卡尔曼滤波推导
本文为原创文章,转载请注明出处:https://blog.csdn.net/q_z_r_s
| 机器感知 一个专注于SLAM、三维重建、机器视觉等相关技术文章分享的公众号  |
卡尔曼滤波推导
1. 射影理论
卡尔曼滤波器是线性最小方差估计,也叫最优滤波器,再几何上,卡尔曼滤波估值是状态变量在由观测生成的线性空间上的射影。因此射影理论是卡尔曼滤波推到的基本工具。
1.1 线性最小方差估计和射影
【定义】由 m × 1 m×1 m×1 维随机变量 y ∈ R m y \in R^m y∈Rm 的线性函数估计 n × 1 n \times 1 n×1 维随机变量 x ∈ R n x \in R^n x∈Rn ,记估值为
(1.1) x ^ = b + A y , b ∈ R n , A ∈ R n × m \hat{x} = b + Ay, b \in R^n, A \in R^{n \times m} \tag{1.1} x^=b+Ay,b∈Rn,A∈Rn×m(1.1)
若估值 x ^ \hat{x} x^ 极小化性能指标为 J = E [ ( x − x ^ ) T ( x − x ^ ) ] J=E[(x-\hat{x})^T(x-\hat{x})] J=E[(x−x^)T(x−x^)] ,则称 x ^ \hat{x} x^ 为随机变量 x x x 的线性最小方差估计。
将 ( 1.1 ) (1.1) (1.1) 式代入极小化性能指标可得
(1.2) J = E [ ( x − b − A y ) T ( x − b − A y ) ] J=E[(x-b - Ay)^T(x-b - Ay)] \tag{1.2} J=E[(x−b−Ay)T(x−b−Ay)](1.2)
为了求性能指标极小值,分别求关于变量 b b b 和变量 A A A 的偏导数
(1.3) ∂ J ∂ b = − 2 E ( x − b − A y ) = 0 \frac {\partial J}{\partial b} = -2E(x-b-Ay) = 0 \tag{1.3} ∂b∂J=−2E(x−b−Ay)=0(1.3)
(1.4) ∂ J ∂ A = − P y x T − P x y + 2 A P y y = 0 \frac{\partial J}{\partial A} = -P_{yx}^T-P_xy + 2AP_{yy} = 0 \tag{1.4} ∂A∂J=−PyxT−Pxy+2APyy=0(1.4)
通过 ( 3 ) ( 4 ) (3) (4) (3)(4)可解得
(1.5) b = E x − A E y b = Ex-AEy\tag{1.5} b=Ex−AEy(1.5)
(1.6) A = P x y P y y − 1 A=P_{xy} P_{yy}^{-1}\tag{1.6} A=PxyPyy−1(1.6)
上述结果可概括为如下定理:
【定理】有随机变量 y ∈ R m y \in R^m y∈Rm 对随机变量 x ∈ R n x \in R^n x∈Rn 的线性最小方差估计公式为
(1.7) x ^ = E x + P x y P y y − 1 ( y − E y ) \hat{x} = Ex + P_{xy} P_{yy}^{-1}(y-Ey) \tag{1.7} x^=Ex+PxyPyy−1(y−Ey)(1.7)
其中假设 E x , E y , P x y , P y y Ex, Ey, P_{xy}, P_{yy} Ex,Ey,Pxy,Pyy均存在。
【推论】无偏性 E x ^ = E x E\hat{x} = Ex Ex^=Ex。
证明 E x ^ = E [ E x + P x y P y y − 1 ( y − E y ) ] = E x + P x y P y y − 1 ( E y − E y ) = E x E\hat{x} = E[Ex+P_{xy}P_{yy}^{-1}(y-Ey)] = Ex+P_{xy}P_{yy}^{-1}(Ey-Ey)=Ex Ex^=E[Ex+PxyPyy−1(y−Ey)]=Ex+PxyPyy−1(Ey−Ey)=Ex
【推论】正交性 E [ ( x − x ^ ) y T ] = 0 E[(x-\hat{x})y^T]=0 E[(x−x^)yT]=0。
证明
