第二章 字符串String & 数组 & 数据类型
文章目录
- 说说Java中的8大基本类型 & 内存中占有的字节 & 初始值?
- 知道float和double类型为什么会出现精度丢失的情况吗?
- JAVA基本数据类型与封装类型的区别?
- 什么是拆箱 & 装箱,能给我举栗子吗?
- 能说说多维数组在内存上是怎么存储的吗?
- 你对数组二次封装过吗?说说封装了什么?
- String
- 原理 & 不可变性
- String && StringBuilder && StringBuffer
- 内存中存储
- 字符串拼接方式 & 比较
- String a = "a"+"b"+"c";在内存中创建了几个对象?
说说Java中的8大基本类型 & 内存中占有的字节 & 初始值?
bit(位):表示信息的最小单位,是二进制数的一位包含的信息;
byte(字节):用来计量存储容量的一种计量单位;
1 byte = 8 bit(1个字节等于8位);
| 基本类型 | 占据空间大小 | 取值范围 | 默认值 |
|---|---|---|---|
| 布尔型——boolean | 不确定 | true/false | false |
| 字节型——byte | 1个字节 | -128~127 | 0 |
| 整型——int | 4个字节 | -2^31 ~ 2^31-1(-2147483648~2147483647) | 0 |
| 短整型——short | 2个字节 | -2^15 ~ 2^15-1(-32768~32767) | 0 |
| 长整型——long | 8个字节 | -2^63 ~ 2^63-1(-9223372036854775808 ~ 9223372036854775807) | 0 |
| 字符型——char | 2个字节 | 0~2^16-1(0 ~ 65535无符号) | \u0000 |
| 单精度浮点型——float | 4个字节 | -2^128 ~ 2^128 | 0.0F |
| 双精度浮点型——double | 8个字节 | -2^1024 ~ 2^1024 | 0.0D |
(1)带符号数(正数/负数)在计算机中存储方式?
原码:原码就是符号位加上真值的绝对值, 即用第一位表示符号, 其余位表示值。
补码:正数的补码就是其本身。负数的补码是在其原码的基础上, 符号位不变, 其余各位取反, 最后+1. (即在反码的基础上+1)
补码是计算机存储带符号数的方式,可以解决0的符号问题以及两个编码问题。
为什么byte类型(8位二进制表示)的取值范围为-128~127?
0用[0000 0000]表示,-128用[1000 0000]表示。byte类型1个字节,8位二进制,范围为[1000 0000]~[0111 1111]
(2)浮点数(小数)在计算机中存储方式?
- 小数(浮点数)的二进制转换
78.375 的整数部分:
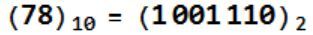
小数部分:

所以,78.375 的二进制形式就是 1001110.011
然后,使用二进制科学记数法,有
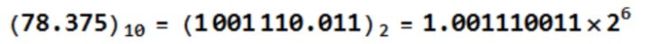
注意,转换后用二进制科学记数法表示的这个数,有底有指数有小数部分,这个就叫做浮点数。 - 浮点数在计算机中存储
在计算机中,保存这个数使用的是浮点表示法,分为三大部分:
第一部分用来存储符号位(sign),用来区分正负,这里是 0,表示正数
第二部分用来存储指数(exponent),这里的指数是十进制的 6
第三部分用来存储小数(fraction),这里的小数部分是 001110011

指数位决定了大小范围,因为指数位能表示的数越大则能表示的数越大,而小数位决定了计算精度,因为小数位能表示的数越大,则能计算的精度越大。
- float类型是32位,是单精度浮点表示法:
符号位占用1位,指数位占用 8 位,小数位占用 23 位。
float 的小数位只有 23 位,即二进制的 23 位,能表示的最大的十进制数为 2 的 23 次方,即 8388608,即十进制的 7 位,严格点,精度只能百分百保证十进制的 6 位运算。 - double 类型是 64 位,是双精度浮点表示法:
符号位占用 1 位,指数位占用 11 位,小数位占用 52 位。
double 的小数位有 52 位,对应十进制最大值为 4 503 599 627 370 496,这个数有 16 位,所以计算精度只能百分百保证十进制的 15 位运算。
- 指数位的偏移与无符号表示
float 的指数部分是 8 位,则指数的取值范围是 -126 到 +127,为了消除负数带来的实际计算上的影响(比如比较大小,加减法等),可以在实际存储的时候,需要把指数转换为无符号整数,即给指数做一个简单的映射,加上一个偏移量,比如float的指数偏移量为 127,这样就不会有负数出现了。比如:指数如果是 6,则实际存储的是 6+127=133,即把 133 转换为二进制之后再存储。
对应的 double 类型,存储的时候指数偏移量是 1023。 - 举例求78.375浮点数表示
所以用float类型来保存十进制小数78.375的话,需要先转换成浮点数,得到符号位和指数和小数部分。符号位是0,指数位是6+127=133,二进制表示为10 000 101,小数部分是001110011,不足部分请自动补0。
连起来用 float 表示,加粗部分是指数位,最左边是符号位 0,代表正数:
0 10000101 001110011 00000 00000 0000
知道float和double类型为什么会出现精度丢失的情况吗?
