几种并行计算模型的区别(BSP LogP PRAM)
并行计算模型通常指从并行算法的设计和分析出发,将各种并行计算机(至少某一类并行计算机)的基本特征抽象出来,形成一个抽象的计算模型。
PRAM模型
BSP模型是一种异步MIMD-DM模型(DM: distributed memory,SM: shared memory),BSP模型支持消息传递系统,块内异步并行,块间显式同步,该模型基于一个master协调,所有的worker同步(lock-step)执行, 数据从输入的队列中读取,该模型的架构如图所示:
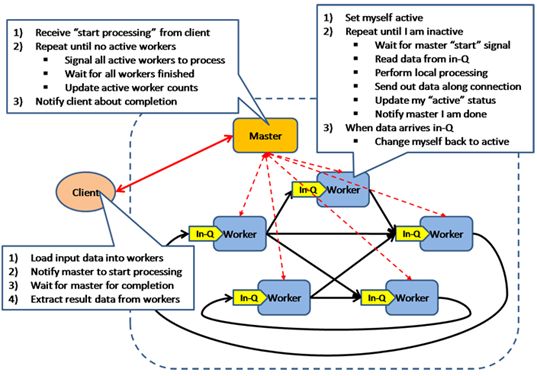
另外,BSP并行计算模型可以用 p/s/g/I 4个参数进行描述:
P为处理器的数目(带有存储器)。
s为处理器的计算速度。
g为每秒本地计算操作的数目/通信网络每秒传送的字节数,称之为选路器吞吐率,视为带宽因子 (time steps/packet)=1/bandwidth。
i为全局的同步时间开销,称之为全局同步之间的时间间隔 (Barrier synchronization time)。
那么假设有p台处理器同时传送h个字节信息,则gh就是通信的开销。同步和通信的开销都规格化为处理器的指定条数。
BSP计算模型不仅是一种体系结构模型,也是设计并行程序的一种方法。BSP程序设计准则是整体同步(bulk synchrony),其独特之处在于超步(superstep)概念的引入。一个BSP程序同时具有水平和垂直两个方面的结构。从垂直上看,一个BSP程序由一系列串行的超步(superstep)组成,如图所示:
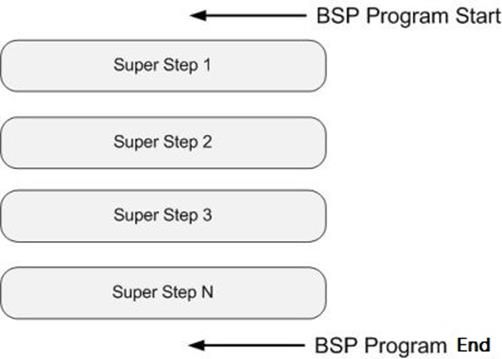
这种结构类似于一个串行程序结构。从水平上看,在一个超步中,所有的进程并行执行局部计算。一个超步可分为三个阶段,如图所示:
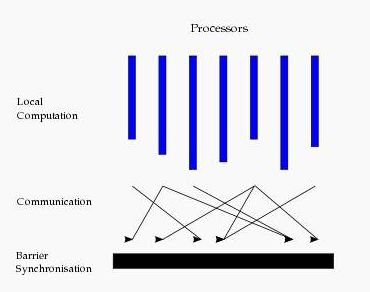
本地计算阶段,每个处理器只对存储本地内存中的数据进行本地计算。
全局通信阶段,对任何非本地数据进行操作。
栅栏同步阶段,等待所有通信行为的结束。
BSP模型特点
1. BSP模型将计算划分为一个一个的超步(superstep),有效避免死锁。
2. 它将处理器和路由器分开,强调了计算任务和通信任务的分开,而路由器仅仅完成点到点的消息传递,不提供组合、复制和广播等功能,这样做既掩盖具体的互连网络拓扑,又简化了通信协议;
3. 采用障碍同步的方式以硬件实现的全局同步是在可控的粗粒度级,从而提供了执行紧耦合同步式并行算法的有效方式,而程序员并无过分的负担;
4. 在分析BSP模型的性能时,假定局部操作可以在一个时间步内完成,而在每一个超级步中,一个处理器至多发送或接收h条消息(称为h-relation)。假定s是传输建立时间,所以传送h条消息的时间为gh+s,如果 ,则L至少应该大于等于gh。很清楚,硬件可以将L设置尽量小(例如使用流水线或大的通信带宽使g尽量小),而软件可以设置L的上限(因为L越大,并行粒度越大)。在实际使用中,g可以定义为每秒处理器所能完成的局部计算数目与每秒路由器所能传输的数据量之比。如果能够合适的平衡计算和通信,则BSP模型在可编程性方面具有主要的优点,而直接在BSP模型上执行算法(不是自动的编译它们),这个优点将随着g的增加而更加明显;
5. 为PRAM模型所设计的算法,都可以采用在每个BSP处理器上模拟一些PRAM处理器的方法来实现。
BSP模型的评价
1. 在并行计算时,Valiant试图也为软件和硬件之间架起一座类似于冯·诺伊曼机的桥梁,它论证了BSP模型可以起到这样的作用,正是因为如此,BSP模型也常叫做桥模型。
2. 一般而言,分布存储的MIMD模型的可编程性比较差,但在BSP模型中,如果计算和通信可以合适的平衡(例如g=1),则它在可编程方面呈现出主要的优点。
3. 在BSP模型上,曾直接实现了一些重要的算法(如矩阵乘、并行前序运算、FFT和排序等),他们均避免了自动存储管理的额外开销。
4. BSP模型可以有效的在超立方体网络和光交叉开关互连技术上实现,显示出,该模型与特定的技术实现无关,只要路由器有一定的通信吞吐率。
5. 在BSP模型中,超级步的长度必须能够充分的适应任意的h-relation,这一点是人们最不喜欢的。
6. 在BSP模型中,在超级步开始发送的消息,即使网络延迟时间比超级步的长度短,该消息也只能在下一个超级步才能被使用。
7. BSP模型中的全局障碍同步假定是用特殊的硬件支持的,但很多并行机中可能没有相应的硬件。
BSP与MapReduce对比
执行机制:MapReduce是一个数据流模型,每个任务只是对输入数据进行处理,产生的输出数据作为另一个任务的输入数据,并行任务之间独立地进行,串行任务之间以磁盘和数据复制作为交换介质和接口。
