Kaggle实战之leaf classification(树叶分类)
介绍
首先来直观看下所要分类的图像数据:

在这里一共是99种树叶,每种树叶包含16幅图像,因此训练集中一共1584幅图像。然而,我们不对图像直接操作,kaggle为每个图像提供三组特征:形状连续描述符,内部纹理直方图和细尺度边缘直方图。 对于每个特征,每个叶样本给出一个64属性的向量,因此,对于一幅图像来说,一共是64x3=192个向量。kaggle把每个训练图像转化成一个192维向量,并把所有训练图像的数据保存到train.csv文件中,包括标签。这样,在实际训练使用时,可以直接提取train.csv文件中的数据,其实是kaggle直接把数据给提取好了,不需要对图像再进行操作。train.csv文件中的内容如下所示:

树叶分类
当拿到数据和标签后,第一个问题就是该如何分类,选择哪种分类器,不急,一步一步推进吧!
第一步:导入训练和测试数据
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
def warn(*args, **kwargs): pass
import warnings
warnings.warn = warn
from sklearn.preprocessing import LabelEncoder
from sklearn.cross_validation import StratifiedShuffleSplit
train = pd.read_csv('C:/Users/new/Desktop/data/train.csv')
test = pd.read_csv('C:/Users/new/Desktop/data/test.csv')第二步:准备好训练/测试数据以及标签
def encode(train, test):
le = LabelEncoder().fit(train.species) #对数据进行标签编码
labels = le.transform(train.species) # encode species strings
classes = list(le.classes_) # save column names for submission
test_ids = test.id # save test ids for submission
train = train.drop(['species', 'id'], axis=1)
test = test.drop(['id'], axis=1)
return train, labels, test, test_ids, classes
train, labels, test, test_ids, classes = encode(train, test)编码后的部分标签数据:
[ 3 49 65 94 84 40 54 78 53 89 98 16 74 50 58 31 43 4 75 44 83 84 13 66
15 6 73 22 73 31 36 27 94 88 12 28 21 25 20 60 84 65 69 58 23 76 18 52
54 9 48 47 64 81 83 36 58 21 81 20 62 88 34 92 79 82 20 32 4 84 36 35
72 60 71 72 52 50 54 11 51 18 47 5 8 37 97 20 33 1 59 1 56 1 9 57
20 79 29 16 32 54 93 10 46 59 84 76 15 10 15 0 69 4 51 51 94 36 39 62...
]注意:这里采用的不是深度学习中的one-hot编码格式
第三步:从train数据集中继续划分train和test
这样做的原因就是为了评估出后面哪种分类器效果比较好,在这里训练集和测试集比例为4:1。
sss = StratifiedShuffleSplit(labels, 10, test_size=0.2, random_state=23)
for train_index, test_index in sss:
X_train, X_test = train.values[train_index], train.values[test_index]
y_train, y_test = labels[train_index], labels[test_index]第四步:分类器的选择
由于kaggle已经帮我们把图像数据转换成离散数据了,因此深度学习方式不再适合,可以选择传统机器学习方式。下面是从sklearn中导出几种常见的机器学习模型,并在这些模型的基础上测试分类效果:
from sklearn.metrics import accuracy_score, log_loss
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC, LinearSVC, NuSVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
classifiers = [
KNeighborsClassifier(3),
SVC(kernel="rbf", C=0.025, probability=True),
NuSVC(probability=True),
DecisionTreeClassifier(),
RandomForestClassifier(),
AdaBoostClassifier(),
GradientBoostingClassifier(),
GaussianNB(),
LinearDiscriminantAnalysis(),
QuadraticDiscriminantAnalysis()]
# Logging for Visual Comparison
log_cols=["Classifier", "Accuracy", "Log Loss"]
log = pd.DataFrame(columns=log_cols)
for clf in classifiers:
clf.fit(X_train, y_train)
