【哈工大SCIR】多模态情感分析简述
点击上方,选择星标或置顶,每天给你送干货 !
!
阅读大概需要19分钟
跟随小博主,每天进步一丢丢


来自:哈工大SCIR
作者:吴洋,胡晓毓,林子杰
介绍
随着社交网络的快速发展,人们在平台上的表达方式变得越来越丰富,如通过图文和视频表达自己的情绪和观点。如何分析多模态数据(本文指声音,图像和文字,不涉及传感器数据)中的情感,是当前情感分析领域面临的机遇和挑战。
一方面,以往情感分析聚焦于单个模态。如文本情感分析着眼于分析,挖掘和推理文本中蕴含的情感。现在需要对多个模态的数据进行处理和分析,这给研究人员带来了更大的挑战。另一方面,多模态数据与单模态数据相比,包含了更多的信息,多个模态之间可以互相补充。例如,在识别这条推文是否为反讽,“今天天气真好!”。如果只从文本来看,不是反讽。而如果其附加一张阴天的图片,可能就是反讽。不同模态信息相互补充,可以帮助机器更好地理解情感。从人机交互角度出发,多模态情感分析可以使得机器在更加自然的情况下与人进行交互。机器可以基于图像中人的表情和手势,声音中的音调,和识别出的自然语言来理解用户情感,进而进行反馈。
综上来讲,多模态情感分析技术的发展源于实际生活的需求,人们以更加自然的方式表达情感,技术就应有能力进行智能的理解和分析。虽然多模态数据包含了更多的信息,但如何进行多模态数据的融合,使得利用多模态数据能够提升效果,而不是起了反作用。如何利用不同模态数据之间的对齐信息,建模不同模态数据之间关联,如人们听见“喵”就会想起猫。这些都是当前多模态情感分析领域感兴趣的问题。为了能够更好的介绍多模态情感分析领域的相关研究,本文梳理了目前多模态情感分析领域相关任务并总结了常用的数据集及对应的方法。
相关任务概览
本文通过不同模态组合(图文:文本+图片,视频:文本+图片+音频)来梳理相关的研究任务,对于文本+音频这种组合方式少有特意构建的相关数据集,一般通过对语音进行ASR或者使用文本+图片+音频中的文本+音频来构造数据集。对于文本+音频,语音方向的研究工作较多,所以本文暂未涉及。如表1所示,面向图文的情感分析任务有面向图文的情感分类任务,面向图文的方面级情感分类任务和面向图文的反讽识别任务。面向视频的情感分析任务有面向评论视频的情感分类任务,面向新闻视频的情感分类任务,面向对话视频的情感分类任务和面向对话视频的反讽识别任务。本文总结了与任务对应的相关数据集及方法,具体内容见第三部分。
表1 多模态情感分析任务概览

数据集和方法
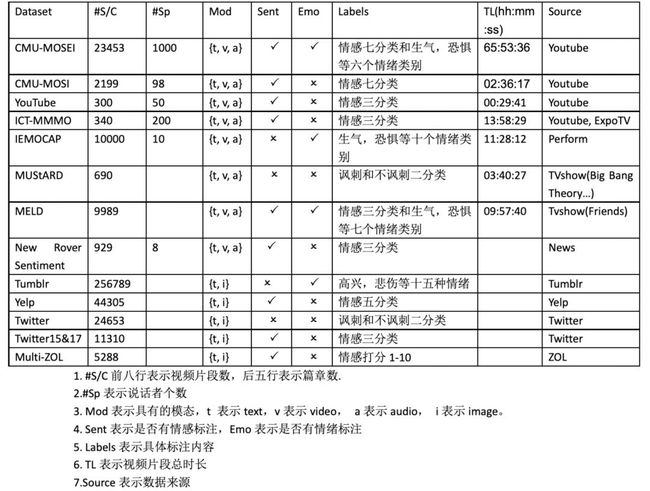
本文总结了13个公开数据集,其中包括8个视频数据集和5个图文数据集。本文还总结了与面向图文的情感分类任务,面向图文的方面级情感分类任务,面向图文的反讽识别任务,面向评论视频的情感分类任务和面向对话视频的情感分类任务五个任务对应的相关研究方法。
面向图文的情感分类任务
数据集
Yelp数据集来自Yelp.com评论网站,收集的是波士顿,芝加哥,洛杉矶,纽约,旧金山五个城市关于餐厅和食品的Yelp上的评论。一共有44305条评论,244569张图片(每条评论的图片有多张),平均每条评论有13个句子,230个单词。数据集的情感标注是对每条评论的情感倾向打1,2,3,4,5五个分值。
