百度飞桨《青春有你2》Python小白逆袭大神技术分享
概述
7天的打卡训练营,时间紧张而又内容饱满,第一天主要针对小白们进行python基础知识的讲解,主要学习python的基础语法及各类常见用法;第二天讲解了爬虫的相关概念和基础知识;第三天重点讲解了python的数据分析与处理库;第四天讲解了paddleHub的用法及相关内容;第五天主要是EasyDL的讲解;第六及七天主要是作业及课程答疑时间。
第一天 pyton基础
个人觉得还是要掌握python的基础知识,注重个人的编码风格和编码习惯,python是一种对格式要求相对比较严格的语言,所以,格式的掌握很重要,有助于养成良好的编码习惯。另外就是对各类数据类型的使用,切片分割技巧的掌握和了解,能在很大程度上帮你更好的进行数据的分析与处理。作业也相对比较简单,主要是循环的使用和OS库的使用。牢记切片原则:左闭右开
def table():
#在这里写下您的乘法口诀表代码吧!
for i in range(1,10):
for j in range(1,i+1): #编写双层循环
print('{}*{}={}'.format(j,i,j*i),end='\t') #进行计算,样式输出
print()
if __name__ == '__main__':
table()
1*1=1
1*2=2 2*2=4
1*3=3 2*3=6 3*3=9
1*4=4 2*4=8 3*4=12 4*4=16
1*5=5 2*5=10 3*5=15 4*5=20 5*5=25
1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36
1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49
1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64
1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
第二天 《选手数据爬取》
主要学习和掌握requests模块、BeautifulSoup库。爬虫的主要原理就是通过模拟浏览器向目标站点发送相关请求,从而获取到目标站点的响应数据, 对数据进行加工处理后本地存储。本人一直觉得这块一定得遵守爬虫协议,严守法律底线。另外 就是感兴趣的话 还可以自学下Xpath等库,还有为了避免IP被封锁,可以使用动态IP代理。数据的爬取相对来说比较简单,重点主要在于对爬取后的响应数据的相关处理,为了方便起见,可以学习和了解下re等模块,有助于数据快速简单有效处理。
requests是python实现的简单易用的HTTP库,官网地址:http://cn.python-requests.org/zh_CN/latest/
网页请求的过程分为两个环节:requests(请求)、response(相应)。
网页请求的方式也分为两种:
(1)GET:最常见的方式,一般用于获取或者查询资源信息,也是大多数网站使用的方式,响应速度快。
(2)POST:相比 GET 方式,多了以表单形式上传参数的功能,因此除查询信息外,还可以修改信息。
requests.get(url)发送http get请求,返回内容response为URL对象,表示整个网页。
