浅谈分布式系统脑裂现象与ZK、HDFS的避免方案
脑裂的概念与成因
"split brain"原本是指医学中的“裂脑综合征”,即连接大脑左右半球的胼胝体受损到一定程度后发生的症状。左右脑分离后,会分别处理知觉、形成概念和对刺激产生反应,相当于有两个脑在一个身体运作,会造成患者行为的冲突。例如:
- 当一个裂脑患者更衣时,他有时会一只手将裤子拉起,却另一只手将裤子往下脱。
- 当一个影像只投射在裂脑患者的左视觉区,他无法说出看见了什么——因为左视觉区的影像只会传递到右脑,而大部分人的语音控制中心在左脑,患者的左右脑无法交流信息。

https://www.nature.com/news/the-split-brain-a-tale-of-two-halves-1.10213
split brain这个词也被计算机科学引入,指采用主从(master-slave)架构的分布式系统中,出现了多个活动的主节点的情况。但正常情况下,集群中应该只有一个活动主节点。
造成脑裂的原因主要是网络分区(这个词之前在讲CAP理论时就已经出现过了)。由于网络故障或者集群节点之间的通信链路有问题,导致原本的一个集群被物理分割成为两个甚至多个小的、独立运作的集群,这些小集群各自会选举出自己的主节点,并同时对外提供服务。网络分区恢复后,这些小集群再度合并为一个集群,就出现了多个活动的主节点。
另外,主节点假死也有可能造成脑裂。由于当前主节点暂时无响应(如负载过高、频繁GC等)导致其向其他节点发送心跳信号不及时,其他节点认为它已经宕机,就触发主节点的重新选举。新的主节点选举出来后,假死的主节点又复活,就出现了两个主节点。
脑裂的危害非常大,会破坏集群数据和对外服务的一致性,所以在各分布式系统的设计中,都会千方百计地避免产生脑裂。下面举两个例子说说。
脑裂的避免方案
一般有以下三种思路来避免脑裂:
- 法定人数/多数机制(Quorum)
- 隔离机制(Fencing)
- 冗余通信机制(Redundant communication)
例1:ZooKeeper & Quorum
Quorum一词的含义是“法定人数”,在ZooKeeper的环境中,指的是ZK集群能够正常对外提供服务所需要的最少有效节点数。也就是说,如果n个节点的ZK集群有少于m个节点是up的,那么整个集群就down了。m就是所谓Quorum size,并且:
m = n / 2 + 1
为什么是这个数呢?
考虑一个n = 5的ZK集群,并且它按3:2分布在两个机房中。
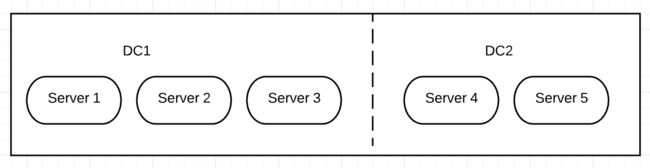
假设m = 2(即n / 2),当两个机房之间的网络中断时,Server 1~3和Server 4~5将分别形成独立的集群,并且都能对外提供服务——也就意味着都能重新选举出各自的Leader,即产生了脑裂。当网络恢复,两个集群合并时,它们的数据就会不一致。
但是,若m = 3(即n / 2 + 1),那么网络中断后,DC2上的两个节点不满足Quorum要求的数量,故只有DC1上的三个节点能选举出Leader并提供服务,DC2上的两个节点不能提供服务,当然也就不会破坏数据一致性了。
由上可知,ZK的Quorum机制其实就是要求集群中过半的节点是正常的,所以ZK集群包含奇数个节点比偶数个节点要更好。显然,如果集群有6个节点的话,Quorum size是4,即能够容忍2个节点失败,而5个节点的集群同样能容忍2个节点失败,所以可靠性是相同的。偶数节点还需要额外多管理一个节点,不划算。
上面说的是网络分区的情况,如果是Leader假死呢?
之前某篇文章中其实说过了,集群每次选举出一个Leader时,都会自增纪元值(epoch),也就是Leader的代数。所以,就算原来的Leader复活,它的纪元值已经小于新选举出来的现任Leader的纪元值,Follower就会拒绝所有旧Leader发来的请求,所以不会产生脑裂。当然,有一部分Follower可能对新选举出的Leader没有感知,但由于上述Quorum机制的保证,这部分肯定不会占多数,故集群能够正常运转。除ZK外,Kafka集群的Controller也是靠纪元值防止脑裂的。
例2:HDFS NameNode HA & Fencing
下面先贴出HDFS高可用的官方经典架构图。
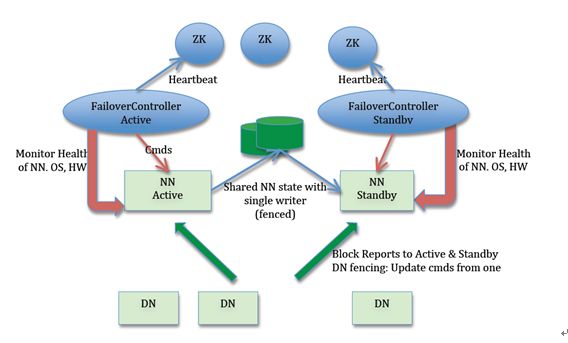
HDFS NameNode高可用需要两个NN节点,一个处于活动状态,另一个处于热备状态,由ZKFailoverController组件借助外部ZK集群提供主备切换支持。
当活动NN假死时,ZK集群长时间收不到心跳信号,就会触发热备NN提升为活动NN,之前的NN复活就造成脑裂。如何解决呢?答案就是隔离,即将原来那个假死又复活的NN限制起来(就像用篱笆围起来一样),使其无法对外提供服务。具体来讲涉及到三方面。
- 两个NN中同时只有一个能向共享存储(QJM方案下就是JournalNode集群)写入edit log;
- 两个NN中同时只有一个能向DataNode发出数据增删的指令;
- 两个NN中同时只有一个能响应客户端的请求。
为了实现Fencing,成为活动NN的节点会在ZK中创建一个路径为/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb的持久znode。当正常发生主备切换时,ZK Session正常关闭的同时会一起删除上述znode。但是,如果NN假死,ZK Session异常关闭,/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb这个znode就会残留下来。由热备升格为活动的NN会检测到这个节点,并执行Fencing逻辑:
-
尝试调用旧活动NN的RPC接口中的相关方法,强制将其转换成热备状态;
-
如果转换失败,那么就根据
dfs.ha.fencing.methods执行sshfence、shellfence两种隔离措施。sshfence就是通过SSH登录到该节点上,执行fuser命令通过定位端口号杀掉NameNode进程;shellfence就是执行用户定义的Shell脚本来隔离NameNode进程。
只有Fencing执行完毕之后,新的NN才会真正转换成活动状态并提供服务,所以能够避免脑裂。
最后废话一句,JournalNode集群区分新旧NN同样是靠纪元值,而它的可用性也是靠Quorum机制——即如果JournalNode集群有2N + 1个节点的话,最多可以容忍N个节点失败。
The End
冗余通信机制没有提到,其实就是在节点之间添加额外的心跳线,防止一个心跳路径断开导致误判。
帝都疫情开始反弹,还是老实在家待着吧。
民那周末快乐,晚安。