E [ ( x − x ^ ) y T ] = E [ ( x − E x − P x y P y y − 1 ( y − E y ) ) y T = E [ ( x − x ^ ) ( y − E y ) T ] = E [ ( x − E x − P x y P y y − 1 ( y − E y ) ) ( y − E y ) T ] = P x y − P x y P y y − 1 P y y = P x y − P x y = 0 E[(x-\hat{x})y^T] =E[(x-Ex-P_{xy}P_{yy}^{-1}(y-Ey))y^T =E[(x-\hat{x})(y-Ey)^T]\\ =E[(x-Ex-P_{xy}P_{yy}^{-1}(y-Ey))(y-Ey)^T] =P_{xy}-P_{xy}P_{yy}^{-1}P_{yy} \\ = P_{xy}-P_{xy} =0 E[(x−x^)yT]=E[(x−Ex−PxyPyy−1(y−Ey))yT=E[(x−x^)(y−Ey)T]=E[(x−Ex−PxyPyy−1(y−Ey))(y−Ey)T]=Pxy−PxyPyy−1Pyy=Pxy−Pxy=0
其中,引入 E [ ( x − x ^ ) E y T ] = 0 E[(x-\hat{x}){Ey}^T]=0 E[(x−x^)EyT]=0做辅助计算。此推论表明,真实值与估值之差与 y y y不相关,我们称 x − x ^ x-\hat{x} x−x^与 y y y不相关为 x − x ^ x-\hat{x} x−x^与 y y y正交(垂直),记为 ( x − x ^ ) ⊥ y (x-\hat{x})\bot y (x−x^)⊥y,并称 x ^ \hat{x} x^为 x x x在 y y y上的射影,记为 x ^ = p r o j ( x ∣ y ) \hat{x}=proj(x|y) x^=proj(x∣y)。
【定义】由 y ( 1 ) , ⋅ ⋅ ⋅ , y ( k ) ∈ R m y(1),···, y(k)\in R^m y(1),⋅⋅⋅,y(k)∈Rm张成的线性流行 L ( y ( 1 ) , ⋅ ⋅ ⋅ , y ( k ) ) L(y(1),···,y(k)) L(y(1),⋅⋅⋅,y(k))定义为
L ( y ( 1 ) , ⋅ ⋅ ⋅ , y ( k ) ) Δ ‾ ‾ L ( w ) L ( w ) = y ∣ y = A w + b , ∀ b ∈ R n , ∀ A ∈ R n × k m L(y(1),···, y(k)) \underline{\underline{\Delta}}L(w)\\ L(w) = {y|y=Aw+b, \forall b \in R^n, \forall A \in R^{n \times km}} L(y(1),⋅⋅⋅,y(k))ΔL(w)L(w)=y∣y=Aw+b,∀b∈Rn,∀A∈Rn×km
引入分块矩阵
A = [ A 1 , ⋯ , A k ] , A i ∈ R n × m A=[A_1, \cdots , A_k], A_i \in R^{n \times m} A=[A1,⋯,Ak],Ai∈Rn×m
则有
L ( w ) = y ∣ y = ∑ i = 1 k A i y ( i ) + b , ∀ A i ∈ R n × m , ∀ b ∈ R n = L ( y ( 1 ) , ⋅ ⋅ ⋅ , y ( k ) ) L(w)={y|y=\sum_{i=1}^{k}A_iy(i)+b, \forall A_i \in R^{n \times m}, \forall b \in R^n }=L(y(1),···, y(k)) L(w)=y∣y=i=1∑kAiy(i)+b,∀Ai∈Rn×m,∀b∈Rn=L(y(1),⋅⋅⋅,y(k))
【定义】基于随机变量 y ( 1 ) , ⋅ ⋅ ⋅ , y ( k ) ∈ R m y(1),···, y(k) \in R^m y(1),⋅⋅⋅,y(k)∈Rm 对随机变量 x ∈ R n x \in R^n x∈Rn 的线性最小方差估计 x ^ \hat{x} x^ 定义为
x ^ = p r o j ( x ∣ w ) = p r o j ( x ∣ y ( 1 ) , ⋅ ⋅ ⋅ , y ( k ) ) \hat{x}=proj(x|w)=proj(x|y(1),···, y(k)) x^=proj(x∣w)=proj(x∣y(1),⋅⋅⋅,y(k))