Beautiful Soup 是解析HTML和XML的工具,并提取的数据。包含html.parser、lxml等多种解析器,注意find_all()用于搜索当前节点下所有的符合条件的节点,没有指点节点则是全文;find()返回查询到的第一个元素节点,与find_all()略有不同
作业是对https://baike.baidu.com/item/青春有你第二季 中各个选手照片的批量爬取:
伪装浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
初步数据解析
try:
response = requests.get(url,headers=headers)
print(response.status_code)
#将一段文档传入BeautifulSoup的构造方法,就能得到一个文档的对象, 可以传入一段字符串
soup = BeautifulSoup(response.text,'lxml')
#返回的是class为table-view log-set-param的所有标签
tables = soup.find_all('table',{'class':'table-view log-set-param'})
crawl_table_title = "参赛学员"
for table in tables:
#对当前节点前面的标签和字符串进行查找
table_titles = table.find_previous('div').find_all('h3')
for title in table_titles:
if(crawl_table_title in title):
return table
except Exception as e:
print(e)
数据本地化存储
def down_pic(name,pic_urls):
'''
根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中,
'''
path = 'work/'+'pics/'+name+'/'
if not os.path.exists(path):
os.makedirs(path)
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = str(i + 1) + '.jpg'
with open(path+string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
第三天 《青春有你2》选手数据分析
重点在于学习和掌握Numpy、pandas、Matplotlib、PIL等的使用,当然在图像图形绘制方面还有其他的相关库,Echarts 很多人都在用,它是一个由百度开源的数据可视化工具,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可,当时当python遇到了Echarts,它就变身为pyechartsl了,在这里个人强烈推荐使用百度的pyecharts,文档功能齐全,示例清晰明了,图表内容丰富,颜色舒心悦目,最最主要的是使用方便,可以很方便的渲染到浏览器页面,再次进行强烈推荐。通过下面对比就知道了
先看用 Matplotlib 画的 K 线图,密密麻麻啥都看不清楚,根本区分不了开盘价、最高价、最低价、收盘价。

