深入 Nodejs 源码探究 CPU 信息的获取与利用率计算
 在 Linux 下我们通过 top 或者 htop 命令可以看到当前的 CPU 资源利用率,另外在一些监控工具中你可能也遇见过,那么它是如何计算的呢?在 Nodejs 中我们该如何实现?
在 Linux 下我们通过 top 或者 htop 命令可以看到当前的 CPU 资源利用率,另外在一些监控工具中你可能也遇见过,那么它是如何计算的呢?在 Nodejs 中我们该如何实现?
带着这些疑问,本节会先从 Linux 下的 CPU 利用率进行一个简单讲解做一下前置知识铺垫,之后会深入 Nodejs 源码,去探讨如何获取 CPU 信息及计算 CPU 某时间段的利用率。
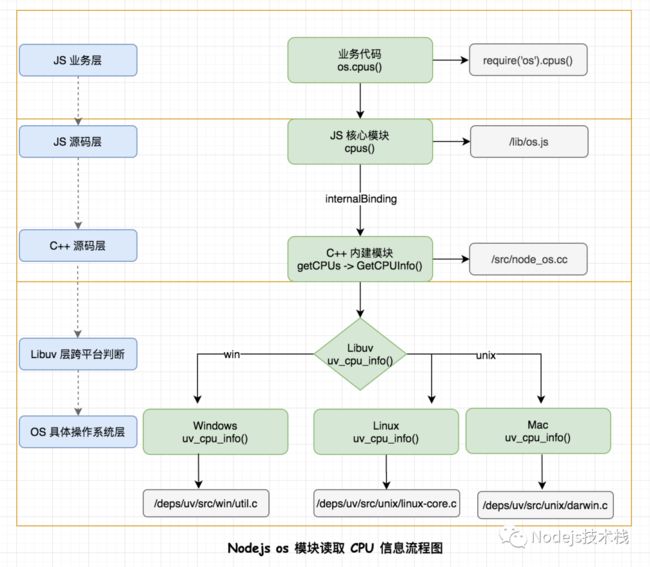
开始之前,可以先看一张图,它展示了 Nodejs OS 模块读取系统 CPU 信息的整个过程调用,在下文中也会详细讲解,你会再次看到它。
Linux 下 CPU 利用率
Linux 下 CPU 的利用率分为用户态(用户模式下执行时间)、系统态(系统内核执行)、空闲态(空闲系统进程执行时间),三者相加为 CPU 执行总时间,关于 CPU 的活动信息我们可以在 /proc/stat 文件查看。
CPU 利用率是指非系统空闲进程 / CPU 总执行时间。
> cat /proc/stat
cpu 2255 34 2290 22625563 6290 127 456
cpu0 1132 34 1441 11311718 3675 127 438
cpu1 1123 0 849 11313845 2614 0 18
intr 114930548 113199788 3 0 5 263 0 4 [... lots more numbers ...]
ctxt 1990473 # 自系统启动以来 CPU 发生的上下文交换次数
btime 1062191376 # 启动到现在为止的时间,单位为秒
processes 2915 # 系统启动以来所创建的任务数目
procs_running 1 # 当前运行队列的任务数目
procs_blocked 0 # 当前被阻塞的任务数目
上面第一行 cpu 表示总的 CPU 使用情况,下面的cpu0、cpu1 是指系统的每个 CPU 核心数运行情况(cpu0 + cpu1 + cpuN = cpu 总的核心数),我们看下第一行的含义。
user:系统启动开始累计到当前时刻,用户态的 CPU 时间(单位:jiffies),不包含 nice 值为负的进程。
nice:系统启动开始累计到当前时刻,nice 值为负的进程所占用的 CPU 时间。
system:系统启动开始累计到当前时刻,核心时间
idle:从系统启动开始累计到当前时刻,除硬盘IO等待时间以外其它等待时间
iowait:从系统启动开始累计到当前时刻,硬盘IO等待时间
irq:从系统启动开始累计到当前时刻,硬中断时间
softirq:从系统启动开始累计到当前时刻,软中断时间
关于 /proc/stat 的介绍,参考这里 http://www.linuxhowtos.org/System/procstat.htm
CPU 某时间段利用率公式
/proc/stat 文件下展示的是系统从启动到当下所累加的总的 CPU 时间,如果要计算 CPU 在某个时间段的利用率,则需要取 t1、t2 两个时间点进行运算。
t1~t2 时间段的 CPU 执行时间:
t1 = (user1 + nice1 + system1 + idle1 + iowait1 + irq1 + softirq1)
t2 = (user2 + nice2 + system2 + idle2 + iowait2 + irq2 + softirq2)
t = t2 - t1
t1~t2 时间段的 CPU 空闲使用时间:
idle = (idle2 - idle1)
t1~t2 时间段的 CPU 空闲率:
idleRate = idle / t;
t1~t2 时间段的 CPU 利用率:
usageRate = 1 - idleRate;
上面我们对 Linux 下 CPU 利用率做一个简单的了解,计算某时间段的 CPU 利用率公式可以先理解下,在下文最后会使用 Nodejs 进行实践。
这块可以扩展下,感兴趣的可以尝试下使用 shell 脚本实现 CPU 利用率的计算。
在 Nodejs 中是如何获取 cpu 信息的?
