响应的句子。口语翻译系统中的语音合成器生成目标语言的语音,而对话系统中的语音合成器生成用户语言的语音。
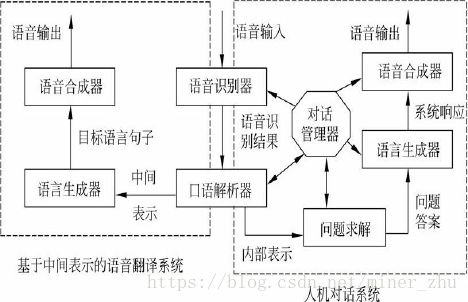
接下来介绍两种面向中间表示格式的汉语口语解析方法,一种是规则方法和HMM统计方法相结合的解析方法;另一种是基于语义分类树的解析方法。(中间表示采用C-STAR定义的IF格式)
1.1中间表示格式
IF格式的理论基础是对话行为(dialogue acts, DAs)理论,其基本观点认为,语言不只用来陈述事实,而且还附载着说话者的意图。
一个IF表达式通常由说话者(speaker)、话语行为(speech act)、概念序列(concept)和参数-属性值对的列表4个部分组成:
Speaker:Speech-Act[+Concept]*[(Argument=Value[,Argument=Value]*)]
其中,概念序列与话语行为合称为领域行为(domain action)。
星号“*”表示它所限定的左边成分可以重复出现多次。
(1)说话人标志(Speaker):表示说话人的身份。在IF中只有两种说话人身份,一种是顾客(client),用“c”表示,另一种是代理(agent),用“a”表示。
(2)语句意图或称话语行为或言语行为(Speech-Act):表示“询问信息、动作请求、返回信息”等各种话语意图。
如“give-information”表示提供某种信息;“pardon”表示请求说话人重复刚才所说的内容。
(3)概念(Concept):表示句子的主题(topic)概念。
如“reservation”表示“预订”,“room”表示“房间”等。各个概念之间按照一定的规则可以组合成更加广泛的主题。概念之间用“+”连接,表示并列关系,如“reservation+room”表示“预订房间”。
(4)具体参数(Argument):表示句子的具体内容。例如,房间个数、房间标准等。每个具体参数可以有不同的属性值(value),取值可以是原子值、参数-属性值对、或几个原子值按一定关系的组合(常对应句子中的联合结构)。
例如,参数“room-spec”表示属性“房间种类”,它的取值可以是“single(单间)”、“double(双人间)”等。
例: 明天我想预订一个单人间。
IF:c:give-information+reservation+room(room-spec=(room-type=single, quantity=1), reservation-spec=(time=(relative-time=tomorrow)))
该IF的含义为:说话人为“c”,该句子的意图是提供信息,主题概念为“预订房间”,关于“房间”的具体信息由一组“属性-值”对描述:房间类型(room-type)为单人间(single),数量(quantity)为1;“预订”的具体要求通过“相对时间(relative-time)”这一参数描述,参数值取“明天(tomorrow)”。
1.2基于规则和HMM的统计解析方法
本方法的基本思想可以用图表示。对于一个来自语音识别器的待解析句子,首先由词汇分类模块对其词汇进行词义分类,即把句子中的每一个词映射到相应的词义类中去。然后,语义组块分析器从句子对应的词义类序列中分析出语义组块,组块分析器输出的是一个语义组块序列。接下来,统计解析模块从语义组块序列分析出句子IF表示的主要框架。语义组块解释模块把各个语义组块解释为相应的IF表达式片段。最后,经过对上述两部分的合并,得到最终的IF表达式。
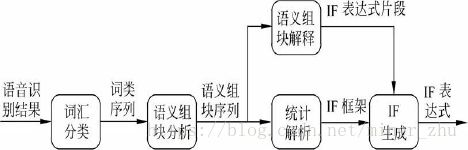
下面具体介绍各个部分的实现方法。1,词汇分类:根据词汇的语义功能,把每个词汇划分到不同的类。为此,我们定义了一个词汇语义类词典。在分类时参考了《同义词词林》和IF的相关规范。其分类依据是词汇在句子中的语义功能,语义功能相同的词汇归为一类。2.语义组块分析: 语义组块是指口语句子中不依赖于其他词汇而能表示某种特定语义的最小部分。同时,我们根据语义组块具体的意义,对语义组块进行了语义分类。语义组块分析器采用基于规则的线图分析算法(chart-parsing)实现组块识别,语法规则为基于词汇语义类的CFG,规则描述的是词汇语义类或语义组块之间组合成新语义组块的条件和结果。这些规则是通过观察和分析语料手工编写的。组块分析器的分析结果不一定是一个句子的完整语义结构树,可能是多个并列的局部语义结构子树。