NCNN: 应用于手机上的卷积加速
从C++ 到android
在ncnn中是用C++写的,没玩过android很是愧疚。幸好项目中有android依赖链的cmake文件。
Android CMake toolchain file, for use with the Android NDK r5-r10d
Requires cmake 2.6.3 or newer (2.8.9 or newer is recommended).
See home page: https://github.com/taka-no-me/android-cmake
## Usage Linux:
$ export ANDROID_NDK=/absolute/path/to/the/android-ndk
$ mkdir build && cd build
$ cmake -DCMAKE_TOOLCHAIN_FILE=path/to/the/android.toolchain.cmake ..
$ make -j8
## Usage Windows:
You need native port of make to build your project.
Android NDK r7 (and newer) already has make.exe on board.
For older NDK you have to install it separately.
For example, this one: http://gnuwin32.sourceforge.net/packages/make.htm
$ SET ANDROID_NDK=C:\absolute\path\to\the\android-ndk
$ mkdir build && cd build
$ cmake.exe -G"MinGW Makefiles"
-DCMAKE_TOOLCHAIN_FILE=path\to\the\android.toolchain.cmake
-DCMAKE_MAKE_PROGRAM="%ANDROID_NDK%\prebuilt\windows\bin\make.exe" ..
$ cmake.exe --build .
内心很是欣喜,再次凸显注释的重要性。沿着提示信息,我就学习了一下android-cmake
cmake -DCMAKE_TOOLCHAIN_FILE=android.toolchain.cmake \
-DANDROID_NDK= \
-DCMAKE_BUILD_TYPE=Release \
-DANDROID_ABI="armeabi-v7a with NEON" \
cmake --build . 这个跟直接在x86平台最大的区别就是需要额外指定cmake tool chain的配置文件android.toolchain.cmake和tool chain的依赖路径-DANDROID_NDK=,其他跟直接使用CMakeLists.txt相似。让我再次感慨,CMake很是666的。另外-DANDROID_ABI="armeabi-v7a with NEON" 是用来制定编译target的一些属性和优化方案等等。这个具体可以到android.toolchain.cmake文件中看个究竟,而且在注释中有相应的说明。
实战C++编译android lib
宏观剖析NCNN
涉及技术
- OpenMP
#pragma omp parallel for
for (int p=0; p- SIMD
- loop unrolling
- CNN的基本概念
主要实现CPU上的forward和backward的加速方案。其中卷积过程主要采用直接进行卷积计算的方式,没有采用img2col和FFT的方式,就是对直接卷积过程进行了实现和加速。
卷积计算方法分析
--src
|--blob.cpp
|--blob.h
|--cpu.cpp
|--cpu.h
|--layer
|--layer.cpp
|--layer.h
|--mat.cpp
|--mat.h
|--mat_pixel.cpp
|--net.cpp
|--net.h
|--opencv.cpp
|--opencv.h
|--platform.h.in
cpu.h: 主要获取cpu的个数,频率,设置省电模式,以及动态调整的函数。
Mat
mat.h:主要数据结构。
在其中扮演着参数传递和图像存储的作用。如果想对内存管理进行了解,可以好好看看mat.cpp的相关实现。理解这个数据结构,对后面理解优化过程很有帮助。
// exchange-add operation for atomic operations on reference counters
#if defined __INTEL_COMPILER && !(defined WIN32 || defined _WIN32)
// atomic increment on the linux version of the Intel(tm) compiler
# define NCNN_XADD(addr, delta) (int)_InterlockedExchangeAdd(const_cast(reinterpret_cast(addr)), delta)
#elif defined __GNUC__
# if defined __clang__ && __clang_major__ >= 3 && !defined __ANDROID__ && !defined __EMSCRIPTEN__ && !defined(__CUDACC__)
# ifdef __ATOMIC_ACQ_REL
# define NCNN_XADD(addr, delta) __c11_atomic_fetch_add((_Atomic(int)*)(addr), delta, __ATOMIC_ACQ_REL)
# else
# define NCNN_XADD(addr, delta) __atomic_fetch_add((_Atomic(int)*)(addr), delta, 4)
# endif
# else
# if defined __ATOMIC_ACQ_REL && !defined __clang__
// version for gcc >= 4.7
