使用Spring Cloud Sleuth和Zipkin进行分布式跟踪(学习笔记)
源码:使用Spring Cloud Sleuth和Zipkin进行分布式跟踪。
这一章主要讲的是,之前自己写的关联ID的注入与传播,用Sleuth来搞定,然后再加上统一日志管理。
一、Spring Cloud Sleuth与关联ID
1.Pom依赖
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-sleuthartifactId>
dependency>
只需要增加个依赖,跟踪状态就有了,是真滴方便。
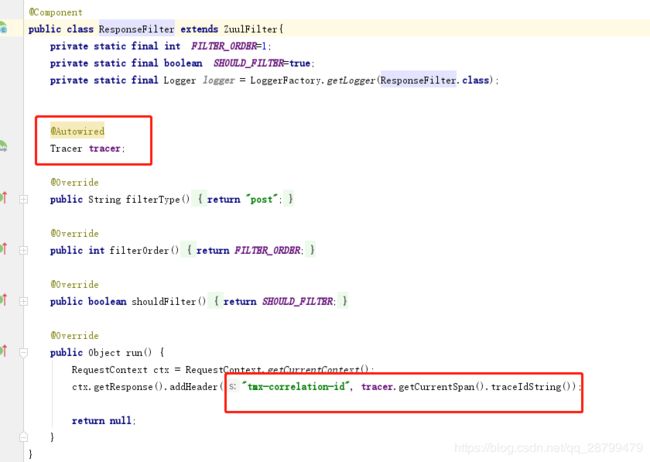
2.使用Zuul将关联ID添加到HTTP响应。
Sleuth官方认为在http返回中返回跟踪ID是不安全的,所以没有返回,但是我们是需要的,所以要在Zuul的后置过滤器里配制一下。
二、使用Open Zipkin进行分布式跟踪
1.许可证,组织,路由服务添加pom依赖
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-sleuthartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-sleuth-zipkinartifactId>
dependency>
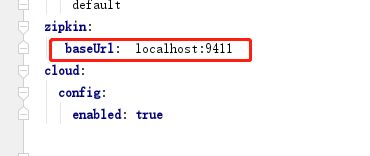
2.配置服务以指向Zipkin
3.安装和配置Zipkin服务器
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-uiartifactId>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-serverartifactId>
dependency>

Zipkin支持4种不同的后端数据存储,分别是:
- 内存数据
- MySQL
- Cassandra
- Elasticsearch
默认是内存。
4.设置跟踪级别
默认情况下,zipkin只会将所有事务的10%写进Zipkin服务器。
可以设为这个值为1.
spring:
sleuth:
sampler:
percentage: 1
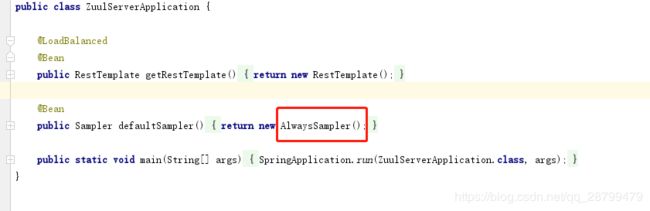
也可以替换一个Bean,见名知意,总是发送。
5.使用Zipkin跟踪事务
配置文件里,url要加http,不然会报错:

还是像之前那样将配置服务改成native本地模式,然后依次开启Eureka->配置服务-》日志服务->组织和许可证-》路由。
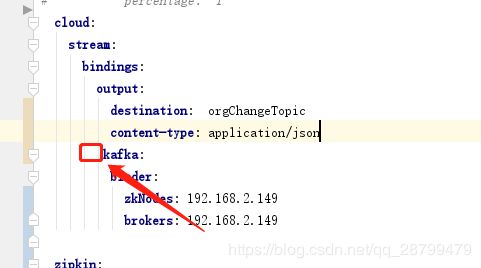
在运行组织符合和许可证服务的时候,发现老是往localhost上连,调了三个小时才发现,妈耶,一个空格引发的血案:
这俩是一级的,源码有个错误:
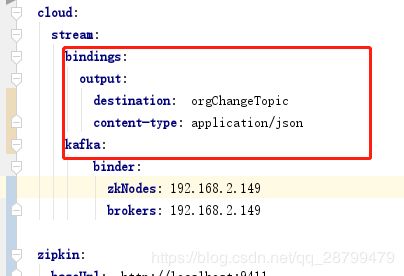
许可证服务配置的也不对:
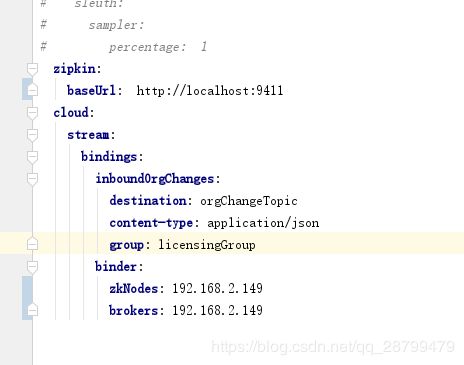
这样才对:
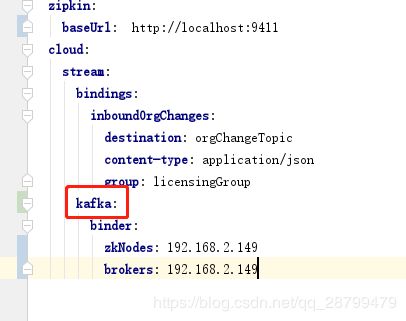
然后用postman请求两次:

接下来就可以跳到localhost:/9411见证奇迹的时刻了~
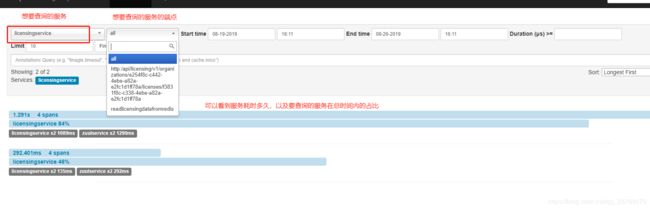
然后点开一个详细查看:
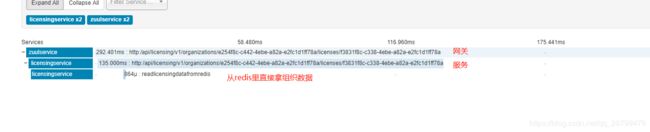
还可以继续点下去,更详细:

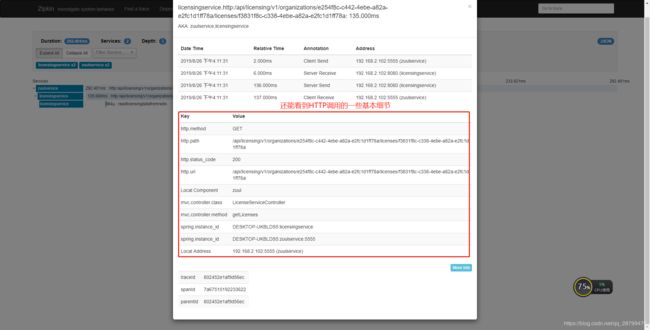
6.捕获消息传递跟踪
我们知道,之前的设计是,当组织产生更新或者删除时,发送消息到消息队列,然后通知许可证服务刷新redis。然后我们可以用它返回的id来跟踪消息传递。
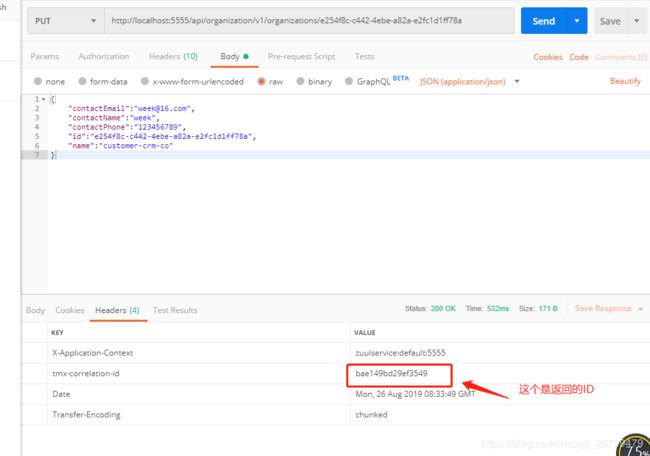
在Zipkin右上角输入它,回车即可:
![]()

但是很可惜,关联ID不会传递到消息队列里去,所以我们手动查一下许可证服务:


7.添加自定义跨度
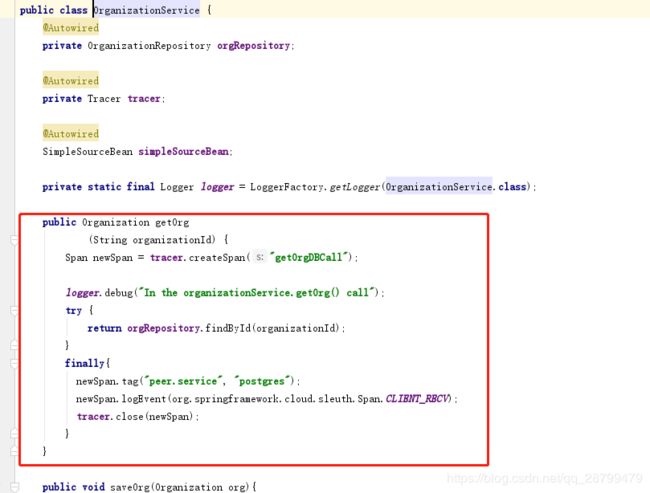
Zipkin可以监控在SPring环境中的调用,但是redis呀,sql呀, 它监控不到,所以要添加自定义跨度,其实我们之前的记录已经显示redis的时间了,为什么呢?因为已经配置了,代码是这样的:

记得一定要关闭跟踪,否则会报错:打开却未关闭。
同样,组织服务的Postgres数据库操作,也需要定义个跨度:
三、日志聚合与Spring Cloud Sleuth
现在用云聚合日志服务来保存日志,原理是,docker里运行的标准输出都输出到了Docker.sock,然后用Logspout Docker容器监听Docker.sock,将得到的内容写入远程syslog位置。
1.创建Papertrail账户并配置syslog连接器
可能需要科学上网:Papertrail。我看了一下,阿里云也有类似的东西,改日用阿里试试。
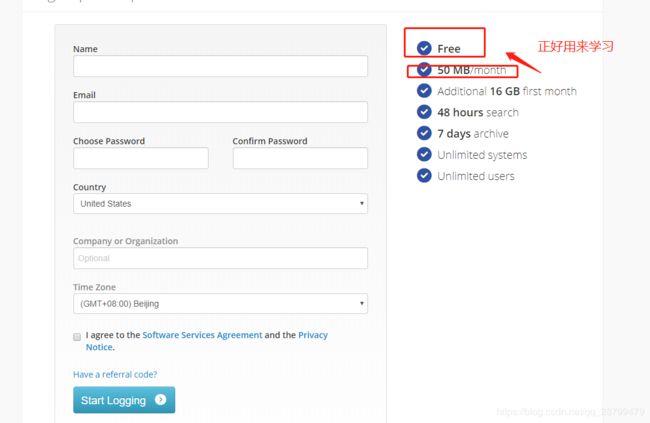
因为是免费账户,所以创建很简单:
然后添加一个日志记录连接就可以了:
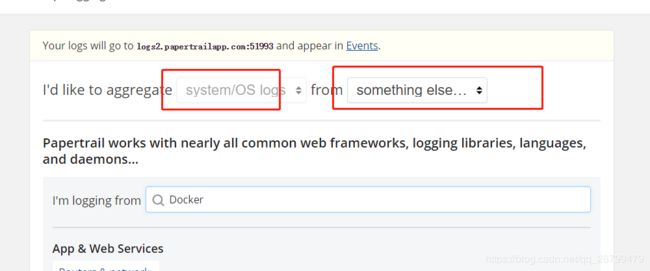
2.将docker输出重定向到Papertrail
把docker-compose.yml更改一下:那里改成自己的地址。
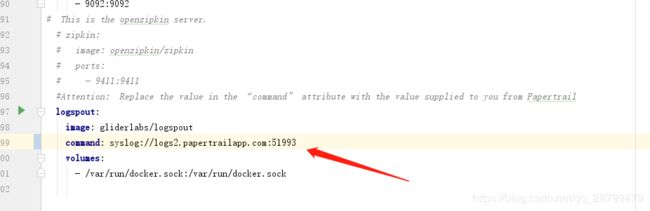
然后运行docker环境,怎么运行可以参考我之前写的博客:包含docker运行配置。
要素就是先打包再用docker build。然后如果映射路径啊什么的都配置好了的话,run.sh里的这些也可以都删除
精简一下docker-compose.yml文件,如下:
version: "3"
services:
eurekaserver:
image: johncarnell/tmx-eurekasvr:chapter9
ports:
- "8761:8761"
configserver:
image: johncarnell/tmx-confsvr:chapter9
ports:
- "8888:8888"
zipkin:
image: johncarnell/tmx-zipkinsvr:chapter9
ports:
- "9411:9411"
zuulserver:
image: johncarnell/tmx-zuulsvr:chapter9
ports:
- "5555:5555"
licensingservice:
image: johncarnell/tmx-licensing-service:chapter9
ports:
- "8080:8080"
organizationservice:
image: johncarnell/tmx-organization-service:chapter9
ports:
- "8081:8081"
logspout:
image: gliderlabs/logspout
command: syslog://logs2.papertrailapp.com:51993
volumes:
- /var/run/docker.sock:/var/run/docker.sock
然后:
#初始化
docker swarm init
#运行 将服务命名为 mysite
docker stack deploy -c docker-compose.yml mysite
#查看运行状况
docker service ls
等整个服务起来,就可以在云后台看到日志了:

