接口技术【1】PCIe入门简介 -- PCI背景知识
接口技术【1】PCIe入门简介
- PCI接口基础
- PCI的历史
- PCI系统基础
- PCI仲裁和目标
- PCI逻辑时序
- 反射信号模型Reflected-Wave Signaling
- PCI桥接
- PCI总线架构
- PCI数据传输机制
- PIO
- Direct Memory Access (DMA)
- Peer-to-Peer
- PCI总线仲裁
- PCI无效机制
- PCI中断处理
- PCI错误处理
- PCI地址
- PCI配置周期
- PCI功能配置寄存器
- 更高带宽的PCI
- 总结
PCI接口基础
Peripheral Component Interface (PCI)外设部件互联标准接口作为PCIe的前身,奠定了此种接口的基础。理解过去的PCI接口能更好地理解现在的PCIe,因为使用PCIe的软件大多和PCI一样,也就是向上兼容
PCI的历史
在20世纪90年代早期,为了克服个人计算机PC中的外围设备短板,PCI接口诞生了。当时的标准是IBM的Advanced Technology (AT)接口,也被叫做Industry Standard Architecture (ISA)接口。ISA接口对于286 16位机来说足够,但对于更新的32位机以及其他更先进的外围设备就不够了。另外ISA接口的硬件连接件尺寸很大接线很多,因此PC需要一种新的接口。
当时PCI的竞争对手包括IBM的Micro-Channel Architecture (MCA), 和Extended ISA (EISA)等。然而其他的接口都有各自的缺点,最终PCI被接纳为标准,并成立了PCI Special Interest Group (PCISIG)组织来发展该标准。
几年后发展出了PCI eXtended (PCI-X),之后还有PCI-X 2.0 提高速度到4GB/s。不过这几个发展出来的接口保持了原来的并行接口,导致了些遗留问题。PCI的低功耗信号传输模型导致传输频率越高,能接的设备也越少,这个在之后会仔细介绍。到了PCI-X 2.0时,高速甚至导致其变成了一个点对点传输接口。
正是这个原因,后来PCI就开始向从并行接口模型转向串行接口模型发展,也就是之后的PCIe。

PCI系统基础
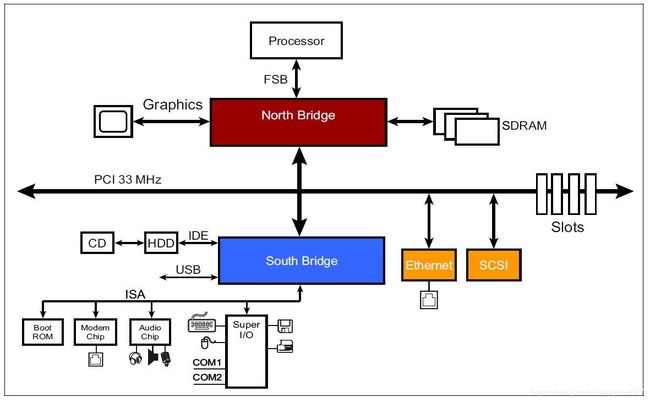
上图看到的是PCI接口的基础模型,包括一个north bridge北桥和south bridge南桥。之所以叫南桥和北桥不过是因为大家总是这么画,于是很自然的联想到了上北下南…
北桥一般用来连接processor处理器,图像接口,存储接口和PCI总线。南桥用来连接PCI总线和外围设备,同时南桥也通常给PCI总线提供系统复位信号,时钟信号和错误报告信号。
PCI仲裁和目标