# define NCNN_XADD(addr, delta) (int)__atomic_fetch_add((unsigned*)(addr), (unsigned)(delta), __ATOMIC_ACQ_REL)
# else
# define NCNN_XADD(addr, delta) (int)__sync_fetch_and_add((unsigned*)(addr), (unsigned)(delta))
# endif
# endif
#elif defined _MSC_VER && !defined RC_INVOKED
# include
# define NCNN_XADD(addr, delta) (int)_InterlockedExchangeAdd((long volatile*)addr, delta)
#else
static inline void NCNN_XADD(int* addr, int delta) { int tmp = *addr; *addr += delta; return tmp; }
#endif 是编译器的一些特性函数,此处主要用来实现原子加法操作了。毕竟将来是多线程运行的,引用计数错误可是会导致内存泄露的。
mat_pixel.cpp:
主要用来实现Mat与图像的流的转化,纯手撸,没有依赖opencv,没有依赖opencv,没有依赖opencv. 但是图片是怎么输入的呢
图片如何输入的
在opencv.h和opencv.cpp中实现了一个缩小版本的的图片输入输出文件,默认是不使用的。这个我得试试 option(NCNN_OPENCV "minimal opencv structure emulation" OFF) 因为我看example中使用的不是自己实现的这个文件输入输出,而是直接调用OpenCV的图片读取接口,然后调用的ncnn::Mat::from_pixels_resize(...)进行的数据转化,加上那么多格式的图片,所以这个重新进行自己运行确认一下比较好。
blob.h
主要用来记录层与层之间关系的,采用了生产者和消费者模型实现的。其使用的地方在Net中的一个参数blobs
class Blob
{
public:
// empty
Blob();
public:
#if NCNN_STRING
// blob name
std::string name;
#endif // NCNN_STRING
// layer index which produce this blob as output
int producer;
// layer index which need this blob as input
std::vector consumers;
}; net.h 这个整个神经网络模型的框架实现。重要的有
- Net如何加载模型和参数的
- 如何表示层间关系的
神经网络结构定义
网络结构
class Net
{
protected:
std::vector blobs;
std::vector layers;
std::vector custom_layer_registry;
}; 注册函数
// layer factory function
typedef Layer* (*layer_creator_func)();
struct layer_registry_entry
{
// layer type name
const char* name;
// layer factory entry
layer_creator_func creator;
};
// get layer type from type name
int layer_to_index(const char* type);
// create layer from layer type
Layer* create_layer(int index);
#define DEFINE_LAYER_CREATOR(name) \
Layer* name##_layer_creator() { return new name; }
添加自定义网络层次
int Net::register_custom_layer(const char* type, layer_creator_func creator)
{
int typeindex = layer_to_index(type);
if (typeindex != 0)
{
fprintf(stderr, "can not register build-in layer type %s\n", type);
return -1;
}
int custom_index = custom_layer_to_index(type);
if (custom_index == -1)
{
struct layer_registry_entry entry = { type, creator };
custom_layer_registry.push_back(entry);
}
else
{
fprintf(stderr, "overwrite existing custom layer type %s\n", type);
custom_layer_registry[custom_index].name = type;
custom_layer_registry[custom_index].creator = creator;
}
return 0;
}卷积过程
直接进行卷积运算,想必应该知道的。那么如何对这个过程进行加速呢?这部分得看src/layer文件的Convolution.h就是没有向量化加速的卷积过程,仅仅使用了OpenMP框架进行了多线程化;在arm架构下实现了convolution_arm.cpp, 在x86架构下实现了convolution_x86.cpp。怎么知道到底是使用加速版本还是非加速版本呢?这个得看/src/CMakeLists.txt中的ncnn_add_layer是如何定义的。
macro(ncnn_add_layer class)
string(TOLOWER ${class} name)
# WITH_LAYER_xxx option
if(${ARGC} EQUAL 2)
option(WITH_LAYER_${name} "build with layer ${name}" ${ARGV1})