也称 x ^ \hat{x} x^ 为 x x x 在线性流形 L ( w ) L(w) L(w) 或 L ( y ( 1 ) , ⋅ ⋅ ⋅ , y ( k ) ) L(y(1),···, y(k)) L(y(1),⋅⋅⋅,y(k)) 上的射影。
【推论】设 x ∈ R n x \in R^n x∈Rn 为零均值随机变量, y ( 1 ) , ⋅ ⋅ ⋅ , y ( k ) ∈ R m y(1),···, y(k) \in R^m y(1),⋅⋅⋅,y(k)∈Rm 为零均值,互不相关(正交)的随机变量,则有
p r o j ( x ∣ y ( 1 ) , ⋯ , y ( k ) ) = ∑ i = 1 k p r o j ( x ∣ y ( i ) ) proj(x|y(1), \cdots , y(k)) = \sum_{i=1}^k proj(x|y(i)) proj(x∣y(1),⋯,y(k))=i=1∑kproj(x∣y(i))
1.2 新息序列
【定义】设 y ( 1 ) , ⋅ ⋅ ⋅ , y ( k ) , ⋯ ∈ R m y(1),···, y(k) , \cdots \in R^m y(1),⋅⋅⋅,y(k),⋯∈Rm 是存在二阶矩的随机序列,它的新息序列(新息过程)定义为
ϵ ( k ) = y ( k ) − p r o j ( y ( k ) ∣ y ( 1 ) , ⋯ , y ( k − 1 ) ) , k = 1 , 2 , ⋯ \epsilon(k) = y(k) - proj(y(k)|y(1),\cdots,y(k-1)), k=1, 2,\cdots ϵ(k)=y(k)−proj(y(k)∣y(1),⋯,y(k−1)),k=1,2,⋯
并定义 y ( k ) y(k) y(k) 的一步最优预报估值为
y ^ ( k ∣ k − 1 ) = p r o j ( y ( k ) ∣ y ( 1 ) , ⋯ , y ( k − 1 ) ) \hat{y}(k|k-1) = proj(y(k)|y(1),\cdots,y(k-1)) y^(k∣k−1)=proj(y(k)∣y(1),⋯,y(k−1))
因而新息序列可定义为
ϵ ( k ) = y ( k ) − y ^ ( k ∣ k − 1 ) , k = 1 , 2 , ⋯ \epsilon(k) = y(k) -\hat{y}(k|k-1), k=1, 2,\cdots ϵ(k)=y(k)−y^(k∣k−1),k=1,2,⋯
其中规定 y ^ ( 1 ∣ 0 ) = E y ( 1 ) \hat{y}(1|0) = Ey(1) y^(1∣0)=Ey(1) ,这保证 E ϵ ( 1 ) = 0 E\epsilon(1)=0 Eϵ(1)=0 。新息序列的几何意义是
ϵ ( k ) ⊥ L ( y ( 1 ) , ⋅ ⋅ ⋅ , y ( k − 1 ) ) \epsilon(k)\bot L(y(1),···, y(k-1)) ϵ(k)⊥L(y(1),⋅⋅⋅,y(k−1))
且新息序列 ϵ ( k ) \epsilon(k) ϵ(k) 是零均值白噪声(这是产生递推射影公式的基础,通过引入新息序列实现了非正交随机序列的正交化),且 L ( ϵ ( 1 ) , ⋅ ⋅ ⋅ , ϵ ( k ) ) = L ( y ( 1 ) , ⋅ ⋅ ⋅ , y ( k ) ) L(\epsilon(1),···, \epsilon(k))=L(y(1),···, y(k)) L(ϵ(1),⋅⋅⋅,ϵ(k))=L(y(1),⋅⋅⋅,y(k))。
【定理】递推射影公式
(1.8) p r o j ( x ∣ y ( 1 ) , ⋯ , y ( k ) ) = p r o j ( x ∣ y ( 1 ) , ⋯ , y ( k − 1 ) ) + E [ x ϵ T ( k ) ] [ E ϵ ( k ) ϵ T ( k ) ] − 1 ϵ ( k ) proj(x|y(1),\cdots,y(k))=proj(x|y(1),\cdots,y(k-1))+E[x\epsilon^T(k)][E\epsilon (k) \epsilon^T(k)]^{-1}\epsilon(k)\tag{1.8} proj(x∣y(1),⋯,y(k))=proj(x∣y(1),⋯,y(k−1))+E[xϵT(k)][Eϵ(k)ϵT(k)]−1ϵ(k)(1.8)
2. 卡尔曼滤波器
设动态系统模型如下