Tumblr数据集是从Tumblr收集来的多模态情绪数据集。Tumblr是一种微博客服务,用户在上面发布的多媒体内容通常包含:图片、文本和标签。数据集是根据选定的十五种情绪搜索对应的情绪标签的推文,并且只选择其中既有文本又有图片的部分,然后进行了数据处理,删除了那些文本中原本就包含对应情绪词的内容,以及那些主要不是英文为主的推文。整个数据集共有256897个多模态推文,其中情绪标注为包含高兴,悲伤,厌恶在内的十五种情绪。
方法
结合Yelp数据集的特点,[1]提出“图片并不独立于文字表达情感,而是作为辅助部分提示文本中的显著性内容”。VistaNet用图片指导文本进行attention,用来决定文档中不同句子对于文档情感分类的重要性程度。
如图1所示,VistaNet具有三层结构,分别是词编码层、句子编码层和分类层。词编码层对一个句子中的词语进行编码,再经过soft-attention得到句子的表示。句子编码层对上一层得到的句子表示进行编码,再通过视觉注意力机制(visual aspectattentino)得到文档表示。文档表示作为分类层的输入,输出分类结果。从结构上来看,VistaNet和Hierarchical Attention Network基本相似,都是用于文档级情感分类,都有三层结构,且前两层都是GRUEncoder+Attention的结构,二者的不同点在于VistaNet使用了视觉注意力机制。
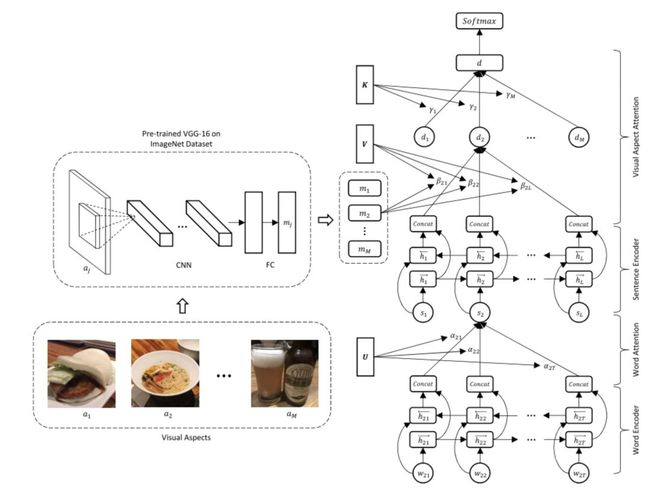
图1 VistaNet模型架构
面向图文的方面级情感分类任务
数据集
Multi-ZOL数据集收集整理了IT信息和商业门户网站ZOL.com上的关于手机的评论。原始数据有12587条评论(7359条单模态评论,5288条多模态评论),覆盖114个品牌和1318种手机。其中的5288多模态评论,构成了Multi-ZOL数据集。在这个数据集中,每条多模态数据包含一个文本内容、一个图像集,以及至少一个但不超过六个评价方面。这六个方面分别是性价比、性能配置、电池寿命、外观与感觉、拍摄效果、屏幕。总共得到28469个方面。对于每个方面,都有一个从1到10的情感得分。
Twitter-15和Twitter-17是包含文本和文本对应图片的多模态数据集,数据集标注了目标实体及对其图文中表达的情感倾向。整个的数据规模是Twitter-15(3179/1122/1037)条带图片推文,Twitter-17(3562/1176/1234)条带图片推文,情感标注为三分类。
方法
方面级情感分类任务是对给定一个方面(Aspect),研究多模态文档在该方面的情感极性。一个方面可能由多个词语组成,例如“Eatingenvironment”,方面本身包含的信息对于文本和图像信息的提取有重要的指导意义。对于Multi-ZOL数据集,[2]提出了Multi-Interactive MemoryNetwork(MIMN),如图2所示。模型使用Aspect-guided attention机制来指导模型生成文本和图像的Attention向量。为了捕获多模态间和单模态内的交互信息,模型使用了Multi-interactive attention机制。

图2 MIMN模型架构
面向图文的反讽识别任务
反讽识别任务的目的是判断一段文档是否含有反讽表达。[3]提出了多层融合模型(HierarchicalFusion Model)对图文信息进行建模,用于反讽识别。