再看用 PyEcharts 画的 K 线图 (gif),也是密密麻麻的,但是我们可以通过鼠标拖动图片下方可伸缩的时间轴从而锁定我们想看到的数据,比如那根大蓝柱…
除了操作滑动轴以外,上图 还可以任意显示或隐藏 K 线 (K-Line), 最高价 (high) 和最低价 (low)这种交互式 (interactive) 操作在我看来给图标增加了额外的维度,再反观 Matplotlib 绘制出来的 K 线图 (包含长时间历史数据图) 就像死水一潭,真正是没有对比就没有伤害。。。谁用谁知道
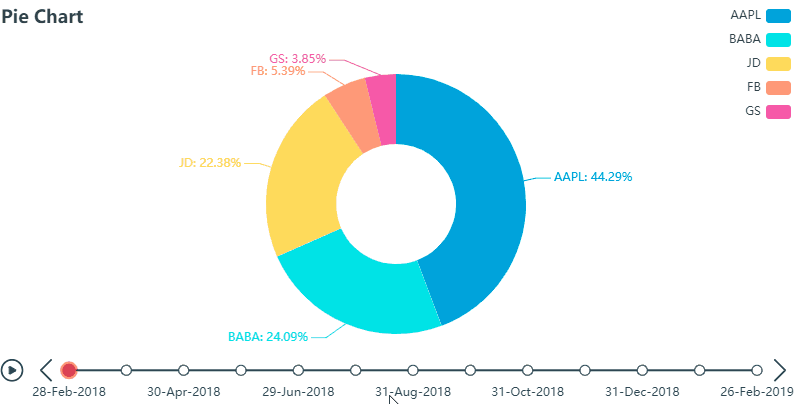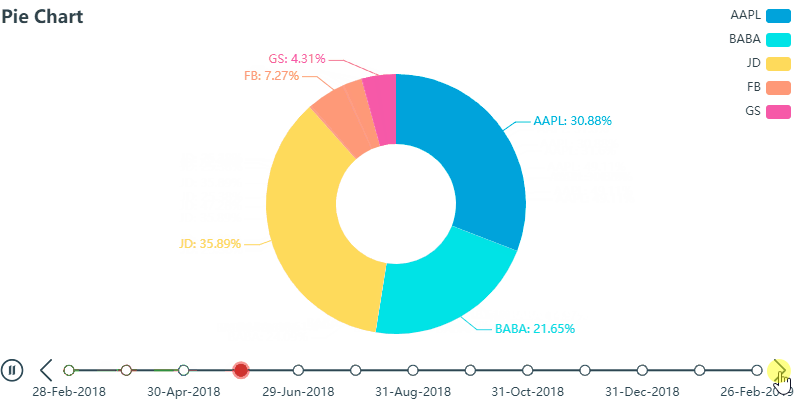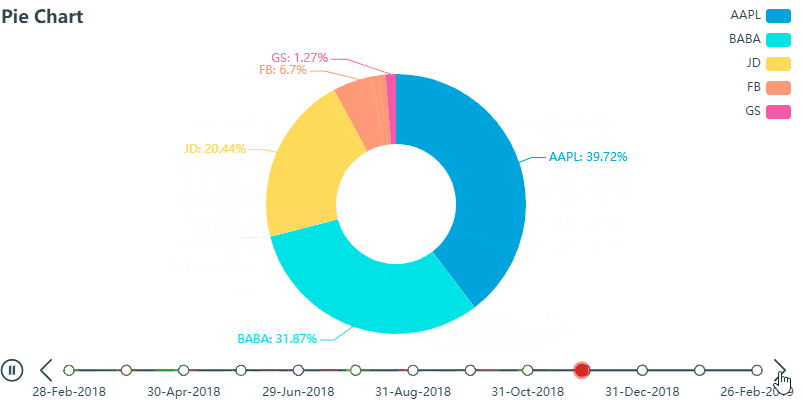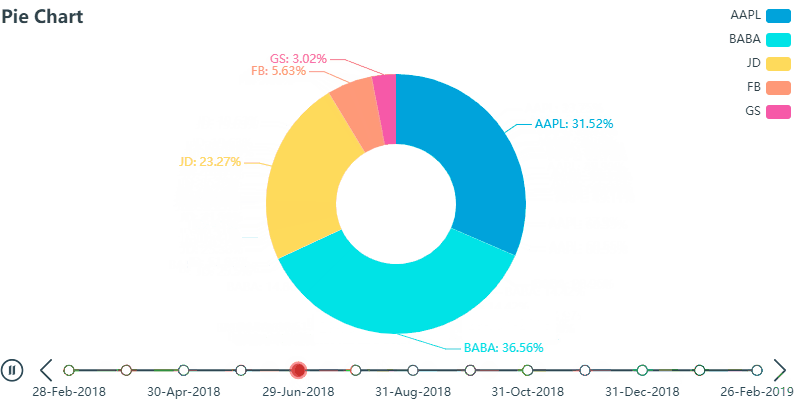
再说说作业吧,个人觉得主要利用pandas处理好数据的阶段区间分组就完全OK啦,当然不用pandas的话,还有其他的方法,比如直接统计每段区间的个数或者分段用数组存储,再统计每个数据中的数据库等等,这里看每个人喜好了
利用pandas的cut方法
bins =[0,45,50,55,1000]
labels = ['<45kg','45~50kg','50~55kg','>55kg']
counts = pd.cut(weight,bins,labels=labels,right=False)
s = counts.value_counts()
zl = s.index
sizes = s.values
再使用Matplotlib 绘图的时候,特别需要注意中文的处理,要不就会出现乱码
# 下载中文字体
!wget https://mydueros.cdn.bcebos.com/font/simhei.ttf
# 将字体文件复制到matplotlib字体路径
!cp simhei.ttf /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/
# 一般只需要将字体文件复制到系统字体目录下即可,但是在aistudio上该路径没有写权限,所以此方法不能用
# !cp simhei.ttf /usr/share/fonts/
# 创建系统字体文件路径
!mkdir .fonts
# 复制文件到该路径
!cp simhei.ttf .fonts/
!rm -rf .cache/matplotlib
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.figure(figsize=(20,15))
第四天 《青春有你2》选手识别
主要是对paddleHub的学习,了解和使用。PaddleHub是一个深度学习模型开发工具。它基于飞桨领先的核心框架,精选效果优秀的算法,提供了百亿级大数据训练的预训练模型,方便用户不用花费大量精力从头开始训练一个模型。PaddleHub可以便捷地获取这些预训练模型,完成模型的管理和一键预测。配合使用Fine-tune API,可以基于大规模预训练模型快速完成迁移学习,让预训练模型能更好地服务于用户特定场景的应用。
作业重点在于对训练图片数据集的自己爬取与处理,还有对训练集、验证集、测试集等的数据的处理:特别主要老师所讲的8:1:1原则(哈哈,老师讲课,我可是好好做笔记的)!
另外就是对模型的配置的设置以及Fine-tune 的相关使用:
自己准备整理训练数据集进行解压:!unzip -o file.zip -d ./dataset/dataset
CPU环境请执行,GPU直接忽略,建议能用GPU就用GPU,实在没有了 再用CPU
#CPU环境启动请务必执行该指令
%set_env CPU_NUM=1
module = hub.Module(name="resnet_v2_50_imagenet")
rom paddlehub.dataset.base_cv_dataset import BaseCVDataset
class DemoDataset(BaseCVDataset):
def __init__(self):
# 数据集存放位置
self.dataset_dir = "dataset"
super(DemoDataset, self).__init__(
base_path=self.dataset_dir,
train_list_file="train_list.txt",
validate_list_file="validate_list.txt",
test_list_file="test_list.txt",
label_list_file="label_list.txt",
)
dataset = DemoDataset()
run_states = task.finetune_and_eval()
第五天 综合大作业
课程内容主要学习EasyDL,EasyDL是基于百度自主研发的深度学习平台飞桨结合业界先进的工程服务技术打造的简单易用的模型训练和服务平台,EasyDL提供了从数据上传、标注、部署、迭代覆盖、AI开发一站式服务流程,让你可以很好的像使用word一样进行深度学习的研究与使用。跟普通的深度学习训练过程比起来, EasyDL 定制化图像识别有如下这些优势:① 需要的数据量更少。② 拥有全程可视化的操作界面。③ 能在分钟级的时间内完成训练。④ 目前大部分模型的准确率在90%以上。




具体的相关学习,请参考官网。
哈哈,再来说说作业的内容吧:这是好多人都最最关心的,这真是一个大综合,所有学习过的相关技术都得用到,requests,json,re,time ,jieba,wordcloud,numpy ,matplotlib,PIL ,paddlehub 等等等等:
爱奇艺《青春有你2》评论数据爬取,注意老师讲的那个抓包及lastID的分析和处理
第一个拦路虎:字体下载相关问题,报403错误,可以自己手动下载相关字体,然后进行上传
#!wget https://mydueros.cdn.bcebos.com/font/simhei.ttf # 下载中文字体
# #创建字体目录fonts
!mkdir .fonts
# # 复制字体文件到该路径
!cp simhei.ttf .fonts/
第二虎:lastId的获取
def saveMovieInfoToFile(lastId,arr):
'''
解析json数据,获取评论
参数 lastId:最后一条评论ID arr:存放文本的list
:return: 新的lastId
'''
url ="https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&business_type=17&content_id=15068699100&page=&page_size=10&types=time&last_id="
url += str(lastId)
responesTxt = getMovieinfo(url)
responesJson = json.loads(responesTxt)
comments = responesJson['data']['comments']
for val in comments:
if 'content' in val.keys():
print(val['content'])
arr.append(val['content'])
lastId = str(val['id'])
return lastId
第三虎:特殊字符过滤
s = re.sub(r"| |\t|\r","",content)
s = re.sub(r"\n","",s)
s = re.sub(r"\*","\\*",s)
s = re.sub("[^\u4e00-\u9fa5^a-z^A-Z^0-9]","",s)
s = re.sub("[\001\002\003\004\005\006\007\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a]+","", s)
s = re.sub("[a-zA-Z]","",s)
s = re.sub("^d+(\.\d+)?$","",s)
第四虎:matplotlib中文显示
#设置显示中文
matplotlib.rcParams['font.sans-serif']=['simhei']
matplotlib.rcParams['axes.unicode_minus']=False
第五虎:词云背景设置
cloud_mask = np.array(Image.open('333.jpg'))
#忽略显示的词
st = set(["这是","东西"])
第六虎:情感分析预测
porn_detection_lstm = hub.Module(name="porn_detection_lstm")
f = open('aqy.txt','r',encoding='UTF-8')
for line in f:
if len(line.strip()) == 1: #判断评论长度是否为1
continue
else:
test_text.append(line)
f.close()
成功闯关这六关,你的作业应该就没有太大问题了、
总结
七天的学习,充实而又紧张,感谢班班及助教还有讲师们陪着共同度过这段美好的时光,同样也感谢群里的各位学友们的相互关照与共同指导,感谢百度提供的这个宝贵的学习平台和机会,祝愿你们越来越好!哈哈 下期营地我们再会。
你可能感兴趣的:(百度飞桨,自然语言处理,深度学习,机器学习)