(2.1) x ( t + 1 ) = Φ x ( t ) + Γ w ( t ) x(t+1) = \Phi x(t) + \Gamma w(t)\tag{2.1} x(t+1)=Φx(t)+Γw(t)(2.1)
(2.2) y ( t ) = H x ( t ) + v ( t ) y(t)=Hx(t)+v(t)\tag{2.2} y(t)=Hx(t)+v(t)(2.2)
假设 w ( t ) w(t) w(t) 和 v ( t ) v(t) v(t) 满足如下约束条件
(2.3) E w ( t ) = 0 , E v ( t ) = 0 Ew(t)=0, Ev(t)=0 \tag{2.3} Ew(t)=0,Ev(t)=0(2.3)
(2.4) E [ w ( i ) w T ( j ) ] = Q δ i j , E [ v ( i ) v T ( j ) ] = R δ i j E[w(i)w^T(j)] = Q\delta_{ij}, E[v(i)v^T(j)] = R\delta_{ij} \tag{2.4} E[w(i)wT(j)]=Qδij,E[v(i)vT(j)]=Rδij(2.4)
(2.5) E [ w ( i ) v T ( j ) ] = 0 , ∀ i , j E[w(i)v^T(j)] = 0, \forall i, j \tag{2.5} E[w(i)vT(j)]=0,∀i,j(2.5)
其中 δ i i = 1 , δ i j = 0 ( i ≠ j ) \delta_{ii}=1, \delta_{ij}=0(i\neq j) δii=1,δij=0(i̸=j)。
下面应用射影定理推导卡尔曼滤波器,在性能指标 ( 1.2 ) (1.2) (1.2) 下,问题归结为求射影
x ^ ( j ∣ t ) = p r o j ( x ( j ) ∣ y ( 1 ) , ⋯ , y ( t ) ) \hat{x}(j|t) = proj(x(j)|y(1),\cdots,y(t)) x^(j∣t)=proj(x(j)∣y(1),⋯,y(t))
由递推射影公式 ( 1.8 ) (1.8) (1.8) 可得
x ^ ( t + 1 ∣ t + 1 ) = x ^ ( t + 1 ∣ t ) + K ( t + 1 ) ϵ ( t + 1 ) \hat{x}(t+1|t+1) = \hat{x}(t+1|t)+K(t+1)\epsilon(t+1) x^(t+1∣t+1)=x^(t+1∣t)+K(t+1)ϵ(t+1)
对 ( 2.1 ) (2.1) (2.1) 两边取射影有
(2.6) x ^ ( t + 1 ∣ t ) = Φ x ^ ( t ∣ t ) + Γ p r o j ( w ( t ) ∣ y ( 1 ) , ⋯ , y ( t ) ) \hat{x}(t+1|t) = \Phi\hat{x}(t|t)+\Gamma proj(w(t)|y(1),\cdots,y(t))\tag{2.6} x^(t+1∣t)=Φx^(t∣t)+Γproj(w(t)∣y(1),⋯,y(t))(2.6)
根据系统方程递归展开可知
x ( t ) ∈ L ( w ( t − 1 ) , ⋯ , w ( 0 ) , x ( 0 ) ) y ( t ) ∈ L ( v ( t ) , w ( t − 1 ) , ⋯ , w ( 0 ) , x ( 0 ) ) x(t) \in L(w(t-1),\cdots,w(0),x(0))\\ y(t) \in L(v(t), w(t-1),\cdots,w(0),x(0)) x(t)∈L(w(t−1),⋯,w(0),x(0))y(t)∈L(v(t),w(t−1),⋯,w(0),x(0))
由此可知
L ( y ( 1 ) , ⋯ , y ( t ) ) ⊂ L ( v ( t ) , ⋯ , v ( 1 ) , w ( t − 1 ) , ⋯ , w ( 0 ) , x ( 0 ) ) L(y(1),\cdots,y(t)) \subset L(v(t),\cdots,v(1),w(t-1),\cdots,w(0),x(0)) L(y(1),⋯,y(t))⊂L(v(t),⋯,v(1),w(t−1),⋯,w(0),x(0))
