Azkaban工作流调度器(一)基本使用,定时任务
【练功篇】25-Azkaban-工作流调度器
下载地址:
azkaban-3.38安装包(已编译)
https://download.csdn.net/download/oYuZhongManBu1234/12445784
一、为什么需要工作流调度器
1、一个完整的数据分析系统通常都是由大量任务单元组成: shell 脚本程序,java 程序,mapreduce 程序、hive 脚本等
2、各任务单元之间存在时间先后及前后依赖关系,工作流调度器可以很好的帮他们建立先后执行顺序
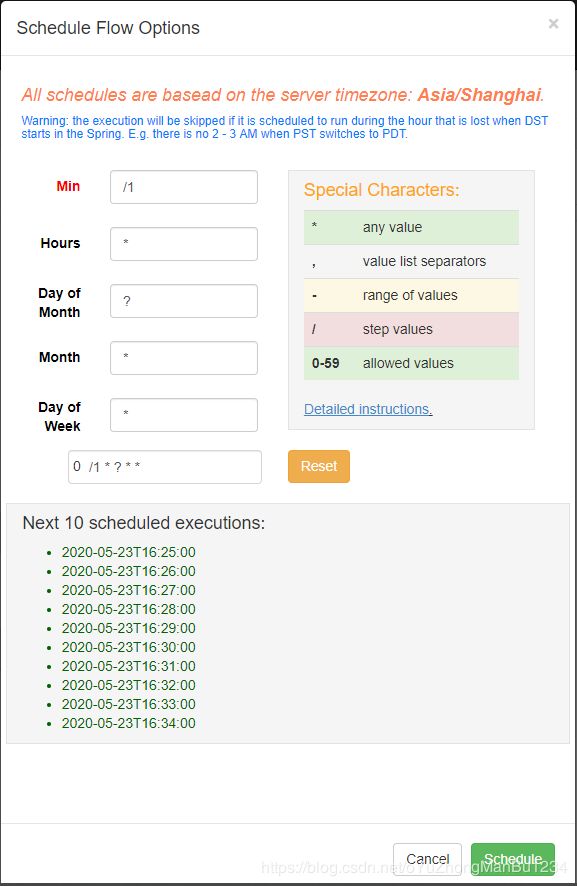
3、工作流调度器可非常方便进行定时任务
例如,我们可能有这样一个需求,某个业务系统每天产生 20G 原始数据,我们每天都要对其进行处理,处理步骤如下所示:
1、 通过 Hadoop 先将原始数据同步到 HDFS 上;
2、 借助 MapReduce 计算框架对原始数据进行清洗转换,生成的数据以分区表的形式存储 到多张 Hive 表中;
3、 需要对 Hive 中多个表的数据进行 JOIN 处理,得到一个明细数据 Hive 大表;
4、 将明细数据进行各种统计分析,得到结果报表信息;
5、 需要将统计分析得到的结果数据同步到业务系统中,供业务调用使用。
二、工作流调度实现方式
简单的任务调度:直接使用 linux 的 crontab 来定义;
复杂的任务调度:开发调度平台或使用现成的开源调度系统,比如 ooize、azkaban 等
三、Azkaban介绍
Azkaban是由Linkedin开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。
azkaban调度的任务类型:
1、shell脚本
2、java程序
3、MR程序
4、spark程序
5、hive的sql
6、python脚本
7、sqoop任务
启动
start-exec.sh
start-web.sh
webUI:192.168.124.136:8081
首页有四个菜单
- projects:最重要的部分,创建一个工程,所有flows将在工程中运行。
- scheduling:显示定时任务
- executing:显示当前运行的任务
- history:显示历史运行任务
概念介绍
创建工程:创建之前我们先了解下之间的关系,一个工程包含一个或多个flows,一个flow包含多个job。job是你想在azkaban中运行的一个进程,可以是简单的linux命令,可是java程序,也可以是复杂的shell脚本。一个job可以依赖于另一个job,这种多个job和它们的依赖组成的图表叫做flow。
Project的创建
Job的出创建
创建job很简单,只要创建一个以.job结尾的文本文件就行了,例如我们创建一个工作,用来打印hello,名字叫做test.job
#注:对于shell脚本中的空格,window和linux操作系统是不兼容的,所以需要进行一个转化操作
dos2unix.exe command.job
type=command
command=echo ‘hello azkaban!!!’
或者
command=hdfs dfs -get /input/score.txt /root
一个工程不可能只有一个job,稍后我们再创建多个依赖job,这也是采用azkaban的首要目的。
将Job打包成zip并上传
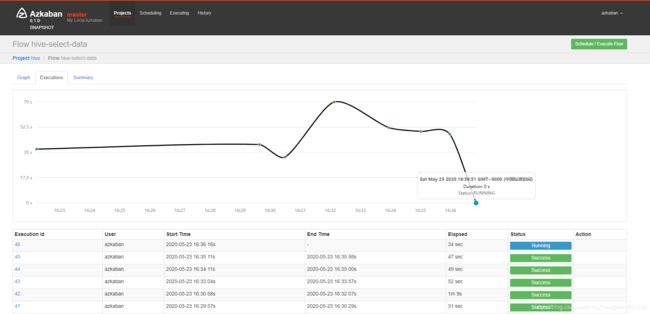
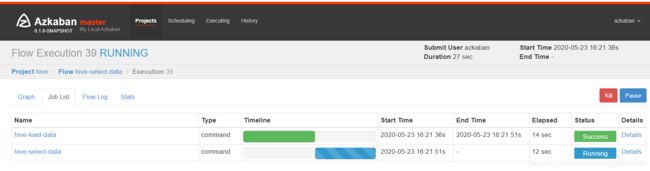
案例:定时(每分钟测试)从local导入cookie1.txt到hive的cookie1表中
hive-load-data.job
type=command
command=hive -e "load data local inpath '/root/cookie1.txt' into table cookie.cookie1;"
hive-select-data.job
type=command
command=hive -e "select count(*) from cookie.cookie1;"
dependencies=hive-load-data
(如果多个依赖,可用“,”隔开)

个人介绍:python&大数据&数据分析等技术爱好者。多所大学外聘讲师。
【Python大数据课程】
介绍:小班在线直播授课+24小时在线指导。
收获:Python大数据分析,Python大数据处理;
内容路线:Python爬虫+可视化—>Hadoop3.x----->HDFS----->ZooKeeper----->Hive3.1---->Azkaban3----->Spark2.4---->Sqoop2----->Kafka---->Flume----->Flink----->项目综合案例----->就业面试指导
环境:Centos7+全套课程所用环境和数据,均已配置完成,可直接学习(报名可获得,需网盘下载约5G左右)
备注:最好有一丢丢编程基础,学起来不费力。加微请备注:来自CSDN