【DNN】DIN原理-代码解读-应用过程中可能存在的难点
DIN(Deep Interest Network)很火,已经成功吸引了我的注意力,落地时,究竟难在什么地方?????本文的整体思路是:先熟悉原理,再看代码,然后在结合实际,猜想下可能难在什么地方。
原理
参考各位前辈的博客,结合论文,按照自己的理解习惯,汇总如下。2017年发表于 ,论文下载点击这里。
DIN要解决的问题:
针对互联网电子商务领域,数据特点:Diversity、Local Activation。
DIN给出的解决方案:
- 使用用户兴趣分布来表示用户多种多样的兴趣爱好
- 使用Attention机制来实现Local Activation
- 针对模型训练,提出了Dice激活函数,自适应正则,显著提升了模型性能与收敛速度
名词解释:
Diversity:
用户在访问电商网站时会对多种商品都感兴趣。也就是用户的兴趣非常的广泛。我理解是用户行为多样性,可能看看裙子,看看水果。
Local Activation:
用户是否会点击推荐给他的商品,仅仅取决于历史行为数据中的一小部分,而不是全部。我理解是用户行为的连锁反应,就好比,买了泳衣、太阳镜、遮阳帽,猜测你可能要去海边,去海边还需要什么商品呢?防晒、沙滩鞋等,需要重海量候选集合中,推荐给该用户,这样成单可能性会高一些。可以认为是商品聚焦的一个操作(如何根据购买过的一些商品,猜测要去海边呢?有如何将海边相关的商品贴上海边的标签呐?)。
DIN工作的切入点是什么?
将DNN应用于CTR预估,比如:Wide&Deep, DeepFM等,这些方法的优点在于:相比于原来的Logistic Regression方法,大大减少了人工特征工程的工作量。缺点:在电子商务领域中,用户的历史行为数据(User Behavior Data)中包含大量的用户兴趣信息,之前的研究并没有针对Behavior data特殊的结构(Diversity + Local Activation)进行建模。DIN来了。
针对Diversity:
针对用户广泛的兴趣,DIN用an interest distribution去表示。(怎么去构建兴趣分布?)
针对Local Activation:
DIN借鉴机器翻译中的Attention机制,设计了一种attention-like network structure, 针对当前候选Ad,去局部的激活(Local Activate)相关的历史兴趣信息(网络中怎么操作?)。和当前候选Ad相关性越高的历史行为,会获得更高的attention score,从而会主导这一次预测(如果最近的历史行为中同一天,下单了泳衣和登山鞋,激活哪个兴趣呢?依据是什么?)。
当DNN深度比较深(参数非常多),输入又非常稀疏的时候,很容易过拟合。DIN提出Adaptive regularizaion来防止过拟合,效果显著。
Attention机制解决的问题:用户行为特征中会出现multi-hot,长度不一致问题
CTR中输入普遍存在的特点:高维度稀疏。涉及到用户行为数据时,每个用户的历史行为id长度是不同的,为了得到一个固定长度的Embedding Vector表示,原来的做法是在Embedding Layer后面增加一个Pooling Layer。Pooling可以用sum或average。最终得到一个固定长度的Embedding Vector,是用户兴趣的一个抽象表示,常被称作User Representation。缺点是会损失一些信息。