(1)浮点型数据精度丢失的原因
将十进制浮点数转换为二进制浮点数时,小数的二进制有时也是不可能精确的。
就如同十进制不能准确表示1/3,二进制也无法准确表示1/10,而double类型存储尾数部分最多只能存储52位,于是,计算机在存储该浮点型数据时,便出现了精度丢失。
例:十进制小数如何转化为二进制数
算法是乘以2直到没有了小数为止。举个例子,0.9表示成二进制数
0.9*2=1.8 取整数部分 1
0.8(1.8的小数部分)*2=1.6 取整数部分 1
0.6*2=1.2 取整数部分 1
0.2*2=0.4 取整数部分 0
0.4*2=0.8 取整数部分 0
0.8*2=1.6 取整数部分 1
0.6*2=1.2 取整数部分 0
.........
0.9二进制表示为(从上往下): 1100100100100......
注意:上面的计算过程循环了,也就是说*2永远不可能消灭小数部分,这样算法将无限下去。很显然,小数的二进制表示有时是不可能精确的 。
因此将11.9化为二进制后大约是” 1011. 1110011001100110011001100…”。
(2)浮点型数据精度丢失的解决方法
商业运算中应用场景:例如某用户有10块钱,买了一件商品花了8.8,理应剩下1.2元。但却无法继续购买价格为1.2元的商品。
double d1 = 10;
double d2 = 8.8;
double c = d1 - d2;
System.out.println("d1 - d2 = "+c);
// 输出
d1 - d2 = 1.1999999999999993
- 解决方法1
在设计数据库表的时候可以将price字段类型设置为int(oracle应设置为number)类型,而在实体中对应的属性单位应该表示为分(即精确到0.00)或者角(即0.0),但一般情况下money会精确到分。
如:商品的价格为12.53元(精确到分),在数据库中price字段对应的数据为应该为1253。使用这种方法需要编程人员自己在程序中收懂转换,当然也可以封装为一个工具类。 - 解决方法2
使用java提供的BigDecimal类。该类封装在java.math.BigDecimal中。该类的构造器有很多,但在使用浮点类型计算时一定要使用String构造器来实例BigDecimal对象。
//加法
public static BigDecimal add(double v1,double v2){
BigDecimal b1 = new BigDecimal(Double.toString(v1));//这里使用的是String构造器,将double转换为String类型
BigDecimal b2 = new BigDecimal(Double.toString(v2));
return b1.add(b2);
}
//减法
public static BigDecimal sub(double v1,double v2){
BigDecimal b1 = new BigDecimal(Double.toString(v1));//同上
BigDecimal b2 = new BigDecimal(Double.toString(v2));
return b1.subtract(b2);//这是b1-b2,可以理解为从b1截取b2
}
//乘法
public static BigDecimal mul(double v1,double v2){
BigDecimal b1 = new BigDecimal(Double.toString(v1));//同上
BigDecimal b2 = new BigDecimal(Double.toString(v2));
return b1.multiply(b2);
}
//除法
public static BigDecimal div(double v1,double v2){
BigDecimal b1 = new BigDecimal(Double.toString(v1));
BigDecimal b2 = new BigDecimal(Double.toString(v2));
return b1.divide(b2,2,BigDecimal.ROUND_HALF_UP); //四舍五入,保留2位小数,除不尽的情况
}
JAVA基本数据类型与封装类型的区别?