数据集
Twitters反讽数据集构建自Twitter平台,其从Twitter上收集包含图片和一些特定话题标签(例如#sarcasm,等等)的英语推文,将其作为正例,并收集带有图片但没有此类标签的英语推文,作为反例。数据集还进行了进一步整理数据,将含有讽刺、讽刺、反讽、反讽等常规词汇的推文删除。也会删除含有URL的推文,以避免引入额外的信息。此外,还删除了那些经常与讽刺性的推文同时出现的词语,例如Jokes,Humor。数据集分为训练集、开发集和测试集,分别是19816,2410,2409条带图片推文。该数据集的标注为是讽刺/不是讽刺二分类。
方法
HFM(HierarchicalFusion Model)在文本和图像双模态的基础上,增加了图像的属性模态(Image attribute),由描述图像组成成分的若干词组成。如图3所示,图片包含了“Fork”、“Knife”、“Meat”等属性。作者认为图像属性能够将图像和文本的内容联系起来,具有“桥梁”的作用。
根据功能将HFM划分为三个层次,编码层、融合层和分类层,其中融合层又可分为表示融合层和模态融合层。HFM在编码层首先对三种模态的信息进行编码,得到每种模态的原始特征向量(Raw vectors),即每个模态的所有元素的向量表示集合。对原始特征向量进行平均或加权求和后得到每个模态的单一向量表示(Guidancevector)。原始特征向量和单一向量表示经过表示融合层后,得到融合了其他模态信息的每个模态的重组特征向量表示(Reconstructedfeature vector)。最后将三个模态的重组特征向量经过模态融合层处理,得到最后的融合向量(Fusedvector),作为分类层的输入。

图3 HFN模型架构
面向评论视频的情感分类任务
数据集
YouTube数据集收集整理了YouTube上的47个视频,收集的视频不是一个主题,而是牙膏,相机评论,婴儿用品等一系列多样化主题的视频。视频的形式是单个演讲者面对镜头讲述观点,总共包含20名女性,27名男性讲述者,年龄大约在14-60岁之间,来自不同的种族背景。视频的长度从2-5分钟不等,所有的视频序列都被规范化为30秒的长度。数据集的标注是由三位标注者以随机顺序观看视频进行标注,标注为积极,消极,中性三分类,需要注意的是标注的不是观看者对于视频的情感倾向,而是标注视频中讲述者的情感倾向,最后,47个视频中,有13个标注为积极,22个标注为中性,12个标注为消极。
ICT-MMMO数据集,收集的是社交媒体网站上关于电影评论的视频。数据集包含370个多模态评论视频,视频形式是一个人直接对着摄像机说话,表达他们的对于电影的评论或陈述与特定电影相关的事实。数据集来自于社交媒体网站YouTube和ExpoTV。所有的讲述者都用英语表达自己的观点,视频的长度从1-3分钟不等。总共有370个电影评论视频,其中有308个评论视频来自YouTube还有62个全是负面的评论视频来自ExpoTV,总体上包括228个正面评论、23个中立评论和119个负面评论。需要注意的是这个数据集标注的不是观看者对视频的感受,而是标注视频中讲述者的情感倾向。