DIN使用Attention机制来解决这个问题。Attention机制来源于Neural Machine Translation(NMT)。DIN使用Attention机制去更好的建模局部激活。在DIN场景中,针对不同的候选广告需要自适应地调整User Representation。也就是说:在Embedding Layer -> Pooling Layer得到用户兴趣表示的时候,赋予不同的历史行为不同的权重,实现局部激活。从最终反向训练的角度来看,就是根据当前的候选广告,来反向的激活用户历史的兴趣爱好,赋予不同历史行为不同的权重。(候选广告和历史兴趣是相互"扶持"的,可以理解为:由候选广告将历史行为中与候选广告相关的表示提权,历史行为分布变化后,又能给候选广告带来指导,输出哪个候选广告匹配性更好,也就是给用户推送哪个广告。)
模型框架
下面是论文给出的模型框架,左边是base模型,右边是DIN实验模型。从整体上来看,模型的输入方面,对历史行为进行SUM pooling前,有一个权重学习操作——activation unit,给用户有过行为的goods id的向量加上权重weight。最右边是对加权的网络结构进行了放大,能清楚的看到,用户历史行为和候选广告作为输入,先进行内积,然后再跟输入concat,DIce激活,经过线性变换,得到权重。(理解:利用了实体embeding后,在同一空间内,具有语义信息,可计算相似性,如果越相似,得到的weight会越大,真是妙~)
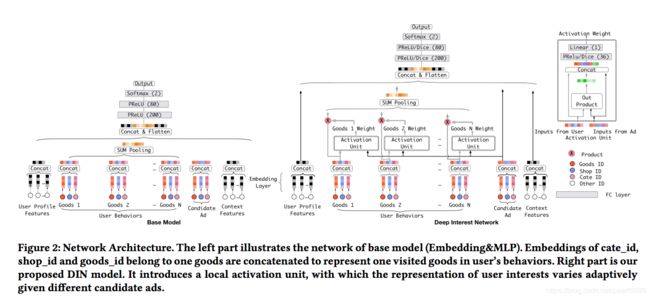
关于问题:如果最近的历史行为中同一天,下单了泳衣和登山鞋,激活哪个兴趣呢?依据是什么?
文中给出了解答,用户兴趣不再是一个点,而是一个一个分布,一个多峰的函数。这样即使在低维空间,也可以获得几乎无限强的表达能力。一个峰就表示一个兴趣,峰值的大小表示兴趣强度。那么针对不同的候选广告,用户的兴趣强度是不同的,也就是说随着候选广告的变化,用户的兴趣强度不断在变化。同意用户针对不同的广告有不同的用户兴趣表示(嵌入向量不同)。
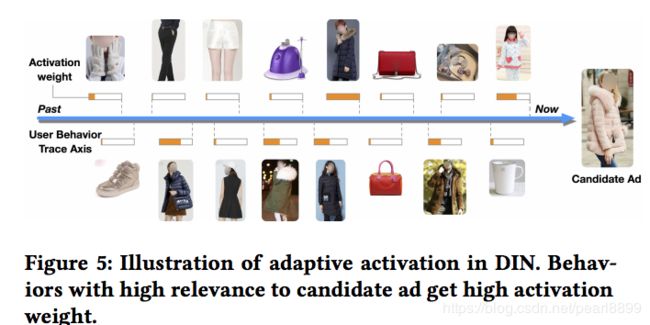
在上文的attention部分,说过用户历史行为的权重和候选广告之间相互作用,论文从结果上给出了验证,下图候选广告为羽绒服,我们看到用户历史行为中有关羽绒服的权重会更大一些。
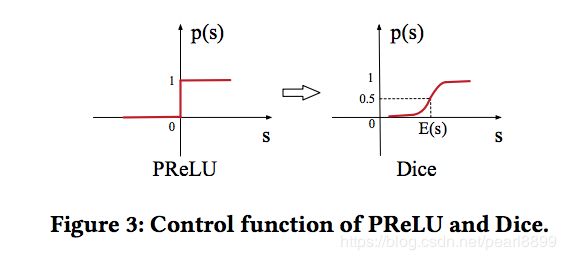
激活函数
无论是ReLU还是PReLU突变点都在0,论文里认为,对于所有输入不应该都选择0点为突变点而是应该依赖于数据的。于是提出了一种data dependent的方法:Dice激活函数。形式如下:
从p(s)的公式中,我们也能看到跟输入数据的期望和方差有关系,不同数据分布,会对激活函数产生不同影响。
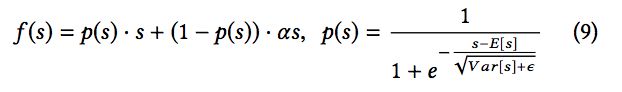
Adaptive Regularization-----正则VS稀疏
由于深度模型比较复杂,输入又非常稀疏,导致参数非常多,不出意外的过拟合了。
CTR中输入稀疏而且维度高,已有的L1 L2 Dropout防止过拟合的办法,论文中尝试后效果都不是很好。用户数据符合 长尾定律long-tail law,也就是说很多的feature id只出现了几次,而一小部分feature id出现很多次。这在训练过程中增加了很多噪声,并且加重了过拟合。
对于这个问题一个简单的处理办法就是:人工的去掉出现次数比较少的feature id。缺点是:损失的信息不好评估;阈值的设定非常的粗糙。
DIN给出的解决方案是:
- 针对feature id出现的频率,来自适应的调整他们正则化的强度;
- 对于出现频率高的,给与较小的正则化强度;
- 对于出现频率低的,给予较大的正则化强度。
作者实践发现出现频率高的物品无论是在模型评估还是线上收入中都有较大影响。
评价指标
损失函数使用了交叉熵损失函数:
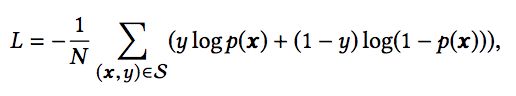
使用gAUC,找了一篇文章来理解gAUC和AUC之间的区别。AUC:分别随机从政府样本集中抽取一个正负样本,正样本的预测值大于负样本的概率。AUC作为排序的评价指标本身具有一定的局限性,它衡量的是整体样本间的排序能力,对于计算广告领域来说,它衡量的是不同用户对不同广告之间的排序能力,而线上环境往往需要关注同一个用户的不同广告之间的排序能力。DIN使用的是gAUC,在单个用户AUC的基础上,按照点击次数或展示次数进行加权平均,消除了用户偏差对模型的影响。这个还需要再理解理解...
总结
- 用户有多个兴趣爱好,访问了多个good_id,shop_id。为了降低纬度并使得商品店铺间的算术运算有意义,我们先对其进行Embedding嵌入。那么我们如何对用户多种多样的兴趣建模那?使用Pooling对Embedding Vector求和或者求平均。同时这也解决了不同用户输入长度不同的问题,得到了一个固定长度的向量。这个向量就是用户表示,是用户兴趣的代表。
- 但是,直接求sum或average损失了很多信息。所以稍加改进,针对不同的behavior id赋予不同的权重,这个权重是由当前behavior id和候选广告共同决定的。这就是Attention机制,实现了Local Activation。
- DIN使用activation unit来捕获local activation的特征,使用weighted sum pooling来捕获diversity结构。
- 在模型学习优化上,DIN提出了Dice激活函数、自适应正则 ,显著的提升了模型性能与收敛速度。
代码
阿里巴巴的XDL工具开发,代码点击这里。里面包含了DIN,还有其衍生模型DIEN等模型的代码。找到代码阅读工具sublime,打开工具包X-deeplearning,找想了解的部分。
看下class Model_DIN(Model):下面的attention layer
class Model_DIN(Model):#捡着好奇的看
with tf.name_scope('Attention_layer'):
attention_output = din_attention(
#候选广告的embeding,历史行为embeding,attention的大小,这个tensors.mask目前不知做什么的
self.item_eb, self.item_his_eb, self.attention_size, self.tensors.mask)
#将attention的输出相加,按行求和
att_fea = tf.reduce_sum(attention_output, 1)进入din_attention()函数,在utils.py的308行,揭开庐山真面目:
def din_attention(query, facts, attention_size, mask, stag='null', mode='SUM', softmax_stag=1, time_major=False, return_alphas=False):
if isinstance(facts, tuple):