封装类(如Integer)是基本数据类型(如int)的包装类。
| 封装类(Integer) | 基本类型(int) | |
|---|---|---|
| 存储数据 | 封装类本质是对象的引用,需实例化后使用。实际上是生成一个指向该对象的引用(存储对象地址) | 值(基本数据类型是一个变量,直接存放数值) |
| 属性和方法 | 封装类有属性和方法,利用这些方法和属性来处理数据,如Integer.parseInt(Strings) | 基本数据类型都是final修饰的,不能继承扩展新的类、新的方法 |
| 默认值 | null | 0 |
| 存储位置 | 封装类的对象引用存储在栈中,实际的对象存储在堆中 | 栈 |
| 使用场景 | 更好地处理数据之间的转换 | 速度快(不涉及对象的构造与回收) |
什么是拆箱 & 装箱,能给我举栗子吗?
封装类(如Integer)是基本数据类型(如int)的包装类。装箱就是 自动将基本数据类型转换为包装器类型;拆箱就是 自动将包装器类型转换为基本数据类型。
- 装箱(基本数据类型->封装类)
Integer i = 10; // 实际上执行Integer.valueOf(10);
- 拆箱(封装类->基本数据类型)
Integer i = 10; //装箱
int t = i; //拆箱,实际上执行了 int t = i.intValue();
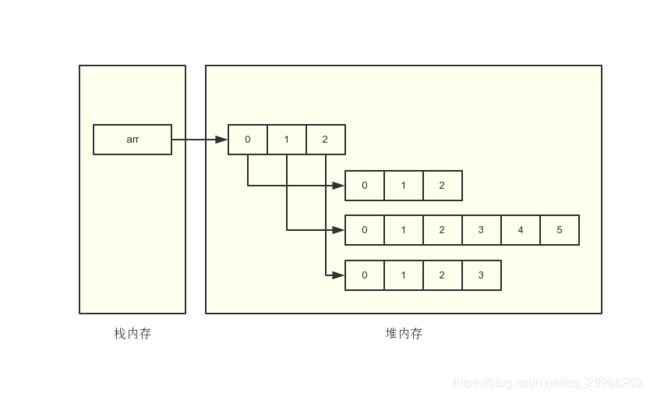
能说说多维数组在内存上是怎么存储的吗?
在java中数组也是对象。因此,对象存放在内存中的原理同样适用于数组。
当创建一个数组时,在堆中会为数组对象分配一段内存空间,并返回一个引用。数组对象的引用存放在栈中,实际的数组对象存放在堆中。
多维数组在内存中存储方式:
你对数组二次封装过吗?说说封装了什么?