在PCI结构中每个设备都可以有最多8个功能,用数字0到7编号,从0开始记。每个功能作为PCI结构中的一个目标,可以开启总线信息传输。总线仲裁用一对信号REQ#和GNT#来决定谁使用总线,设备发送Request (REQ#)给总线仲裁申请使用,总线仲裁决定哪一个设备可以接下来使用总线,并通过Grant (GNT#)通知。每次总线的一个传输结束时,收到GNT#信号的设备就可以开始传输信息。
PCI逻辑时序
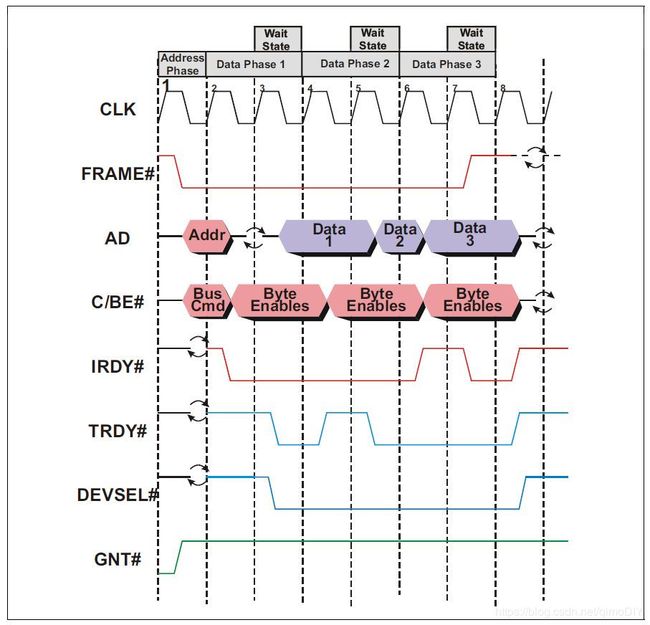
- 第一个时钟上升沿,FRAME#(表示总线是否被使用)和IRDY#(表示总线仲裁准备接收数据)都未被激活,表示总线处于空闲状态。同时GNT#被拉低激活了,表示这个device被选为使用总线的下一个目标
- 第二个时钟上升沿,FRAME#被拉低激活,表示一个新的信息传递流程开始了。同时AD和C/BE#分别把地址和命令传输给此device,其他所有device也会获取信息并查找该地址是否和自己相关
- 第三个时钟上升沿,总线仲裁通过拉低IDRY#表示其准备好接受数据。这时在时序图中看到一个环箭头,它表示AD接口的使用权转交给device,原来总线仲裁用来传递地址的接口被用来接收信号,从output变成input。信号传输不会立刻开始,因为哪怕很短时间的总线竞争(两个信号源同时输出信号)都是很危险的
- 第四个时钟上升沿,此device解码出了这个地址并通过拉低DEVSEL# (device select)来回应开始信号传输。同时device拉低TRDY# (target ready)表示自己已经把信号的第一部分发到AD接口。TRDY#信号不一定要在此时激活,它可以有最多16个时钟的等待时间,等device准备好了再传输信号。当IRDY#和TRDY#同时被拉低激活,也就是发送方和接收方都准备好时才传输。至于数据长度,总线仲裁知道而device并不知道,只要FRAME#还被激活,说明仲裁还要求device传输下一个data,因此device需要随时检查FRAME#信号
- 第五个时钟上升沿,此device还没准备好传输下一个data,因此将TRDY#拉高解除激活,暂停传输。这种暂停发送方和接收方都可以进行,只要保持在8个连续时钟周期之内即可
- 第六个时钟上升沿,第二个data传递,由于FRAME#信号还没解除激活,说明总线仲裁还要更多数据
- 第七个时钟上升沿,总线仲裁将IRDY#拉高接触激活,暂停传输
- 第八个时钟上升沿,第三个data传递,此时FRAME#被拉高接触激活,意味着总线仲裁已经收到了足够的数据,在这之后所有的控制信号都被关闭
反射信号模型Reflected-Wave Signaling
PCI架构利用了反射信号Reflected-Wave Signaling来降低功耗。在高速信号传输中,反射信号往往会导致信号畸变,但PCI是个特例,它利用了这一特性,使得输入电压减半。
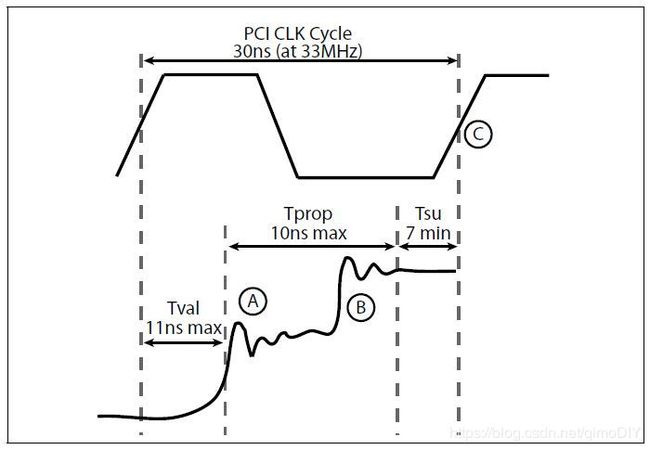