else()
option(WITH_LAYER_${name} "build with layer ${name}" ON)
endif()
message("WITH_LAYER_${name} = ${WITH_LAYER_${name}}")
if(WITH_LAYER_${name})
# 向源文件列表中添加默认cpp文件,这个不重要
list(APPEND ncnn_SRCS "${CMAKE_CURRENT_SOURCE_DIR}/layer/${name}.cpp")
# look for arch specific implementation and append source
# optimized implementation for armv7 aarch64
# 查找特定架构下的实现,是否存在,这很重要
if((ANDROID AND ("${CMAKE_SYSTEM_PROCESSOR}" STREQUAL "armv7-a"))
OR (ANDROID AND ("${CMAKE_SYSTEM_PROCESSOR}" STREQUAL "aarch64"))
OR (IOS AND ("${CMAKE_OSX_ARCHITECTURES}" STREQUAL "armv7"))
OR (IOS AND ("${CMAKE_OSX_ARCHITECTURES}" STREQUAL "arm64"))
OR (IOS AND ("${CMAKE_OSX_ARCHITECTURES}" STREQUAL "armv7;arm64")))
if(EXISTS "${CMAKE_CURRENT_SOURCE_DIR}/layer/arm/${name}_arm.cpp")
# 添加源文件到编译文件列表中
list(APPEND ncnn_SRCS "${CMAKE_CURRENT_SOURCE_DIR}/layer/arm/${name}_arm.cpp")
# 添加宏定义define WITH_LAYER_xxx_arm 1
set(WITH_LAYER_${name}_arm 1)
endif()
else()
if(EXISTS "${CMAKE_CURRENT_SOURCE_DIR}/layer/x86/${name}_x86.cpp")
list(APPEND ncnn_SRCS "${CMAKE_CURRENT_SOURCE_DIR}/layer/x86/${name}_x86.cpp")
set(WITH_LAYER_${name}_x86 1)
endif()
endif()
endif()
# generate layer_declaration and layer_registry file
if(WITH_LAYER_${name})
# 上面宏定义为true了
if(WITH_LAYER_${name}_arm)
# 好,在下面两个文件夹中添加,对应的层生成器(怎么添加在前面的**神经网络结构定义**),添加的是特定架构下的,这个很重要
file(APPEND ${CMAKE_CURRENT_BINARY_DIR}/layer_declaration.h
"extern Layer* ${class}_arm_layer_creator();\n")
file(APPEND ${CMAKE_CURRENT_BINARY_DIR}/layer_registry.h
"#if NCNN_STRING\n{\"${class}\",${class}_arm_layer_creator},\n#else\n{${class}_arm_layer_creator},\n#endif\n")
elseif(WITH_LAYER_${name}_x86)
file(APPEND ${CMAKE_CURRENT_BINARY_DIR}/layer_declaration.h
"extern Layer* ${class}_x86_layer_creator();\n")
file(APPEND ${CMAKE_CURRENT_BINARY_DIR}/layer_registry.h
"#if NCNN_STRING\n{\"${class}\",${class}_x86_layer_creator},\n#else\n{${class}_x86_layer_creator},\n#endif\n")
else()
file(APPEND ${CMAKE_CURRENT_BINARY_DIR}/layer_declaration.h
"extern Layer* ${class}_layer_creator();\n")
file(APPEND ${CMAKE_CURRENT_BINARY_DIR}/layer_registry.h
"#if NCNN_STRING\n{\"${class}\",${class}_layer_creator},\n#else\n{${class}_layer_creator},\n#endif\n")
endif()
else()
file(APPEND ${CMAKE_CURRENT_BINARY_DIR}/layer_registry.h "#if NCNN_STRING\n{\"${class}\",0},\n#else\n{0},\n#endif\n")
endif()
endmacro()也就是说在cmake的时候组装上的加速版本的层。然后编译的时候,利用前面的介绍的层注册机制实现的不同架构下可以使用不同的实现。
Convolution
int Convolution::forward(const Mat& bottom_blob, Mat& top_blob) const
{
// convolv with NxN kernel
// value = value + bias
int w = bottom_blob.w;
int h = bottom_blob.h;
int channels = bottom_blob.c;
// 添加padding操作
const int kernel_extent = dilation * (kernel_size - 1) + 1;
Mat bottom_blob_bordered = bottom_blob;
if (pad > 0)
{