使用Java一维数组,仿照ArrayList源码,封装相关构造、获取元素个数、容量大小、判空、增删查改等功能。
对Java一维数组E[]自定义ArrayList集合
下面是部分实现:
/**
* 通过对数组封装实现自己的Array类
*/
public class MyArrayList<E> {
private E[] data; // 定义一个整型的一维数组的成员变量
private int size; // 数组中元素个数
// 获取数组中元素的个数
public int getSize() {
return size;
}
// 判断数组是否为空
public boolean isEmpty() {
return size == 0;
}
// 向数组的第index位置插入元素e
public void add(int index, E e) {
if (index < 0 || index > size)
throw new IllegalArgumentException("Add failed. Require index >= 0 and index <= size.");
if (size - data.length >= 0) {
int newCapacity = data.length + (data.length >> 1); // 扩容1.5倍
resize(newCapacity);
}
for (int i = size - 1; i >= index; i--)
data[i + 1] = data[i];
data[index] = e;
size++;
}
// 动态数组扩容 newCapacity 扩容长度
private void resize(int newCapactity) {
E[] newData = (E[]) new Object[newCapactity];
for (int i = 0; i < size; i++) {
newData[i] = data[i];
}
data = newData;
newData = null;
}
}
String
原理 & 不可变性
- 内部
在 Java 8 中,String 内部使用 char 数组存储数据。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
}
在 Java 9 之后,String 类的实现改用 byte 数组存储字符串,同时使用 coder 来标识使用了哪种编码。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final byte[] value;
/** The identifier of the encoding used to encode the bytes in {@code value}. */
private final byte coder;
}
- 不可变性
String对象是不可变的,即对象的状态(成员变量)在对象创建之后不再改变。
(一)不可变性实现
由String内部构造:
(1)String 被声明为 final,因此它不可被继承。(Integer 等包装类也不能被继承)
(2)value 数组被声明为 final,这意味着 value 数组初始化之后就不能再引用其它数组。
(3)String 内部没有改变 value 数组的方法。
可知String是不可变的。
补充:不可变的实现:
String类被final修饰,保证类不被继承。
String内部所有成员都设置为私有变量,并且用final修饰符修饰,保证成员变量初始化后不被修改。
不提供setter方法改变成员变量,即避免外部通过其他接口修改String的值。
通过构造器初始化所有成员(value[])时,对传入对象进行深拷贝(deep copy),避免用户在String类以外通过改变这个对象的引用来改变其内部的值。
在getter方法中,不要直接返回对象引用,而时返回对象的深拷贝,防止对象外泄。
(二)不可变的好处
- 满足字符串常量池的需要(有助于共享)
可以将字符串对象保存在字符串常量池中以供与字面值相同字符串对象共享。
如果一个 String 对象已经被创建过了,那么就会从 String Pool 中取得引用。只有 String 是不可变的,才可能使用 String Pool。
如果String对象是可变的,那就不能这样共享,因为一旦对某一个String类型变量引用的对象值改变,将同时改变一起共享字符串对象的其他 String类型变量所引用的对象的值。 - 线程安全考虑
同一个字符串实例可以被多个线程共享。字符串的不变性保证字符串本身便是线程安全的。 - 支持hash映射和缓存
因为字符串是不可变的,所以在它创建的时候hashcode就被缓存了,不需要重新计算。这就使得String很适合作为Map中的键,字符串的处理速度要快过其它的键对象。这就是HashMap中的键往往都使用字符串。
缺点:String对象不适用于经常发生修改的场景,会创建大量的String对象。
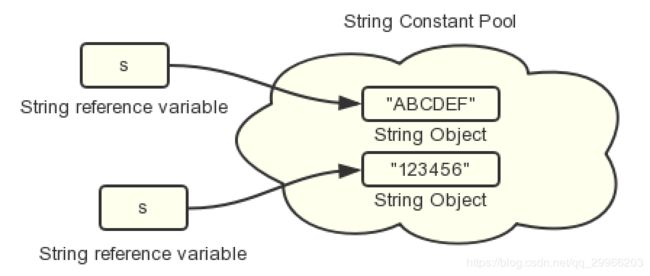
(三)String 的 “改变”?
public static void main(String[] args) {
String s = "ABCDEF";
System.out.println("s = " + s);
s = "123456";
System.out.println("s = " + s);
}
String的改变实际上是创建了一个新的String对象"123456",并将引用指向了这个新的对象,同时原来的String对象"ABCDEF"并没有发生改变,仍保存在内存中。
(四)String 的不可变 真的不可变?