PCI结构最多可以接32个设备,但实际操作中这个数目只能到10到12个设备,正是因为这个反射信号模型。在这个模型中,输入信号只把电压驱动到一半,电压变化形成的波传播到总线末端,PCI总线设计中总线末端不接任何东西,因此阻抗是无穷,电波碰到末端就像撞到一堵墙会弹回并和原来的信号叠加到正常电压。而传播到起点时,其低阻抗阻止电波继续传递。
从发出信号到反射回原点的周期必须小于数据传递周期,因此基础频率33MHz的设计和总线本身尺寸也有关系,尺寸越大周期越长。增加总线上接的设备也算增加总线长度,因此能接的设备少于设计的32。
PCI桥接

随着外围设备越来越多,PCI的速度越来越跟不上,也就成了PC系统中的瓶颈,为了接更多设备,就需要PCI桥接,如上图所示。
每一个PCI桥接都相当于开启一个新的PCI总线,可以多接10到12个设备,当然也可以接桥接,总共能桥接出256个PCI总线。
PCI总线架构
PCI数据传输机制
PCI有三种数据传输方式:可编程IO(PIO),Peer-to-peer和DMA。就像下图所示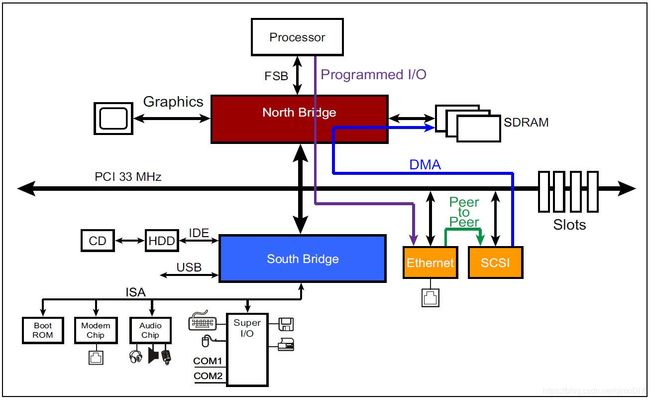
PIO
CPU的处理速度要比其他外围设备都快,因此在早期CPU资源比较富余的时候会使用这种简单粗暴的传输方式,也就是把数据或者地址丢给CPU,让CPU帮你存取数据。
这种方式简单粗暴,但效率很低,首先每次读取都需要两个时钟周期,另外CPU会花大量时间做这种没有意义的事情,而不能把资源花在其他的计算上。
Direct Memory Access (DMA)
DMA是专门替CPU处理数据存取的处理器,对数据传输结构没有影响,只是不会再占用CPU的计算资源
Peer-to-Peer
在少数情况下,如果某个设备可以作为master存在,并且它和另一个设备的数据传输格式是一样的,那么它们之间的数据传递就不需要再经过北桥,而是直接彼此间传输。
PCI总线仲裁
由于现在大多数的PCI设备都可以作为master存在,都可以使用DMA和peer-to-peer数据传输,因此PCI架构中需要仲裁机制,每个要使用总线的设备都要向仲裁申请权限。仲裁需要在不卡住任何设备的情况下“雨露均沾”的给予权限
PCI无效机制
PCI结构有时候效率不高,举个例子,网络传输的时候,北桥启动了向网络设备读取数据的操作,但网络设备不会立刻传回数据。此时网络设备有两个选项,一个是暂停传输,但这个只能持续16个时钟周期,另一个是激活STOP#信号,告诉使用总线的设备终止传输数据。第二种选项可以防止PCI设备过长占用总线,总线仲裁可以把总线权限给其他设备使用,直到准备好需要传输的数据再申请总线
PCI中断处理
PCI设备可以使用四个中断信号的其中一个(INTA#, INTB#, INTC#和INTD#)。当其中任意一个中断信号被激活的时候,中断控制器会送一个终端申请给CPU,让CPU处理这个中断申请。
PCI错误处理