每个子树对应一个组块,一个句子的子树序列对应句子的语义组块序列。3.统计解析过程: 统计解析模块用于从输入的语义组块序列中解析出IF表示的主框架,采用HMM实现,其核心思想是将输入的语义组块序列作为HMM的观察,而将句子的IF表示作为HMM的内部状态。4.组块解释方法: 在语义组块分析时,通过规则方法获得语义组块的同时,也可以得到语义组块内部的层次结构,但这种层次结构并不是我们所需要的IF表示,因此,我们设计了语义组块解释模块,用来把这种层次结构转换为IF表示。语义组块解释模块是与组块分析模块配合工作的,组块分析过程中用到的每一条规则都对应一个规则的解释方法,利用这些解释方法可以把规则所涉及的词汇解释为相应的IF表示。5.IF的生成:从上面的介绍可以看出,基于HMM的解析模块输出的结果和语义组块解释的结果都只是IF的片段,只有把它们合并才能得到完整的IF表示。语义组块解释模块把每个语义组块转换为IF片段,同时每个语义组块经过统计解析模块解析后,又对应一个标注符号,并且该标注符号最终要作为IF表示中的一个结点。在各组块合并时,IF生成器把语义组块解释结果作为该结点的子结点,把经过简化处理的concepts序列还原为原来的concepts序列,这样就得到了IF表示。
1.3基于语义决策树的口语解析方法
从上面的介绍中可以看出,基于语义组块的口语解析方法在限定领域内能够获得较好的解析效果。
但是,该方法存在如下不足之处:①上下文窗口偏小。在使用HMM对句子进行解析时,窗口一般限定在左右两个词汇或组块,而在口语句子中存在很多不规范的现象,很多情况下一个词或短语的语义与离它较远的词汇密切相关,如果窗口太小,不利于处理长距离的约束关系。②领域行为中的多个概念需要根据人工预先定义的语义符号经解释获得。这样,对于每一个可能存在的概念序列都需要定义一个符号和相应的解释规则,这项工作不但繁琐,而且主观性强,并且影响系统的领域移植能力和IF的表达能力。③在获取话语意图时,主要从解析结果的单个特殊单元来理解,这样也存在一定的局限性。
基于语义决策树的口语解析方法,该方法用统计方法从训练语料中自动获取规则,从而避免了人工编写规则的繁琐和主观性,并具有较高的鲁棒性,用统计模型直接获得整个领域的行为表示,便于句子整体意义的理解。
通过观察,我们发现一个汉语句子的领域行为和句子中的一些关键词语存在密切关系。因此,我们可以根据词语所在的上下文环境来确定其语义。
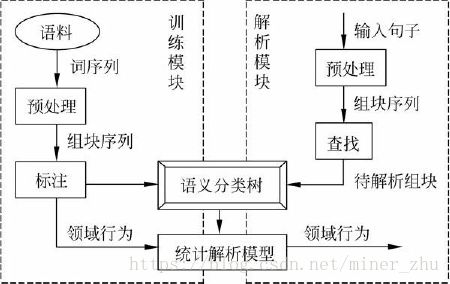
该方法的基本思路是:在对训练语料进行标记的基础上,为每一个与领域行为密切相关的词汇生成一棵语义分类树,语义分类树包含了在其生成过程中从训练语料中自动获取的一系列语义规则和语义的概率信息。当一个需要解析的句子输入时,首先用语义分类树对与领域行为密切相关的词语进行解析,获得它们对应的语义信息及其概率。然后,用统计模型对多个词语的语义结果进行组合,从而获得整个句子的领域行为。为了减小系统规模和数据稀疏问题,可以在对句子进行预处理的基础上对句子的词类或组块进行解析。
2.基于MDP的对话行为识别
对话行为(dialog acts, DAs)是说话人对话意图的表现形式。
2008提出了一种基于马尔可夫决策过程(Markov decision processes, MDPs)和SVM方法相结合的对话行为预测方法,其基本思路是:用MDP预测对话行为,然后将预测结果融入基于语句的SVM分类器,最终获得对话行为的识别结果。对话行为的预测映射为一个马尔可夫决策过程,定义为一个4元组(S, A, T, R),其中,S表示状态,由说话人是否变化的标记(sp_change)和对话行为(DA)的历史描述。如果说话人发生了变化,则sp_change=1,否则sp_change=0。对话历史包括同一说话人前一句话的对话行为和对方说话人前一句话的对话行为。
A为动作集,一共包括13个动作,每个动作表示一个对话行为标签,作为对下一个对话行为的预测。如s表示陈(statement)、qy表示是非问(Y/N question)、qw表示特指问(Wh-question)等。
T为状态转移概率矩阵,Tij=P(Sj|Si,Ai)表示系统由状态Si转移到Sj的概率。
R表示回报(reward)。回报方程(reward function)是预测结果正确或错误的反映。Zhou et al.(2008b)从经验的角度对转移概率矩阵进行回报或惩罚。如果预测结果正确,回报因子为1.1,否则给出的惩罚因子为0.9,该数据为一组实验中测得的最优值。