copy_make_border(bottom_blob, bottom_blob_bordered, pad, pad, pad, pad, BORDER_CONSTANT, 0.f);
if (bottom_blob_bordered.empty())
return -100;
w = bottom_blob_bordered.w;
h = bottom_blob_bordered.h;
}
else if (pad == -233)
{
int wpad = kernel_extent + (w - 1) / stride * stride - w;
int hpad = kernel_extent + (h - 1) / stride * stride - h;
copy_make_border(bottom_blob, bottom_blob_bordered, hpad / 2, hpad - hpad / 2, wpad / 2, wpad - wpad / 2, BORDER_CONSTANT, 0.f);
if (bottom_blob_bordered.empty())
return -100;
w = bottom_blob_bordered.w;
h = bottom_blob_bordered.h;
}
// 计算输出大小
int outw = (w - kernel_extent) / stride + 1;
int outh = (h - kernel_extent) / stride + 1;
top_blob.create(outw, outh, num_output);
if (top_blob.empty())
return -100;
const int maxk = kernel_size * kernel_size;
// kernel offsets
// 计算kernel的在image中放置的相对位置,计算的时候直接取用就是了
std::vector _space_ofs(maxk);
int* space_ofs = &_space_ofs[0];
{
int p1 = 0;
int p2 = 0;
int gap = w * dilation - kernel_size * dilation;
for (int i = 0; i < kernel_size; i++)
{
for (int j = 0; j < kernel_size; j++)
{
space_ofs[p1] = p2;
p1++;
p2 += dilation;
}
p2 += gap;
}
}
// num_output
const float* weight_data_ptr = weight_data;
#pragma omp parallel for
for (int p=0; p 从上面可以看出,实现Convolution使用的是直接计算的方法,不是caffe里面img2col的方法。下面再分析一下x86下如何加速的。
x86仅仅实现了3x3和5x5的卷积的skip=1的加速过程,主要是在
Convolution_x86::forward中进行的。其中有一个conv_func_table数组,是具体的卷积过程的指针函数数组。下面我们来看3x3是如何优化的:
static void conv3x3s1_sse(const Mat& bottom_blob, Mat& top_blob, const Mat& _kernel, const Mat& _bias)
{
// 获取输入的大小
int w = bottom_blob.w;
int inch = bottom_blob.c;
// 输出的大小
int outw = top_blob.w;
int outh = top_blob.h;
int outch = top_blob.c;
const float* kernel = _kernel;
const float* bias = _bias;
// 调用openmp进行并行化
#pragma omp parallel for
for (int p=0; p0; remain--)
{
float sum = 0;
float sum2 = 0;
sum += r0[0] * k0[0];
sum += r0[1] * k0[1];
sum += r0[2] * k0[2];
sum += r1[0] * k1[0];
sum += r1[1] * k1[1];
sum += r1[2] * k1[2];
sum += r2[0] * k2[0];
sum += r2[1] * k2[1];
sum += r2[2] * k2[2];
sum2 += r1[0] * k0[0];
sum2 += r1[1] * k0[1];
sum2 += r1[2] * k0[2];
sum2 += r2[0] * k1[0];
sum2 += r2[1] * k1[1];
sum2 += r2[2] * k1[2];
sum2 += r3[0] * k2[0];
sum2 += r3[1] * k2[1];
sum2 += r3[2] * k2[2];
*outptr += sum;
*outptr2 += sum2;
r0++;
r1++;
r2++;
r3++;
outptr++;
outptr2++;
}
r0 += 2 + w;
r1 += 2 + w;
r2 += 2 + w;
r3 += 2 + w;
outptr += outw;
outptr2 += outw;
}
// 残余处理,每次只进行一个位置的卷积计算
for (; i < outh; i++)
{
int remain = outw;
for (; remain>0; remain--)
{
float sum = 0;
sum += r0[0] * k0[0];
sum += r0[1] * k0[1];
sum += r0[2] * k0[2];
sum += r1[0] * k1[0];
sum += r1[1] * k1[1];
sum += r1[2] * k1[2];
sum += r2[0] * k2[0];
sum += r2[1] * k2[1];
sum += r2[2] * k2[2];
*outptr += sum;
r0++;
r1++;
r2++;