PCI设备可以选择性的侦测并报告传输地址和数据的奇偶校验错误。PCI一般传输的都是偶信号,每次探测到奇信号时,PCI设备会检查地址和数据看是否有错误,如果有错则激活PERR#(parity error)信号。如果传输的数据错误了可以通过重新传输来解决,但如果是地址错误就比较麻烦了,这种情况会激活系统错误信号SERR# (system error),也就是老系统中的“死机蓝屏”。
PCI地址
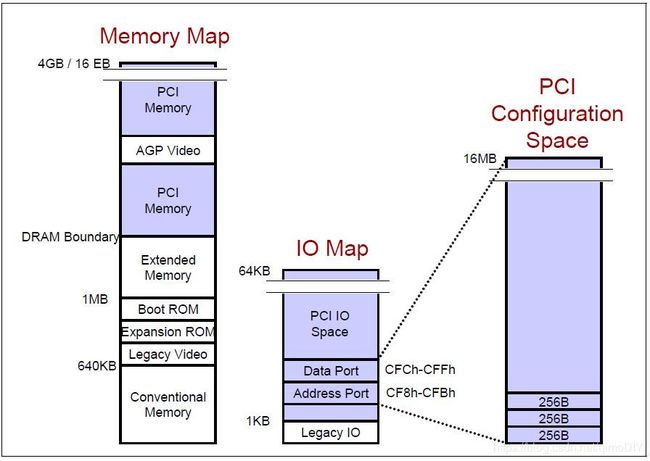
PCI架构支持三个地址空间,存储,IO和配置地址空间。x86处理器可以直接访问存储和IO地址空间。PCI设备可以支持32位或者64位存储地址;对于IO支持32位地址但x86处理器只使用16位。
配置地址空间是不能由CPU直接访问的,它控制软件可见度,地址和资源,提供即插即用功能,每个PCI功能function可以有最多256 bytes的配置地址,因此配置地址空间的大小为256 (bytes/function) * 8 (functions/device) * 32 (devices/bus) * 256 (buses/system) = 16MB
由于x86处理器不能直接访问配置地址空间,它要通过IO寄存器来间接访问,就是图中的Data Port和Address Port
PCI配置周期
过去的PCI模型中IO配置非常保守,用一个寄存器作为访问地址,另一个寄存器传输读取的数据。
第一步,CPU生成要访问的地址,在北桥地址CF8h开始放入此地址,确定要访问的是256个总线中的哪一个,32个设备中的哪一个,以及8个功能中的哪一个,最后是那个功能对应的256 bytes配置空间中的位置。具体如下图

第二步,CPU生成IO读或者写的数据放入地址CFCh开始,之后北桥就会开启配置读写流程
PCI功能配置寄存器
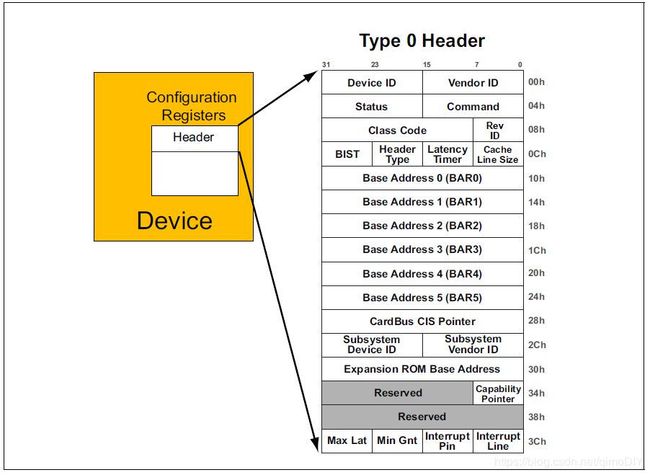
每个PCI功能都有256 bytes的配置寄存器空间。头64个byte是header,剩下的192个byte作为可选功能。PCI功能有两种header,一种表示自己是桥接,用来拓展总线,另一种表示自己是一般设备。这两种header分别在下图表示

更高带宽的PCI
介绍到目前为止的PCI都是33Mhz的基础模型,为了达到更高的带宽,PCI规范更新了64位66Mhz版本,可使速度提高到533Mb/s

在把总线吞吐量提高到原来两倍的时候,也表现出这种结构的缺陷:反射信号模型决定了当频率提高的时候,总线能搭载的设备数量大大减少。
把总线速度提高到66Mhz的结果就是,一条总线能搭载的设备被减少到一个,如此反而显得得不偿失。另外64位的PCI总线也会降低系统的可靠性。因此可以看出为什么64位或者66Mhz PCI不是那么受欢迎。
总结
本文介绍了PCI的基础结构,从中可以看出最开始的PCI还是有不少缺陷的,也因此早期的系统容易蓝屏。下次开始介绍在PCI的基础上的改进PCI-X