最后用SVM分类器对MDP的预测结果进行分类识别。
3.基于中间表示的口语生成方法
自然语言生成(natural language generation)技术研究的是如何利用计算机把非自然语言的表示形式转换成某种自然语言的表示形式,从而产生人们可理解的,表达确切、自然流畅的自然语言语句。接下来介绍基于IF的汉语口语生成方法。
基于IF的汉语口语生成器是面向多语言口语翻译系统设计的,该系统采用基于模板的方法和基于特征的深层生成方法相结合的混合生成方法。采用这种混合方法的主要理由有如下几点:首先,特定领域的口语对话中常用一些固定的表达模式。其次,对于非固定的表达方式,由于其表达形式灵活多样,采用基于特征的深层生成方法无疑更能满足系统对于灵活性的要求。此外,基于特征的生成方法可以把不同语言的差异作为特征加入系统中,更易于用统一的程序框架实现不同语言的生成过程,便于系统扩展和移植。
根据上述考虑,基于IF的汉语口语生成器主要由三个模块组成:微观规划器、表层生成器和后处理模块。一个给定的IF表达式,首先经过微观规划器得到对应的句法功能结构,然后,句法功能结构通过表层生成器得到最终的汉语句子。这里所用的句法功能结构是基于系统功能语法而定义的,其格式是多个特征-属性值对的集合,包含生成一个句子所必须的各种信息(语气、时态、语态、谓词框架等)。表层生成器采用功能合一文法,利用生成语言的句法知识把句法功能结构中的各个特征逐步聚合,并进行线性化处理。后处理模块完成句子最后的修饰和补充,包括添加助词、量词等。
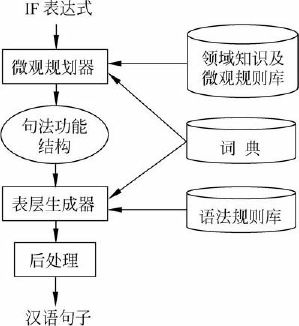
3.1微观规划器
在基于IF的汉语口语生成器中,一个给定的IF表达式与一个句子或词组相对应,生成句子所需要的各项浅层信息都已经在IF的参数中给出,所以生成器所要做的事情就是根据IF和领域知识生成对应的语句,而无需进行句子内容的确定。但是,由于IF没有提供句子生成所需要的谓词-论元信息,需要生成器根据IF表达式、领域知识和中心词的搭配信息进行推断。因此,生成器中的微观规划器需要实现如下几个功能:①根据IF和领域知识确定句子的类型,获得句子生成所必需的谓词-论元框架;②将领域概念转化为词汇,进行词汇选择,并从词典中获得所有与选定词汇相关的词语搭配信息等;③将领域关系转化为语法关系;④获得句子的语气、时态和语态等信息。
微观规划器完成的任务分为句子规划和短语规划两个层次。句子规划的功能主要是根据IF表达式和领域知识推断句子的顶层信息,如主要动词、时态、语态,语气等,并根据主要动词获得生成句子所必需的谓词-论元框架;短语规划是把IF格式中的属性和概念转换为句子的参与角色,即获得生成句子的浅层短语信息。
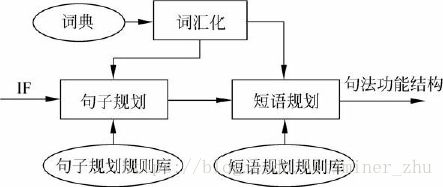
一个IF表达式经微观规划器转换后成为句子的句法功能结构,句法功能结构将直接作为表层生成器的输入。领域知识体现在规划规则的表示上。
句子规划规则可以由一个三元组(P,C,A)描述。P指IF的主体部分(包括说话者和领域行为)的模式(pattern),C是约束
(constraints),可以是空集,也可以是对IF所含概念(concepts)和参数(arguments)状况的约束。A是动作(action),指在给定IF满足P和C的条件下,执行A操作获得该IF所对应的句子的功能结构。句子规划时,微观规划器输入的IF首先与P中的模式匹配,如果匹配,再看输入是否满足C中的约束,如果两者都满足,则执行动作A,获得句子的主要动词及框架信息。
语规划主要处理IF中的“参数-属性值”描述,或者某些概念与“参数-属性值”的组合描述。与句子规划规则类似,短语规划规则也由三元组形式构成。
3.2表层生成器
表层生成器是语言生成器的最后一个阶段,其任务是借助于语法规则将微观规划器的输出生成正确、流畅的自然语言句子。
表层生成器首先利用词法和句法规则对输入的句法功能结构表示进行合一运算,得到非线性化的句子模式,然后,利用句子和短语中各成分排列顺序规则对句子模式进行线性化处理,得到初步的生成语句,并由后处理模块做最后的修饰处理。
由于IF本身是一种不完备的语义表示,而且语音识别和句子解析模块造成的错误往往使IF含有噪声或出现信息缺失等现象,因此,为了确保生成器具有一定的鲁棒性,能够在给定IF含有错误或不完整的情况下生成正确或可以理解的句子,该生成器中采用了缺省值处理措施,并放宽了对微观规划规则和表层生成器中语法规则的约束,使其能够在某些条件不满足的情况下生成不完整的句子。