name = clf.__class__.__name__
print("="*30)
print(name)
print('****Results****')
train_predictions = clf.predict(X_test)
acc = accuracy_score(y_test, train_predictions)
print("Accuracy: {:.4%}".format(acc))
train_predictions = clf.predict_proba(X_test)
ll = log_loss(y_test, train_predictions)
print("Log Loss: {}".format(ll))
log_entry = pd.DataFrame([[name, acc*100, ll]], columns=log_cols)
log = log.append(log_entry)
print("="*30)
sns.set_color_codes("muted")
sns.barplot(x='Accuracy', y='Classifier', data=log, color="b")
plt.xlabel('Accuracy %')
plt.title('Classifier Accuracy')
plt.show()
sns.set_color_codes("muted")
sns.barplot(x='Log Loss', y='Classifier', data=log, color="g")
plt.xlabel('Log Loss')
plt.title('Classifier Log Loss')
plt.show()该测试是用上述划分好的训练集来训练模型,测试集来测试训练好的模型,测试结果如下:
==============================
KNeighborsClassifier
****Results****
Accuracy: 88.8889%
Log Loss: 1.5755075129933762
==============================
SVC
****Results****
Accuracy: 81.8182%
Log Loss: 4.595121963548277
==============================
NuSVC
****Results****
Accuracy: 88.3838%
Log Loss: 2.477413579410947
==============================
DecisionTreeClassifier
****Results****
Accuracy: 60.1010%
Log Loss: 13.780622905040218
==============================
RandomForestClassifier
****Results****
Accuracy: 89.3939%
Log Loss: 0.9909596699870593
==============================
AdaBoostClassifier
****Results****
Accuracy: 4.5455%
Log Loss: 4.207215776494153
==============================
GradientBoostingClassifier
****Results****
Accuracy: 57.0707%
Log Loss: 2.525105423887634
==============================
GaussianNB
****Results****
Accuracy: 57.0707%
Log Loss: 14.827252492813216
==============================
LinearDiscriminantAnalysis
****Results****
Accuracy: 97.9798%
Log Loss: 0.93019777631393
==============================
QuadraticDiscriminantAnalysis
****Results****
Accuracy: 1.5152%
Log Loss: 34.01546160104849
==============================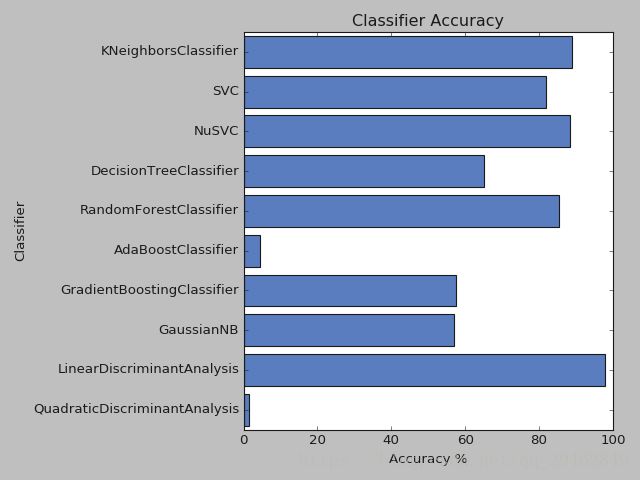
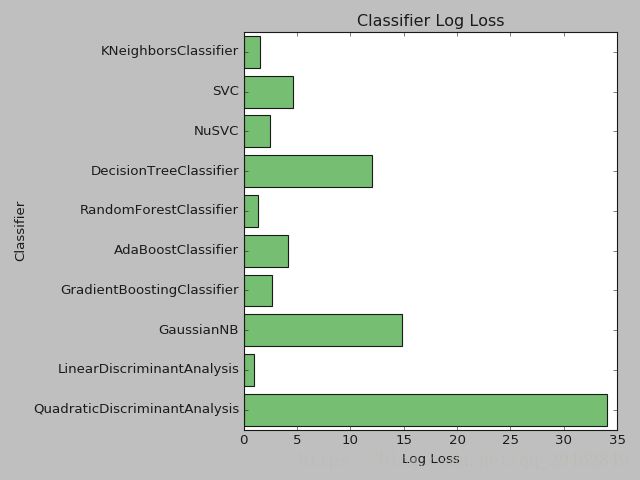
通过测试结果发现,LinearDiscriminantAnalysis效果最好,达到了97.98%,深度学习也不过如此吧,看来机器学习模型,也不一定很差,那就选定LinearDiscriminantAnalysis作为分类器了~
第五步:对无标签的数据进行分类
kaggle提供的数据中,test.csv是无标签数据,需要参赛人员使用选定的分类器进行分类,在这里选择LinearDiscriminantAnalysis分类器进行分类:
# Predict Test Set
favorite_clf = LinearDiscriminantAnalysis()
favorite_clf.fit(X_train, y_train)
test_predictions = favorite_clf.predict_proba(test)
# Format DataFrame
submission = pd.DataFrame(test_predictions, columns=classes)
submission.insert(0, 'id', test_ids)
submission.reset_index()
# Export Submission
submission.to_csv('submission.csv', index = False)#把结果写进提交文件中
submission.tail()部分结果:

实验所用数据:Leaf Classification