由于 x ( 0 ) , w ( t ) , v ( t ) x(0), w(t), v(t) x(0),w(t),v(t) 互不相关,所以 w ( t ) ⊥ L ( y ( 1 ) , ⋯ , y ( t ) ) w(t)\bot L(y(1),\cdots,y(t)) w(t)⊥L(y(1),⋯,y(t)) ,所以 p r o j ( w ( t ) ∣ y ( 1 ) , ⋯ , y ( t ) ) = 0 proj(w(t)|y(1),\cdots,y(t))=0 proj(w(t)∣y(1),⋯,y(t))=0 。所以式 ( 2.6 ) (2.6) (2.6) 简化为
x ^ ( t + 1 ∣ t ) = Φ x ^ ( t ∣ t ) \hat{x}(t+1|t) = \Phi\hat{x}(t|t) x^(t+1∣t)=Φx^(t∣t)
对 ( 2.2 ) (2.2) (2.2) 两边取射影有
y ^ ( t + 1 ∣ t ) = H x ^ ( t + 1 ∣ t ) + p r o j ( v ( t + 1 ) ∣ y ( 1 ) , ⋯ , y ( t ) ) \hat y(t+1|t)=H\hat x(t+1|t)+proj(v(t+1)|y(1),\cdots,y(t)) y^(t+1∣t)=Hx^(t+1∣t)+proj(v(t+1)∣y(1),⋯,y(t))
同理可得 p r o j ( v ( t + 1 ) ∣ y ( 1 ) , ⋯ , y ( t ) ) = 0 proj(v(t+1)|y(1),\cdots,y(t))=0 proj(v(t+1)∣y(1),⋯,y(t))=0 。于是有
y ^ ( t + 1 ∣ t ) = H x ^ ( t + 1 ∣ t ) \hat y(t+1|t)=H\hat x(t+1|t) y^(t+1∣t)=Hx^(t+1∣t)
引出新息表达式
ϵ ( t + 1 ) = y ( t + 1 ) − y ^ ( t + 1 ∣ t ) = y ( t + 1 ) − H x ^ ( t + 1 ∣ t ) \epsilon (t+1)=y(t+1)-\hat{y}(t+1|t)=y(t+1)-H\hat{x}(t+1|t) ϵ(t+1)=y(t+1)−y^(t+1∣t)=y(t+1)−Hx^(t+1∣t)
记误差方差阵为
x ‾ ( t ∣ t ) = x ( t ) − x ^ ( t ∣ t ) x ‾ ( t + 1 ∣ t ) = x ( t + 1 ) − x ^ ( t + 1 ∣ t ) P ( t ∣ t ) = E [ x ‾ ( t ∣ t ) x ‾ T ( t ∣ t ) ] P ( t + 1 ∣ t ) = E [ x ‾ ( t + 1 ∣ t ) x ‾ T ( t + 1 ∣ t ) ] \overline{x}(t|t) = x(t) - \hat{x}(t|t)\\ \overline{x}(t+1|t) = x(t+1) - \hat{x}(t+1|t)\\ P(t|t) = E[\overline{x}(t|t)\overline{x}^T(t|t)]\\ P(t+1|t) = E[\overline{x}(t+1|t)\overline{x}^T(t+1|t)] x(t∣t)=x(t)−x^(t∣t)x(t+1∣t)=x(t+1)−x^(t+1∣t)P(t∣t)=E[x(t∣t)xT(t∣t)]P(t+1∣t)=E[x(t+1∣t)xT(t+1∣t)]
由此,新息可变换为
ϵ ( t + 1 ) = H x ‾ ( t + 1 ∣ t ) + v ( t + 1 ) \epsilon (t+1) = H\overline{x}(t+1|t)+v(t+1) ϵ(t+1)=Hx(t+1∣t)+v(t+1)
又有
(2.7) x ‾ ( t + 1 ∣ t ) = Φ x ‾ ( t ∣ t ) + Γ w ( t ) x ‾ ( t + 1 ∣ t + 1 ) = x ‾ ( t + 1 ∣ t ) − K ( t + 1 ) ϵ ( t + 1 ) = x ‾ ( t + 1 ∣ t ) − K ( t + 1 ) ∗ ( H x ‾ ( t + 1 ∣ t ) + v ( t + 1 ) ) = [ I n − K ( t + 1 ) H ] x ‾ ( t + 1 ∣ t ) − K ( t + 1 ) v ( t + 1 ) \overline{x}(t+1|t) = \Phi \overline{x}(t|t) + \Gamma w(t)\\ \overline{x}(t+1|t+1) = \overline{x}(t+1|t) - K(t+1)\epsilon(t+1)\\ = \overline{x}(t+1|t) - K(t+1)*(H\overline{x}(t+1|t)+v(t+1))\\ =[I_n-K(t+1)H]\overline{x}(t+1|t)-K(t+1)v(t+1)\tag{2.7} x(t+1∣t)=Φx(t∣t)+Γw(t)x(t+1∣t+1)=x(t+1∣t)−K(t+1)ϵ(t+1)=x(t+1∣t)−K(t+1)∗(Hx(t+1∣t)+v(t+1))=[In−K(t+1)H]x(t+1∣t)−K(t+1)v(t+1)(2.7)
由于 x ‾ ( t ∣ t ) = x ( t ) − x ^ ( t ∣ t ) ∈ L ( v ( t ) , ⋯ , v ( 1 ) , w ( t − 1 ) , ⋯ , w ( 0 ) , x ( 0 ) ) \overline{x}(t|t)=x(t)-\hat{x}(t|t)\in L(v(t),\cdots,v(1),w(t-1),\cdots,w(0),x(0)) x(t∣t)=x(t)−x^(t∣t)∈L(v(t),⋯,v(1),w(t−1),⋯,w(0),x(0)),故有 w ( t ) ⊥ x ‾ ( t ∣ t ) w(t)\bot\overline{x}(t|t) w(t)⊥x(t∣t),由此可得 E [ w ( t ) x ‾ T ( t ∣ t ) ] = 0 E[w(t)\overline{x}^T(t|t)]=0 E[w(t)xT(t∣t)]=0。于是,由误差方差阵最后一个方程可得
P ( t + 1 ∣ t ) = Φ P ( t ∣ t ) Φ T + Γ Q Γ T P(t+1|t)=\Phi P(t|t)\Phi^T+\Gamma Q \Gamma^T P(t+1∣t)=ΦP(t∣t)ΦT+ΓQΓT
同理,由 v ( t + 1 ) ⊥ x ‾ ( t + 1 ∣ t ) v(t+1)\bot\overline{x}(t+1|t) v(t+1)⊥x(t+1∣t) 引出 E [ v ( t + 1 ) x ‾ T ( t + 1 ∣ t ) ] E[v(t+1)\overline{x}^T(t+1|t)] E[v(t+1)xT(t+1∣t)] ,可得新息误差方差阵为
E [ ϵ ( t + 1 ) ϵ T ( t + 1 ) ] = H P ( t + 1 ∣ t ) H T + R E[\epsilon(t+1)\epsilon^T(t+1)]=HP(t+1|t)H^T+R E[ϵ(t+1)ϵT(t+1)]=HP(t+1∣t)HT+R
由方程式 ( 2.7 ) (2.7) (2.7) 可得
P ( t + 1 ∣ t + 1 ) = [ I n − K ( t + 1 ) H ] P ( t + 1 ∣ t ) [ I n − K ( t + 1 ) H ] T + K ( t + 1 ) R K T ( t + 1 ) P(t+1|t+1)=[I_n-K(t+1)H]P(t+1|t)[I_n-K(t+1)H]^T+K(t+1)RK^T(t+1) P(t+1∣t+1)=[In−K(t+1)H]P(t+1∣t)[In−K(t+1)H]T+K(t+1)RKT(t+1)
易知 K ( t + 1 ) = E [ x ( t + 1 ) ϵ T ( t + 1 ) ] [ ϵ ( t + 1 ) ϵ T ( t + 1 ) ] − 1 K(t+1)=E[x(t+1)\epsilon^T(t+1)][\epsilon(t+1)\epsilon^T(t+1)]^{-1} K(t+1)=E[x(t+1)ϵT(t+1)][ϵ(t+1)ϵT(t+1)]−1 ,其中
E [ x ( t + 1 ) ϵ T ( t + 1 ) ] = E [ ( x ^ ( t + 1 ∣ t ) + x ‾ ( t + 1 ∣ t ) ) ( H x ‾ ( t + 1 ∣ t ) + v ( t + 1 ) ) T ] E[x(t+1)\epsilon^T(t+1)]=E[(\hat{x}(t+1|t)+\overline{x}(t+1|t))(H\overline{x}(t+1|t)+v(t+1))^T] E[x(t+1)ϵT(t+1)]=E[(x^(t+1∣t)+x(t+1∣t))(Hx(t+1∣t)+v(t+1))T]
又有 x ^ ( t + 1 ∣ t ) ⊥ x ‾ ( t + 1 ∣ t ) , v ( t + 1 ) ⊥ x ^ ( t + 1 ∣ t ) , v ( t + 1 ) ⊥ x ‾ ( t + 1 ∣ t ) \hat{x}(t+1|t)\bot\overline{x}(t+1|t), v(t+1)\bot\hat{x}(t+1|t), v(t+1)\bot\overline{x}(t+1|t) x^(t+1∣t)⊥x(t+1∣t),v(t+1)⊥x^(t+1∣t),v(t+1)⊥x(t+1∣t) ,可得
K ( t + 1 ) = P ( t + 1 ∣ t ) H T [ H P ( t + 1 ∣ t ) H T + R ] − 1 K(t+1) = P(t+1|t)H^T[HP(t+1|t)H^T+R]^{-1} K(t+1)=P(t+1∣t)HT[HP(t+1∣t)HT+R]−1
则可利用 K ( t + 1 ) K(t+1) K(t+1) 来简化 P ( t + 1 ∣ t + 1 ) P(t+1|t+1) P(t+1∣t+1) ,即
P ( t + 1 ∣ t + 1 ) = [ I n − K ( t + 1 ) H ] P ( t + 1 ∣ t ) P(t+1|t+1)=[I_n-K(t+1)H]P(t+1|t) P(t+1∣t+1)=[In−K(t+1)H]P(t+1∣t)
上述推导结果可概括为如下递推卡尔曼滤波器
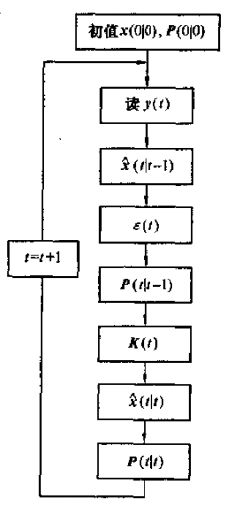
x ^ ( t + 1 ∣ t + 1 ) = x ^ ( t + 1 ∣ t ) − K ( t + 1 ) ϵ ( t + 1 ) x ^ ( t + 1 ∣ t ) = Φ x ^ ( t ∣ t ) ϵ ( t + 1 ) = y ( t + 1 ) − H x ^ ( t + 1 ∣ t ) K ( t + 1 ) = P ( t + 1 ∣ t ) H T [ H P ( t + 1 ∣ t ) H T + R ] − 1 P ( t + 1 ∣ t ) = Φ P ( t ∣ t ) Φ T + Γ Q Γ T P ( t + 1 ∣ t + 1 ) = [ I n − K ( t + 1 ) H ] P ( t + 1 ∣ t ) x ^ ( 0 ∣ 0 ) = μ 0 , P ( 0 ∣ 0 ) = P 0 \hat{x}(t+1|t+1) = \hat{x}(t+1|t) - K(t+1)\epsilon(t+1)\\ \hat{x}(t+1|t) = \Phi\hat{x}(t|t)\\ \epsilon (t+1)=y(t+1)-H\hat{x}(t+1|t)\\ K(t+1) = P(t+1|t)H^T[HP(t+1|t)H^T+R]^{-1}\\ P(t+1|t)=\Phi P(t|t)\Phi^T+\Gamma Q \Gamma^T\\ P(t+1|t+1)=[I_n-K(t+1)H]P(t+1|t)\\ \hat{x}(0|0)=\mu_0, P(0|0) = P_0 x^(t+1∣t+1)=x^(t+1∣t)−K(t+1)ϵ(t+1)x^(t+1∣t)=Φx^(t∣t)ϵ(t+1)=y(t+1)−Hx^(t+1∣t)K(t+1)=P(t+1∣t)HT[HP(t+1∣t)HT+R]−1P(t+1∣t)=ΦP(t∣t)ΦT+ΓQΓTP(t+1∣t+1)=[In−K(t+1)H]P(t+1∣t)x^(0∣0)=μ0,P(0∣0)=P0
卡尔曼滤波算法递推流程图
【定理】当动态系统模型带有控制输入 u ( t ) u(t) u(t) 时
x ( t + 1 ) = Φ x ( t ) + B ( t ) u ( t ) + Γ w ( t ) y ( t ) = H ( t ) x ( t ) + v ( t ) x(t+1) = \Phi x(t) + B(t)u(t) +\Gamma w(t)\\ y(t)=H(t)x(t)+v(t) x(t+1)=Φx(t)+B(t)u(t)+Γw(t)y(t)=H(t)x(t)+v(t)
此时的卡尔曼滤波器为
x ^ ( t + 1 ∣ t ) = Φ x ^ ( t ∣ t ) + B ( t ) u ( t ) ϵ ( t + 1 ) = y ( t + 1 ) − H x ^ ( t + 1 ∣ t ) P ( t + 1 ∣ t ) = Φ P ( t ∣ t ) Φ T + Γ Q Γ T K ( t + 1 ) = P ( t + 1 ∣ t ) H T [ H P ( t + 1 ∣ t ) H T + R ] − 1 x ^ ( t + 1 ∣ t + 1 ) = x ^ ( t + 1 ∣ t ) + K ( t + 1 ) ϵ ( t + 1 ) P ( t + 1 ∣ t + 1 ) = [ I n − K ( t + 1 ) H ] P ( t + 1 ∣ t ) x ^ ( 0 ∣ 0 ) = μ 0 , P ( 0 ∣ 0 ) = P 0 \hat{x}(t+1|t) = \Phi\hat{x}(t|t)+B(t)u(t)\\ \epsilon (t+1)=y(t+1)-H\hat{x}(t+1|t)\\ P(t+1|t)=\Phi P(t|t)\Phi^T+\Gamma Q \Gamma^T\\ K(t+1) = P(t+1|t)H^T[HP(t+1|t)H^T+R]^{-1}\\ \hat{x}(t+1|t+1) = \hat{x}(t+1|t) +K(t+1)\epsilon(t+1)\\ P(t+1|t+1)=[I_n-K(t+1)H]P(t+1|t)\\ \hat{x}(0|0)=\mu_0, P(0|0) = P_0 x^(t+1∣t)=Φx^(t∣t)+B(t)u(t)ϵ(t+1)=y(t+1)−Hx^(t+1∣t)P(t+1∣t)=ΦP(t∣t)ΦT+ΓQΓTK(t+1)=P(t+1∣t)HT[HP(t+1∣t)HT+R]−1x^(t+1∣t+1)=x^(t+1∣t)+K(t+1)ϵ(t+1)P(t+1∣t+1)=[In−K(t+1)H]P(t+1∣t)x^(0∣0)=μ0,P(0∣0)=P0
3.扩展卡尔曼滤波器
系统方程如下
x t = g ( u t , x t − 1 ) + ϵ t z t = h ( x t ) + δ t x_t = g(u_t,x_{t-1})+\epsilon_t\\ z_t = h(x_t)+\delta_t xt=g(ut,xt−1)+ϵtzt=h(xt)+δt
算法如下
μ ‾ t = g ( u t , μ t − 1 ) ∑ t ^ = G t ∑ t − 1 ^ G t T + R t K t = ∑ t ^ H t T ( H t ∑ t ^ H t T + Q t ) − 1 μ t = μ ‾ t + K t ( z t − h ( μ ‾ t ) ) ∑ t = ( I − K t H t ) ∑ t ^ \overline\mu_t=g(u_t,\mu_{t-1})\\ \hat{\sum_t}=G_t\hat{\sum_{t-1}}G_t^T+R_t\\ K_t=\hat{\sum_t}H_t^T(H_t\hat{\sum_t}H_t^T+Q_t)^{-1}\\ \mu_t=\overline\mu_t+K_t(z_t-h(\overline\mu_t))\\ \sum_t=(I-K_tH_t)\hat{\sum_t} μt=g(ut,μt−1)t∑^=Gtt−1∑^GtT+RtKt=t∑^HtT(Htt∑^HtT+Qt)−1μt=μt+Kt(zt−h(μt))t∑=(I−KtHt)t∑^
其中
| KF | EKF | |
|---|---|---|
| 状态预测 | A t μ t − 1 + B t u t A_t\mu_{t-1}+B_tu_t Atμt−1+Btut | g ( u t , μ t − 1 ) g(u_t,\mu_{t-1}) g(ut,μt−1) |
| 测量预测 | C μ ‾ t C\overline{\mu}_t Cμt | h ( μ ‾ t ) h(\overline\mu_t) h(μt) |
| 最有估计 | x ^ ( t ∥ t ) \hat{x}(t\|t) x^(t∥t) | μ t \mu_t μt |
| 状态预测 | x ^ ( t + 1 ∥ t ) \hat{x}(t+1\|t) x^(t+1∥t) | μ ‾ t + 1 \overline\mu_{t+1} μt+1 |
参考文献
[1] 邓自立. 最优估计理论及其应用[M]. 哈尔滨工业大学出版社, 2005.
[2] Thrun S. Probabilistic robotics[M]. MIT Press, 2006:52-57.