MOSI数据集收集了YouTube上关于电影评论视频为主的视频博客(vlog)。视频的长度从2-5分钟不等,总共随机收集了93个视频,这些视频来自89位不同的讲述者,其中有41位女性和48位男性,大多数演讲者的年龄大约在20到30岁之间,来自不同的种族背景。这些视频的标注由来自亚马逊众包平台的五个标注者进行标注并取平均值,标注为从-3到+3的七类情感倾向。该数据集的情感标注不是观看者的感受,而是标注视频中的评论者的情感倾向。
CMU-MOSEI收集的数据来自YouTube的独白视频,并且去掉了那些包含过多人物的视频。最终的数据集包含3228个视频,23453个句子,1000个讲述者,250个话题,总时长达到65小时。数据集既有情感标注又有情绪标注。情感标注是对每句话的7分类的情感标注,作者还提供了了2/5/7分类的标注。情绪标注是包含高兴,悲伤,生气,恐惧,厌恶,惊讶六个方面的情绪标注。
方法
评论视频文件包含文字(字幕)、图像、语音三种信息,因此面向评论视频的情感分类任务所需要处理的对象是三种模态。视频可以看作图像在时间序列上的排列,相比起单张的图片多了时间这一属性,因此可以使用RNN及其变体对其进行编码。接下来将介绍三篇关于面向评论视频的多模态情感分类模型的工作,分别是EMNLP2017上的Tensor Fusion Network[4]和AAAI2018上的 Multi-attention Recurrent Network[5]、Memory Fusion Network[6]。
TFN(Tensor FusionNetwork)
Zadeh和他的团队[4]提出了一种基于张量外积(Outer product)的多模态融合方法,这也是TFN名字的来源。在编码阶段,TFN使用一个LSTM+2层全连接层的网络对文本模态的输入进行编码,分别使用一个3层的DNN网络对语音和视频模态的输入进行编码。在模态融合阶段,对三个模态编码后的输出向量作外积,得到包含单模态信息、双模态和三模态的融合信息的多模态表示向量,用于下一步的决策操作。
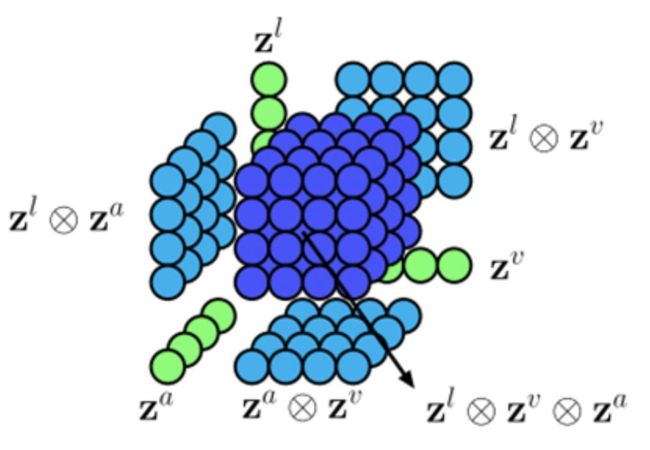
图4 TFN模型架构
MARN(Multi-attention RecurrentNetwork)
MARN基于一个假设:“模态间存在多种不同的信息交互”,这一假设在认知科学上得到了证实。MARN基于此提出使用多级注意力机制提取不同的模态交互信息。模型架构如图5所示。在编码阶段,作者在LSTM的基础上提出了“Long-shortTerm Hybrid Memory”,加入了对多模态表示的处理,同时将模态融合和编码进行了结合。由于在每个时刻都需要进行模态融合,要求三种模态的序列长度相等,因此需要在编码前进行模态对齐。
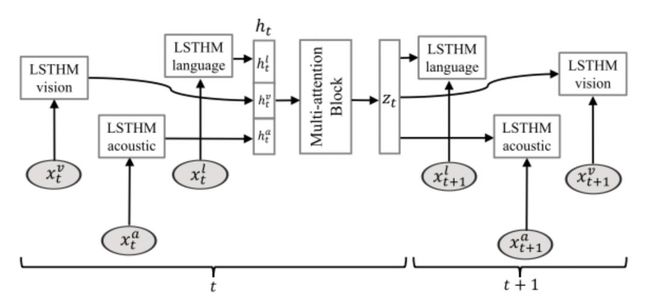
图5 MARN模型架构
MFN(Memory Fusion Network)
MARN考虑了注意力权重的多种可能分布,MFN则考虑了注意力处理的范围。MFN和MARN一样将模态融合与编码相结合,不同的是,在编码的过程中模态间是相互独立的,由于使用的是LSTM,并没有一个共享的混合向量加入计算,取而代之的,MFN使用“Delta-memoryattention”和“Multi-View Gated Memory”来同时捕捉时序上和模态间的交互。保存上一时刻的多模态交互信息。图6展示了MFN在t时刻的处理过程。

图6.MFN模型架构
面向对话视频的情感分类任务
数据集