通过反射获取value数组直接改变内存数组中的数据是可以修改所谓的"不可变"对象的。
public static void reflectString() throws Exception{
// 创建字符串"ABCDEF"并赋给引用s
String s = "ABCDEF";
System.out.println("s = " + s); // s = ABCDEF
Field valueField = s.getClass().getDeclaredField("value"); // 获取String类中value字段
valueField.setAccessible(true); // 改变value属性的访问权限
char[] value = (char[]) valueField.get(s); // 获取s对象上的value属性的值
value[0] = 'a'; // 改变value所引用的数组中的某个位置字符
value[2] = 'c';
value[4] = 'e';
System.out.println("s = " + s); // s = aBcDeF
}
String && StringBuilder && StringBuffer
- 可变性
String 不可变
StringBuffer 和 StringBuilder 可变 - 线程安全
String 不可变,因此是线程安全的
StringBuilder 不是线程安全的
StringBuffer 是线程安全的,内部使用 synchronized 进行同步
| String | StringBuffer | StringBuilder | |
| 可变性 | String | StringBuffer | StringBuilder |
| 线程安全 | 安全(不可变) | 安全(Synchronized) | 不安全 |
| 执行效率 | 高 | 低(Synchronized) | 高 |
| 适用场景 | 操作少量的数据,不需要频繁拼接 | 多线程操作大量数据 只有在对线程安全要求高的情况下使用StringBuffer |
单线程操作大量数据 |
| 备注 | 在字符串修改/拼接时,String是不可变的对象, 因此在每次对String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。不仅效率低下,还会大量浪费内存空间。 使用 StringBuffer/StringBuilder 类时,每次都会对 StringBuffer/StringBuilder 对象本身进行修改操作,而不产生新的未使用对象。 | ||
内存中存储
对于String,其对象的引用都是存储在栈中的。
java中对String对象特殊对待,所以在heap区域分成了两块,一块是字符串常量池(String constant pool),用于存储java字符串常量对象,另一块用于存储普通对象及字符串对象。
- "abc"字符串常量/s.intern()——StringPool
编译期已经创建好(直接用双引号定义的"abc")的就存储在字符串常量池中。即jvm会在String constant pool中创建对象。字符串常量池(String Pool)保存着所有字符串字面量(literal strings),这些字面量在编译时期就确定。不仅如此,还可以使用 String 的 intern() 方法在运行过程中将字符串添加到 String Pool 中。String Pool用于共享字符串字面量,防止产生大量String对象导致OOM。
jvm会首先在String constant pool 中寻找是否已经存在(equals)“abc"常量,如果没有则创建该常量,并且将此常量的引用返回给String a;如果已有"abc” 常量,则直接返回String constant pool 中“abc” 的引用给String a。
当一个字符串调用 intern() 方法时,如果 String Pool 中已经存在一个字符串和该字符串值相等(使用 equals() 方法进行确定),那么就会返回 String Pool 中字符串的引用;否则,就会在 String Pool 中添加一个新的字符串,并返回这个新字符串的引用。
equals相等(指向同一引用)的字符串在常量池中永远只有一份。
intern() 方法返回字符串对象的规范化表示形式,即一个字符串,内容与此字符串相同,但一定取自具有唯一字符串的池。
它遵循以下规则:对于任意两个字符串 s 和 t,当且仅当 s.equals(t) 为 true 时,s.intern() == t.intern() 才为 true。
- new String(“abc”)
运行期(new出来的 new String(s))才能确定的就存储在堆中。即jvm会直接在heap中非String constant pool 中创建字符串对象,然后把该对象引用返回给String b(并且不会把"abc” 加入到String constant pool中)。
new就是在堆中创建一个新的String对象,不管"abc"在内存中是否存在,都会在堆中开辟新空间。
equals相等的字符串在堆中可能有多份。
对于 new String(“abc”),使用这种方式一共会创建两个字符串对象(前提是 String Pool 中还没有 “abc” 字符串对象)。这两个字符串对象指向同一个value数组。
- “abc” 属于字符串字面量,因此编译时期会在 String Pool 中创建一个字符串对象,指向这个 “abc” 字符串字面量;
- 而使用 new 的方式会在堆中创建一个字符串对象。
String s1 = new String("aaa");
String s2 = new String("aaa");
System.out.println(s1 == s2); // false,指向堆内不同引用
String s3 = s1.intern();