# In case of Bi-RNN, concatenate the forward and the backward RNN
# outputs.
#将行为序列的embeding列拼接
facts = tf.concat(facts, 2)
print ("querry_size mismatch")
query = tf.concat(values=[
query,
query,
], axis=1)
if time_major:
# (T,B,D) => (B,T,D)
facts = tf.array_ops.transpose(facts, [1, 0, 2])
mask = tf.equal(mask, tf.ones_like(mask))
# D value - hidden size of the RNN layer
facts_size = facts.get_shape().as_list()[-1]
querry_size = query.get_shape().as_list()[-1]
queries = tf.tile(query, [1, tf.shape(facts)[1]])
queries = tf.reshape(queries, tf.shape(facts))
din_all = tf.concat([queries, facts, queries - facts, queries * facts], axis=-1)
d_layer_1_all = tf.layers.dense(
din_all, 80, activation=tf.nn.sigmoid, kernel_initializer=get_tf_initializer(), name='f1_att' + stag)
d_layer_2_all = tf.layers.dense(
d_layer_1_all, 40, activation=tf.nn.sigmoid, kernel_initializer=get_tf_initializer(), name='f2_att' + stag)
d_layer_3_all = tf.layers.dense(
d_layer_2_all, 1, activation=None, kernel_initializer=get_tf_initializer(), name='f3_att' + stag)
d_layer_3_all = tf.reshape(d_layer_3_all, [-1, 1, tf.shape(facts)[1]])
scores = d_layer_3_all
# Mask
# key_masks = tf.sequence_mask(facts_length, tf.shape(facts)[1]) # [B, T]
key_masks = tf.expand_dims(mask, 1) # [B, 1, T]
paddings = tf.ones_like(scores) * (-2 ** 32 + 1)
scores = tf.where(key_masks, scores, paddings) # [B, 1, T]
# Scale
# scores = scores / (facts.get_shape().as_list()[-1] ** 0.5)
# Activation
if softmax_stag:
scores = tf.nn.softmax(scores) # [B, 1, T]
# Weighted sum
if mode == 'SUM':
output = tf.matmul(scores, facts) # [B, 1, H]
# output = tf.reshape(output, [-1, tf.shape(facts)[-1]])
else:
scores = tf.reshape(scores, [-1, tf.shape(facts)[1]])
output = facts * tf.expand_dims(scores, -1)
output = tf.reshape(output, tf.shape(facts))
return outputdice激活函数的代码:
def dice(_x, axis=-1, epsilon=0.000000001, name=''):
with tf.variable_scope(name, reuse=tf.AUTO_REUSE):
alphas = tf.get_variable('alpha' + name, [_x.get_shape()[-1]],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
input_shape = list(_x.get_shape())
reduction_axes = list(range(len(input_shape)))
del reduction_axes[axis]
broadcast_shape = [1] * len(input_shape)
broadcast_shape[axis] = input_shape[axis]
# case: train mode (uses stats of the current batch)
#均值,用于计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值,主要用作降维或者计算tensor(图像)的平均值。
mean = tf.reduce_mean(_x, axis=reduction_axes)
brodcast_mean = tf.reshape(mean, broadcast_shape)
#求输入s的均方差
std = tf.reduce_mean(tf.square(_x - brodcast_mean) +
epsilon, axis=reduction_axes)
#对应论文中的根号下var[s]
std = tf.sqrt(std)
brodcast_std = tf.reshape(std, broadcast_shape)
#p(s)中指数部分的计算
x_normed = (_x - brodcast_mean) / (brodcast_std + epsilon)
# x_normed = tf.layers.batch_normalization(_x, center=False, scale=False)
x_p = tf.sigmoid(x_normed)
return alphas * (1.0 - x_p) * _x + x_p * _x难点
如果不在阿里巴巴,想要落地,难点,我猜测有以下几点:
1.构建数据。用户的行为序列如果获取?需要再线上收集打印,当然也可以使用离线数据,使用hive,将一个用户的行为聚合机器。
2.环境搭建。如果公司有自己的深度模型学习工具,不支持自定义的话,可能要要跨部门沟通下,或者自己重新搞一套流程离线和线上都使用。
3.线上环境支持。使用tf的比较多,有tf模型,到线上调用,整个链路应该要有很多工作,要申请tfserving服务,然后申请机器,用来给模型打分,还有模型的压缩之类的操作,感觉一个人要扛起整个大组的样子,搞不上线,也不奇怪了。
参考
1.https://zhuanlan.zhihu.com/p/39439947
2.论文https://arxiv.org/pdf/1706.06978.pdf
3.强推盖坤演讲视频:http://www.itdks.com/dakalive/detail/3166