MELD数据集源于EmotionLines数据集,后者是一个纯文本的对话数据集,来自于经典的电视剧老友记。MELD数据集是在此基础上的包含视频,文本,音频的多模态数据集,最终的数据集包含13709个片段,对个片段不仅有包含恐惧等七种在内的情绪标注,也有积极,消极,中性三分类的情感标注。
IEMOCAP数据集是比较特殊的,它既不是收集自现有的YouTube等影视平台的用户上传视频,也不是收集自老友记等知名电视节目的,它是由10个演员围绕具体的主题进行表演并记录得到的多模态数据集。数据集收集的是由5个专业男演员和5个专业女演员,围绕主题进行会话表演得到的视频,总共包括4787条即兴会话和5255条脚本化会话,每个会话平均持续时间4.5秒,总时长11小时。最终的数据标注是情绪标注,共有包含恐惧,悲伤在内的十个类别。
方法
对话情感分类的目的是判断每一个对话片段的情感极性,需要考虑说话人信息和对话的场景信息,且受前段对话内容的影响较大。DialogueRNN[7]使用3个GRU对说话人信息、前段对话的语境信息和情感信息进行建模。该模型定义了全局的语境状态(Globalstate)和对话参与者的状态(Party state)。结构上分为GlobalGRU、Party GRU和Emotion GRU三个部分,Global GRU用于计算并更新每一时刻的Globalstate。Party GRU用于计算并更新当前时刻(轮)的说话者的Partystate。Emotion GRU则用于计算当前对话内容的情感表示。
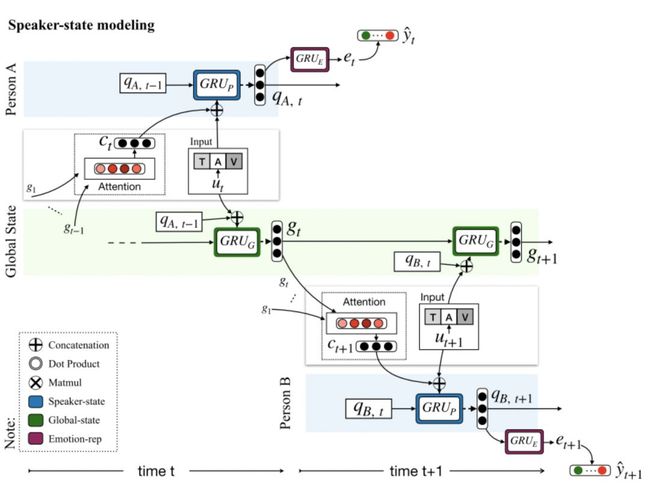
图7 DialogueRNN模型架构
面向新闻视频的情感分类任务
数据集
News Rover Sentiment数据集是新闻领域的数据集。该数据集使用的视频是在2013年8月13日至2013年12月25日之间录制的美国各种新闻节目和频道的视频。数据集按人员、职业进行了分类,视频长度限制在4到15秒之间。因为作者认为,很难在很短的视频中解读出人们的情绪,而15秒以上的视频可能会有多个带有不同情绪的语句。最终整个数据集有929个片段,对每一个片段都进行了三分类的情感标注。
面向对话视频的反讽识别任务
数据集
MUStARD是一个关于多模态讽刺检测的数据集,它的来源很广泛,包含知名的电视剧,生活大爆炸,老友记,黄金女郎等,作者从这些包含讽刺的电视剧中收集了讽刺相关的视频,又从MELD数据集中获得非讽刺的视频,最终的的数据集包含690个视频片段,其中345个是具有讽刺的视频片段,另外345个是不具有讽刺的视频片段,数据集的标注就是是否具有讽刺。
上述数据集信息可以总结为表2。
表2 多模态情感分析相关数据集信息表
总结
本文简单梳理了多模态情感分析领域的相关任务,总结了与任务对应的数据集及一些典型的方法。虽然多模态数据提供了更多的信息,但是如何处理和分析多模态信息、如何融合不同模态的信息还是多模态情感分析领域需要解决的主要问题。
参考文献
[1] Truong T Q, Lauw H W. VistaNet:Visual Aspect Attention Network for Multimodal Sentiment Analysis[C]. nationalconference on artificial intelligence, 2019: 305-312.
