Windows+Docker+Hadoop的部署完整教程(二)hadoop分布式系统部署
说明
本文搭建的时hadoop2.7.5分布式系统,一个master,二个slave
搭配jdk版本为jdk1.8
所有安装包都在博主的网盘上,自行保存
链接:https://pan.baidu.com/s/1TcKCEEcxpgtVWu26iwhaRw
提取码:naad
接上篇博客,基础环境安装好之后。
hadoop分布式环境搭建(终于进入正题啦!)
一、 hadoop安装
hadoop-2.7.5的安装包我们已经拷贝进来了,如果上节课忘记拷贝的同学也不要慌(有更好用的教程在这里)
docker run -it --name ubuntu-jdkinstalled ubuntu/jdkinstalled
然后解压安装包到/usr/local
cd /home
ls
tar -zxvf hadoop-2.7.5.tar.gz -C /usr/local
切换至安装目录
cd /usr/local
mv ./hadoop-2.7.5 ./hadoop
cd hadoop
./bin/hadoop version
运行结果如下代表安装成功

关键的步骤来了!!编辑配置文件以及环境变量
1、添加jdk路径(vim编辑文件如何插入和保存自行百度)
cd /usr/local/hadoop/etc/hadoop
vim hadoop-env.sh
在文件内插入如下内容(jdk的安装路径):
export JAVA_HOME=/usr/local/jdk1.8.0_251
2、编辑core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
3、编辑hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
</property>
</configuration>
4、mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:19888</value>
</property>
</configuration>
5、yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>Master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Master:8088</value>
</property>
</configuration>
6、编辑slaves文件
vim slaves
加入从机名
slave1
slave2
环境变量
vim ~/.bashrc
#set hadoop_home
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_ROOT_LOGGER=INFO,console
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
source ~/.bashrc
大功告成,提交容器,先退出容器。
用docker ps -a,找到刚才操作的容器
docker commit CONTAINER_ID ubuntu/hadoopinstalled
保存完成
二、使用X-shell连接docker
(安装x-shell是为了避免后边分布式部署的时候多开docker窗口,频繁的切换窗口等等,相当于一个管理工具,可以给我们一个更好的视觉效果。)
X-shell破解版在这里,链接:https://pan.baidu.com/s/1dBdMHKB-RLryokReTOfbxA
提取码:ghhn
(非常好用的工具)下载安装之后,使用X-shell连接docker
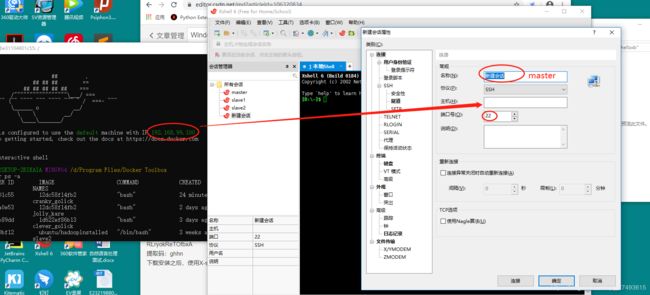
按上图配置好之后,点击连接
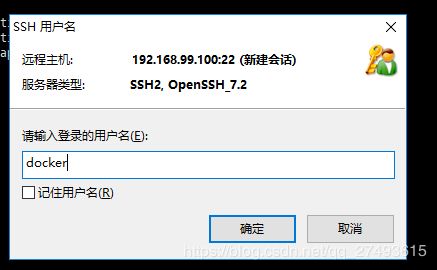
默认用户名为docker,密码为tcuser。
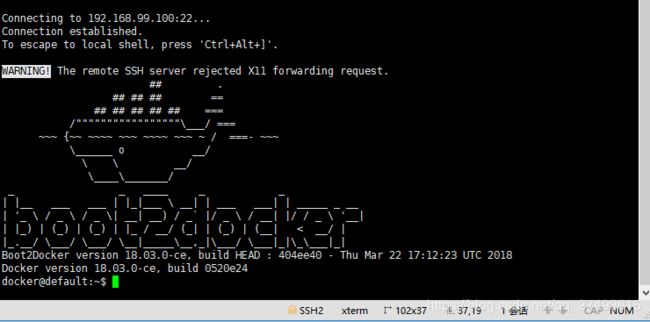
熟悉的大鲸鱼图标出现,成功连接!!!
在分别创建slave1和slave2,操作步骤一模一样,只需要把名称master修改为对应的slave1和slave2就行!
三、分布式部署
在X-shell的三个对应窗口分别:
# 在第一个终端中执行下面命令
docker run -it -h master --name master ubuntu/hadoopinstalled
# 在第二个终端中执行下面命令
docker run -it -h slave1 --name slave01 ubuntu/hadoopinstalled
# 在第三个终端中执行下面命令
docker run -it -h slave2 --name slave02 ubuntu/hadoopinstalled
启动容器之后,修改主机名映射vim /etc/hosts,
将三台机器的主机名及其ip地址全部添加到hosts文件中,保持一致,如下(三台机器同!!!)
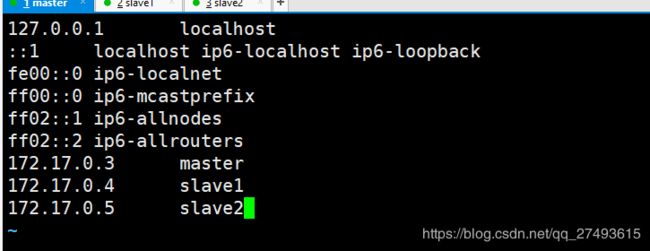
开始ssh服务(三台机器都要操作)
/etc/init.d/ssh start
用master分别远程slave1和slave2,看是否能成功。
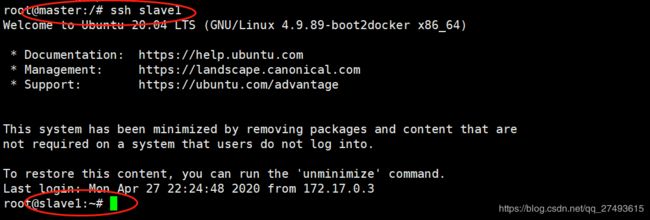
远程slave2

都是没有问题的,登出后就可以启动集群了!
启动之前格式化namenode节点:(首次启动格式化,以后都不需要,由于博主已经格式化过,所以这里借花献佛)
cd /usr/local/hadoop
bin/hdfs namenode -format

出现上图中的status 0标志着格式化成功!!!
启动
sbin/start-all.sh
启动后查看主机进程jps:
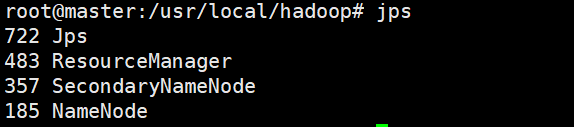
slave1或slave2进程:

搭建完成!!!