Nodejs os 模块 cpus() 方法返回一个对象数组,包含每个逻辑 CPU 内核信息。
提个疑问,这些数据具体是怎么获取的?和上面 Linuv 下的 /proc/stat 有关联吗?带着这些疑问只能从源码中一探究竟。
const os = require('os');
os.cpus();
1. JS 层
lib 模块是 Node.js 对外暴露的 js 层模块代码,找到 os.js 文件,以下只保留 cpus 相关核心代码,其中 getCPUs 是通过 internalBinding('os') 导入。
internalBinding 就是链接 JS 层与 C++ 层的桥梁。
// https://github.com/Q-Angelo/node/blob/master/lib/os.js#L41
const {
getCPUs,
getFreeMem,
getLoadAvg,
...
} = internalBinding('os');
// https://github.com/Q-Angelo/node/blob/master/lib/os.js#L92
function cpus() {
// [] is a bugfix for a regression introduced in 51cea61
const data = getCPUs() || [];
const result = [];
let i = 0;
while (i < data.length) {
result.push({
model: data[i++],
speed: data[i++],
times: {
user: data[i++],
nice: data[i++],
sys: data[i++],
idle: data[i++],
irq: data[i++]
}
});
}
return result;
}
// https://github.com/Q-Angelo/node/blob/master/lib/os.js#L266
module.exports = {
cpus,
...
};
2. C++ 层
2.1 Initialize:
C++ 层代码位于 src 目录下,这一块属于内建模块,是给 JS 层(lib 目录下)提供的 API,在 src/node_os.cc 文件中有一个 Initialize 初始化操作,getCPUs 对应的则是 GetCPUInfo 方法,接下来我们就要看这个方法的实现。
// https://github.com/Q-Angelo/node/blob/master/src/node_os.cc#L390
void Initialize(Local2.2 GetCPUInfo 实现:
核心是在 uv_cpu_info 方法通过指针的形式传入 &cpu_infos、&count 两个参数拿到 cpu 的信息和个数 count
for 循环遍历每个 CPU 核心数据,赋值给变量 ci,遍历过程中 user、nice、sys... 这些数据就很熟悉了,正是我们在 Nodejs 中通过 os.cpus() 拿到的,这些数据都会保存在 result 对象中
遍历结束,通过 uv_free_cpu_info 对 cpu_infos、count 进行回收
最后,设置参数 Array::New(isolate, result.data(), result.size()) 以数组形式返回。
// https://github.com/Q-Angelo/node/blob/master/src/node_os.cc#L113
static void GetCPUInfo(const FunctionCallbackInfo& args) {
Environment* env = Environment::GetCurrent(args);
Isolate* isolate = env->isolate();
uv_cpu_info_t* cpu_infos;
int count;
int err = uv_cpu_info(&cpu_infos, &count);
if (err)
return;
// It's faster to create an array packed with all the data and
// assemble them into objects in JS than to call Object::Set() repeatedly
// The array is in the format
// [model, speed, (5 entries of cpu_times), model2, speed2, ...]