[2] Xu N, Mao W, Chen G, et al.Multi-Interactive Memory Network for Aspect Based Multimodal SentimentAnalysis[C]. national conference on artificial intelligence, 2019: 371-378.
[3] Cai Y, Cai H, Wan X, et al.Multi-Modal Sarcasm Detection in Twitter with Hierarchical Fusion Model[C].meeting of the association for computational linguistics, 2019: 2506-2515.
[4] Zadeh A, Chen M, Poria S, et al.Tensor Fusion Network for Multimodal Sentiment Analysis[C]. empirical methodsin natural language processing, 2017: 1103-1114.
[5] Zadeh A, Liang P P, Poria S, etal. Multi-attention Recurrent Network for Human Communication Comprehension[J].arXiv: Artificial Intelligence, 2018.
[6] Zadeh A, Liang P P, Mazumder N,et al. Memory Fusion Network for Multi-view Sequential Learning[J]. arXiv:Learning, 2018.
[7] Majumder N, Poria S, Hazarika D,et al. DialogueRNN: An Attentive RNN for Emotion Detection in Conversations[C].national conference on artificial intelligence, 2019: 6818-6825.
[8] Yu J, Jiang J. Adapting BERT forTarget-Oriented Multimodal Sentiment Classification[C]. international jointconference on artificial intelligence, 2019: 5408-5414.
[9] Morency L, Mihalcea R, Doshi P,et al. Towards multimodal sentiment analysis: harvesting opinions from theweb[C]. international conference on multimodal interfaces, 2011: 169-176.
[10] Wollmer M, Weninger F, Knaup T,et al. YouTube Movie Reviews: Sentiment Analysis in an Audio-Visual Context[J].IEEE Intelligent Systems, 2013, 28(3): 46-53.
[11] Zadeh A. Micro-opinionSentiment Intensity Analysis and Summarization in Online Videos[C].international conference on multimodal interfaces, 2015: 587-591.
[12] Zadeh A B, Liang P P, Poria S,et al. Multimodal Language Analysis in the Wild: CMU-MOSEI Dataset andInterpretable Dynamic Fusion Graph[C]. meeting of the association forcomputational linguistics, 2018: 2236-2246.
[13] Poria S, Hazarika D, MajumderN, et al. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition inConversations[J]. arXiv: Computation and Language, 2018.
[14] Busso C, Bulut M, Lee C, et al.IEMOCAP: interactive emotional dyadic motion capture database[J]. languageresources and evaluation, 2008, 42(4): 335-359.
[15] Ellis J G, Jou B, ChangS, et al. Why We Watch the News: A Dataset for Exploring Sentiment in BroadcastVideo News[C]. international conference on multimodal interfaces, 2014:104-111.
[16] Castro S, Hazarika D,Perezrosas V, et al. Towards Multimodal Sarcasm Detection (An _Obviously_Perfect Paper).[J]. arXiv: Computation and Language, 2019.
本期责任编辑:丁 效
本期编辑:顾宇轩
方便交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐阅读:
【ACL 2019】腾讯AI Lab解读三大前沿方向及20篇入选论文
【一分钟论文】IJCAI2019 | Self-attentive Biaffine Dependency Parsing
【一分钟论文】 NAACL2019-使用感知句法词表示的句法增强神经机器翻译
【一分钟论文】Semi-supervised Sequence Learning半监督序列学习
【一分钟论文】Deep Biaffine Attention for Neural Dependency Parsing
详解Transition-based Dependency parser基于转移的依存句法解析器
经验 | 初入NLP领域的一些小建议
学术 | 如何写一篇合格的NLP论文
干货 | 那些高产的学者都是怎样工作的?
一个简单有效的联合模型
近年来NLP在法律领域的相关研究工作

让更多的人知道你“在看”