String s4 = s1.intern();
System.out.println(s3 == s4); // true,指向字符串常量池中相同引用
String s5 = "bbb";
String s6 = "bbb";
System.out.println(s5 == s6); // true,指向字符串常量池中相同引用
字符串拼接方式 & 比较
- 拼接方式
- "+" 拼接
加号拼接字符串jvm底层其实是调用StringBuilder来实现的,也就是说”a” + “b” + "c"等效于下面的代码片。
// String d = "a"+"b"+"c";等效于
String d = new StringBuilder().append("a").append("b").append("c").toString();
但并不是说直接用“+”号拼接就可以达到StringBuilder的效率了,因为每次使用 "+"拼接 都会新建一个StringBuilder对象,并且最后toString()方法还会生成一个String对象。在循环拼接十万次的时候,就会生成十万个StringBuilder对象,会产生大量内存消耗。
- concat 拼接
concat其实就是申请一个char类型的buf数组,将需要拼接的字符串都放在这个数组里,最后再创建并返回一个新的String对象。
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
int len = value.length;
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
return new String(buf, true);
}
- StringBuilder/StringBuffer append
这两个类实现append的方法都是调用父类AbstractStringBuilder的append方法,只不过StringBuffer是的append方法加了sychronized关键字,因此是线程安全的。append代码如下,他主要也是利用char数组保存字符,通过ensureCapacityInternal方法来保证数组容量可用还有扩容。
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
他扩容的方法的代码如下,可见,当容量不够的时候,数组容量右移1位(也就是翻倍)再加2。
private int newCapacity(int minCapacity) {
// overflow-conscious code
int newCapacity = (value.length << 1) + 2;
if (newCapacity - minCapacity < 0) {
newCapacity = minCapacity;
}
return (newCapacity <= 0 || MAX_ARRAY_SIZE - newCapacity < 0)
? hugeCapacity(minCapacity)
: newCapacity;
}
- 拼接比较
| 拼接方式 | + | concat | StringBuilder/StringBuffer |
|---|---|---|---|
| 原理 | jvm采用append优化,每次执行都会新建一个StringBuilder和String对象 | 申请一个char类型的buf数组,将需要拼接的字符串都放在这个数组里,最后再创建并返回一个新的String对象 | 利用char数组保存字符,对Stringbuilder/StringBuffer直接修改,不生成新的String对象 |
| 比较 | 最慢且效率最低,适用于书写方便场景 | 适用于少量字符串拼接(会新建String对象) | 适用于多个字符串拼接,当不考虑线程的情况下,StringBuilder效率比StringBuffer(Synchronized)高 |
String a = “a”+“b”+“c”;在内存中创建了几个对象?
- String a=“a”+“b”+"c"在内存中创建几个对象?——1个对象
String a = “a”+“b”+"c"经过编译器优化后得到的效果为String a = “abc”
java编译期会进行常量折叠,全字面量字符串相加是可以折叠为一个字面常量,而且是进入常量池的。
在JAVA虚拟机(JVM)中存在着一个字符串池,其中保存着很多String对象,并且可以被共享使用,因此它提高了效率。由于String类是final的,它的值一经创建就不可改变,因此我们不用担心String对象共享而带来程序的混乱。字符串池由String类维护,我们可以调用intern()方法来访问字符串池。
对于String a=“abc”;,这行代码被执行的时候,JAVA虚拟机首先在字符串池中查找是否已经存在了值为"abc"的这么一个对象,它的判断依据是String类equals(Object obj)方法的返回值。如果有,则不再创建新的对象,直接返回已存在对象的引用;如果没有,则先创建这个对象,然后把它加入到字符串池中,再将它的引用返回。
字符串内部拼接:只有使用引号包含文本的方式创建的String对象之间使用“+”连接产生的新对象才会被加入字符串池中。对于所有包含new方式新建对象(包括null)的“+”连接表达式,它所产生的新对象都不会被加入字符串池中, - String s=new String(“abc”)创建了几个对象?——2个对象
new String(“abc”)可看成"abc"(创建String对象)和new String(String original)(String构造器,创建String对象)2个对象。
我们正是使用new调用了String类的上面那个构造器方法创建了一个对象,并将它的引用赋值给了str变量。同时我们注意到,被调用的构造器方法接受的参数也是一个String对象,这个对象正是"abc"。