BSP是一个状态模型,各个子任务在本地的子图数据上进行计算、通信、修改图的状态等操作,并行任务之间通过消息通信交流中间计算结果,不需要像MapReduce那样对全体数据进行复制。
迭代处理:MapReduce模型理论上需要连续启动若干作业才可以完成图的迭代处理,相邻作业之间通过分布式文件系统交换全部数据。BSP模型仅启动一个作业,利用多个超步就可以完成迭代处理,两次迭代之间通过消息传递中间计算结果。由于减少了作业启动、调度开销和磁盘存取开销,BSP模型的迭代执行效率较高。
数据分割:基于BSP的图处理模型,需要对加载后的图数据进行一次再分布的过程,以确定消息通信时的路由地址。例如,各任务并行加载数据过程中,根据一定的映射策略,将读入的数据重新分发到对应的计算任务上(通常是放在内存中),既有磁盘I/O又有网络通信,开销很大。但是一个BSP作业仅需一次数据分割,在之后的迭代计算过程中除了消息通信之外,不再需要进行数据的迁移。而基于MapReduce的图处理模型,一般情况下,不需要专门的数据分割处理。但是Map阶段和Reduce阶段存在中间结果的Shuffle过程,增加了磁盘I/O和网络通信开销。
MapReduce的设计初衷:解决大规模、非实时数据处理问题。"大规模"决定数据有局部性特性可利用(从而可以划分)、可以批处理;"非实时"代表响应时间可以较长,有充分的时间执行程序。而BSP模型在实时处理有优异的表现。这是两者最大的一个区别。
BSP模型的实现
1.Pregel
Google的大规模图计算框架,首次提出了将BSP模型应用于图计算,具体请看Pregel——大规模图处理系统,不过至今未开源。
http://blog.csdn.net/strongwangjiawei/article/details/8120318
2.Apache Giraph
ASF社区的Incubator项目,由Yahoo!贡献,是BSP的java实现,专注于迭代图计算(如pagerank,最短连接等),每一个job就是一个没有reducer过程的hadoop job。http://giraph.apache.org/
3.Apache Hama
也是ASF社区的Incubator项目,与Giraph不同的是它是一个纯粹的BSP模型的java实现,并且不单单是用于图计算,意在提供一个通用的BSP模型的应用框架。http://hama.apache.org/
4.GraphLab
CMU的一个迭代图计算框架,C++实现的一个BSP模型应用框架,不过对BSP模型做了一定的修改,比如每一个超步之后并不设置全局同步点,计算可以完全异步进行,加快了任务的完成时间。http://graphlab.org/
5.Spark
加州大学伯克利分校实现的一个专注于迭代计算的应用框架,用Scala语言写就,提出了RDD(弹性分布式数据集)的概念,每一步的计算数据都从上一步结果精简而来,大大降低了网络传输,同时保证了血统的纯正性(即出错只需返回上一步即可),增强了容错功能。Spark论文里也基于此框架实现了BSP模型(叫Bagel)。值得一提的是国内的豆瓣也基于该思想用Python实现了这样一个框架叫Dpark,并且已经开源。https://github.com/douban/dpark
6.Trinity
这是微软的一个图计算平台,C#开发的,它是为了提供一个专用的图计算应用平台,包括底层的存储到上层的应用,应该是可以实现BSP模型的,文章发在SIGMOD13上,可恨的是也不开源。
主页http://research.microsoft.com/en-us/projects/trinity/
以下几个也是一些BSP的实现,不过关注度不是很高,基本都是对Pregel的开源实现:
7.GoldenOrb
另一个BSP模型的java实现,是对Pregel的一个开源实现,应用在hadoop上。
官网:http://www.goldenorbos.org/(要FQ)
源码:https://github.com/jzachr/goldenorb
8.Phoebus
Erlang语言实现的BSP模型,也是对Pregel的一个开源实现。
https://github.com/xslogic/phoebus
9.Rubicon
Pregel的开源实现。https://launchpad.net/rubicon
10.Signal/Collect
也是一个Scala版的BSP模型实现。http://code.google.com/p/signal-collect/
11.PEGASUS
在hadoop上实现的一个java版的BSP模型,发表在SIGKDD2011上。
http://www.cs.cmu.edu/~pegasus/index.htm
LogP模型