std::vector> result(count * 7);
for (int i = 0, j = 0; i < count; i++) {
uv_cpu_info_t* ci = cpu_infos + i;
result[j++] = OneByteString(isolate, ci->model);
result[j++] = Number::New(isolate, ci->speed);
result[j++] = Number::New(isolate, ci->cpu_times.user);
result[j++] = Number::New(isolate, ci->cpu_times.nice);
result[j++] = Number::New(isolate, ci->cpu_times.sys);
result[j++] = Number::New(isolate, ci->cpu_times.idle);
result[j++] = Number::New(isolate, ci->cpu_times.irq);
}
uv_free_cpu_info(cpu_infos, count);
args.GetReturnValue().Set(Array::New(isolate, result.data(), result.size()));
}
3. Libuv 层
经过上面 C++ 内建模块的分析,其中一个重要的方法 uv_cpu_info 是用来获取数据源,现在就要找它啦
3.1 node_os.cc:
内建模块 node_os.cc 引用了头文件 env-inl.h
// https://github.com/Q-Angelo/node/blob/master/src/node_os.cc#L22
#include "env-inl.h"
...
3.2 env-inl.h:
env-inl.h 处又引用了 uv.h
// https://github.com/Q-Angelo/node/blob/master/src/env-inl.h#L31
#include "uv.h"
3.3 uv.h:
.h(头文件)包含了类里面成员和方法的声明,它不包含具体的实现,声明找到了,下面找下它的具体实现。
除了我们要找的 uv_cpu_info,此处还声明了 uv_free_cpu_info 方法,与之对应主要用来做回收,上文 C++ 层在数据遍历结束就使用的这个方法对参数 cpu_infos、count 进行了回收。
/* https://github.com/Q-Angelo/node/blob/master/deps/uv/include/uv.h#L1190 */
UV_EXTERN int uv_cpu_info(uv_cpu_info_t** cpu_infos, int* count);
UV_EXTERN void uv_free_cpu_info(uv_cpu_info_t* cpu_infos, int count);
Libuv 层只是对下层操作系统的一种封装,下面来看操作系统层的实现。
4. OS 操作系统层
4.1 linux-core.c:
在 deps/uv/ 下搜索 uv_cpu_info,会发现它的实现有很多 aix、cygwin.c、darwin.c、freebsd.c、linux-core.c 等等各种系统的,按照名字也可以看出 linux-core.c 似乎就是 Linux 下的实现了,重点也来看下这个的实现。
uv__open_file("/proc/stat") 参数 /proc/stat 这个正是 Linux 下 CPU 信息的位置。
// https://github.com/Q-Angelo/node/blob/master/deps/uv/src/unix/linux-core.c#L610
int uv_cpu_info(uv_cpu_info_t** cpu_infos, int* count) {
unsigned int numcpus;
uv_cpu_info_t* ci;
int err;
FILE* statfile_fp;
*cpu_infos = NULL;
*count = 0;
statfile_fp = uv__open_file("/proc/stat");
...
}
4.2 core.c:
最终找到 uv__open_file() 方法的实现是在 /deps/uv/src/unix/core.c 文件,它以只读和执行后关闭模式获取一个文件的指针。
到这里也就该明白了,Linux 平台下我们使用 Nodejs os 模块的 cpus() 方法最终也是读取的 /proc/stat 文件获取的 CPU 信息。
// https://github.com/Q-Angelo/node/blob/master/deps/uv/src/unix/core.c#L455
/* get a file pointer to a file in read-only and close-on-exec mode */
FILE* uv__open_file(const char* path) {
int fd;
FILE* fp;
fd = uv__open_cloexec(path, O_RDONLY);
if (fd < 0)
return NULL;
fp = fdopen(fd, "r");
if (fp == NULL)
uv__close(fd);
return fp;
}
什么时候该定位到 win 目录下?什么时候定位到 unix 目录下?