outptr++;
}
r0 += 2;
r1 += 2;
r2 += 2;
}
}
}
}
Pooling
Pooling的实现与Convolution的实现很相似,这里就不做解释了。Pooling主要实现了全局MaxPooling, 全局AvePooling, 局部Max Pooling与局部AvePooling.局部Pooling包含边缘Padding的处理。 具体padding的处理可以看 void copy_make_border(...)如何实现的。
Softmax
采用omp parallel for的方式,进行如下操作: value = exp( value - global max value ) sum all value value = value / sum 在ARM平台上,进一步通过SIMD技术加速优化,这里不再赘述。
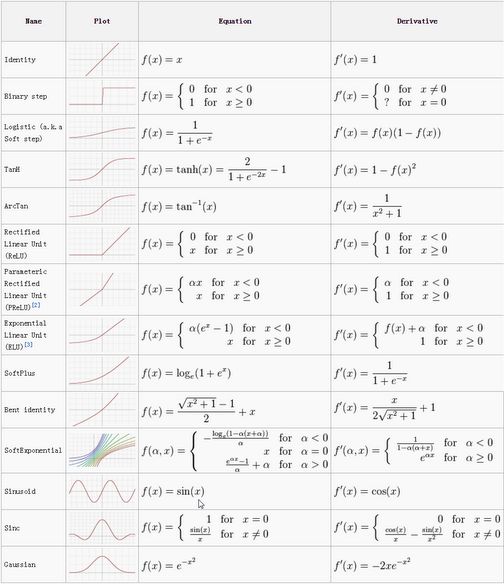 当然,Sigmoid在ARM上也进行了类似SoftMax的优化,Sigmod比Softmax实现简单得多,这里就不说了。
当然,Sigmoid在ARM上也进行了类似SoftMax的优化,Sigmod比Softmax实现简单得多,这里就不说了。
Batch Normalization
BatchNorm层有点不一样,仅仅看forward是看不明白的,需要看load_model中的一些操作。
a = bias - slope * mean / sqrt(var)
b = slope / sqrt(var)
value = b * value + a
一般解释的时候slope就是当做1进行解释的。
int BatchNorm::load_model(const unsigned char*& mem)
{
slope_data = Mat(channels, (float*)mem);
mem += channels * sizeof(float);
mean_data = Mat(channels, (float*)mem);
mem += channels * sizeof(float);
var_data = Mat(channels, (float*)mem);
mem += channels * sizeof(float);
bias_data = Mat(channels, (float*)mem);
mem += channels * sizeof(float);
a_data.create(channels);
if (a_data.empty())
return -100;
b_data.create(channels);
if (b_data.empty())
return -100;
const float* slope_data_ptr = slope_data;
const float* mean_data_ptr = mean_data;
const float* var_data_ptr = var_data;
const float* bias_data_ptr = bias_data;
float* a_data_ptr = a_data;
float* b_data_ptr = b_data;
for (int i=0; i如果对BatchNormalization不明白,可看看后面的参考文献[3][4]。
积淀姿势
几个有用的内存管理对齐方案,这个在OpenCV里见过,放在这里再次表示其重要性,为什么这么实现,可以搜索OpenCV内存管理
// the alignment of all the allocated buffers
#define MALLOC_ALIGN 16
// Aligns a pointer to the specified number of bytes
// ptr Aligned pointer
// n Alignment size that must be a power of two
template static inline _Tp* alignPtr(_Tp* ptr, int n=(int)sizeof(_Tp))
{
return (_Tp*)(((size_t)ptr + n-1) & -n);
}
// Aligns a buffer size to the specified number of bytes
// The function returns the minimum number that is greater or equal to sz and is divisible by n
// sz Buffer size to align
// n Alignment size that must be a power of two
static inline size_t alignSize(size_t sz, int n)
{
return (sz + n-1) & -n;
}
// 原来不止python可以使用负下标,C也是可以的喽
static inline void* fastMalloc(size_t size)
{
unsigned char* udata = (unsigned char*)malloc(size + sizeof(void*) + MALLOC_ALIGN);
if (!udata)
return 0;
unsigned char** adata = alignPtr((unsigned char**)udata + 1, MALLOC_ALIGN);
adata[-1] = udata;
return adata;
}
static inline void fastFree(void* ptr)
{
if (ptr)
{
unsigned char* udata = ((unsigned char**)ptr)[-1];
free(udata);
}
} 小结
剩下的就是去看intel的intrinsics文档了。
参考文献
- android cmake入门指导
- SMP Symmetric Multi-Processor
- Batch Normalization 学习笔记
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Intel Intrinsics Guide