这取决于 Libuv 层,在“深入浅出 Nodejs” 一书中有这样一段话:“Node 在编译期间会判断平台条件,选择性编译 unix 目录或是 win 目录下的源文件到目标程序中”,所以这块是在编译时而非运行时来确定的。
5. 一图胜千言
通过对 OS 模块读取 CPU 信息流程梳理,再次展现 Nodejs 的经典架构:
JavaScript -> internalBinding -> C++ -> Libuv -> OS
在 Nodejs 中实践
了解了上面的原理之后在来 Nodejs 中实现,已经再简单不过了,系统层为我们提供了完美的 API 调用。
os.cpus() 数据指标
Nodejs os.cpus() 返回的对象数组中有一个 times 字段,包含了 user、nice、sys、idle、irq 几个指标数据,分别代表 CPU 在用户模式、良好模式、系统模式、空闲模式、中断模式下花费的毫秒数。相比 linux 下,直接通过 cat /proc/stat 查看更直观了。
[
{
model: 'Intel(R) Core(TM) i7 CPU 860 @ 2.80GHz',
speed: 2926,
times: {
user: 252020,
nice: 0,
sys: 30340,
idle: 1070356870,
irq: 0
}
}
...
Nodejs 中编码实践
定义方法 _getCPUInfo 用来获取系统 CPU 信息。
方法 getCPUUsage 提供了 CPU 利用率的 “实时” 监控,这个 “实时” 不是绝对的实时,总会有时差的,我们下面实现中默认设置的 1 秒钟,可通过 Options.ms 进行调整。
const os = require('os');
const sleep = ms => new Promise(resolve => setTimeout(resolve, ms));
class OSUtils {
constructor() {
this.cpuUsageMSDefault = 1000; // CPU 利用率默认时间段
}
/**
* 获取某时间段 CPU 利用率
* @param { Number } Options.ms [时间段,默认是 1000ms,即 1 秒钟]
* @param { Boolean } Options.percentage [true(以百分比结果返回)|false]
* @returns { Promise }
*/
async getCPUUsage(options={}) {
const that = this;
let { cpuUsageMS, percentage } = options;
cpuUsageMS = cpuUsageMS || that.cpuUsageMSDefault;
const t1 = that._getCPUInfo(); // t1 时间点 CPU 信息
await sleep(cpuUsageMS);
const t2 = that._getCPUInfo(); // t2 时间点 CPU 信息
const idle = t2.idle - t1.idle;
const total = t2.total - t1.total;
let usage = 1 - idle / total;
if (percentage) usage = (usage * 100.0).toFixed(2) + "%";
return usage;
}
/**
* 获取 CPU 信息
* @returns { Object } CPU 信息
*/
_getCPUInfo() {
const cpus = os.cpus();
let user = 0, nice = 0, sys = 0, idle = 0, irq = 0, total = 0;
for (let cpu in cpus) {
const times = cpus[cpu].times;
user += times.user;
nice += times.nice;
sys += times.sys;
idle += times.idle;
irq += times.irq;
}
total += user + nice + sys + idle + irq;
return {
user,
sys,
idle,
total,
}
}
}
使用方式如下所示:
const cpuUsage = await osUtils.getCPUUsage({ percentage: true });
console.log('CPU 利用率:', cpuUsage) // CPU 利用率:13.72%
总结
本文先从 Linux 下 CPU 利用率的概念做一个简单的讲解,之后深入 Nodejs OS 模块源码对获取系统 CPU 信息进行了梳理,另一方面也再次呈现了 Nodejs 经典的架构 JavaScript -> internalBinding -> C++ -> Libuv -> OS 这对于梳理其它 API 是通用的,可以做为一定的参考,最后使用 Nodejs 对 CPU 利用率的计算进行了实践。
Reference
http://www.penglixun.com/tech/system/how_to_calc_load_cpu.html
https://blog.csdn.net/htjx99/article/details/42920641
http://www.linuxhowtos.org/System/procstat.htm
https://github.com/Q-Angelo/node/tree/master/deps/uv/src/unix
http://nodejs.cn/api/os.html
敬请关注「Nodejs技术栈」微信公众号,获取优质文章
▼
往期精彩回顾
▼
Node.js 如何利用 Libuv 实现事件循环和异步
Nodejs 进阶:解答 Cluster 模块的几个疑问
多维度分析 Express、Koa 之间的区别
你需要了解的有关 Node.js 的所有信息
Node.js 服务 Docker 容器化应用实践
一文零基础教你学会 Docker 入门到实践
JavaScript 浮点数之迷:大数危机
Node.js 是什么?我为什么选择它?
分享 10 道 Nodejs 进程相关面试题
不容错过的 Node.js 项目架构
Node.js 内存管理和 V8 垃圾回收机制
