2006年,英国数学家Clive Humbly和Tesco Clubcard的建筑师创造了“数据是新石油”这句话。原话如下:
Data is the new oil. It’s valuable, but if unrefined it cannot be used. It has to be changed into gas, plastic, chemicals, etc. to create a valuable entity that drives profitable activity; so, must data be broken down, analyzed for it to have value.
iPhone革命,移动经济的增长以及大数据技术的进步创造了一场完美风暴。2012年,HBR发表了一篇文章,将数据科学家放在了新的高度上。数据科学家:21世纪最性感的工作这篇文章将这种“信心人类”称为数据黑客、分析师、传播者和值得信赖的顾问的混合体。
如今,几乎每个企业都在强调数据驱动。而机器学习技术的不断进步,正在帮助着企业完成这个目标。在网络上,机器学习相关的资料非常多,但是都太过的技术性并且充斥着大量的高等数学公式等等,让大多数软件工程师难以理解。因此计划编写一系列的文章,使用更加易于理解的方式简化数据科学。
在本文中,将首先介绍数据科学中的基本原理,一般过程和问题类型,对数据科学有一个基本的了解。
数据科学是一个多学科领域。它是以下领域之间的交集:
商业知识
统计学习或称机器学习
计算机编程
本系列文章的重点将是简化数据科学中机器学习方面,而在本文中将首先介绍数据科学中的原理、一般过程和问题的类型等。
关键原则(Key Principles)
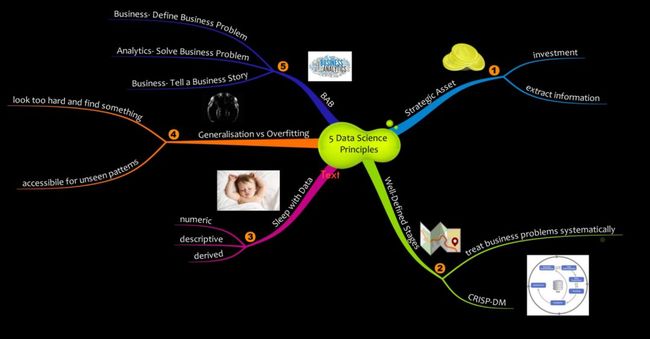
数据是战略资产:这个概念是一种组织思维。问题:“我们是否使用了我们正在收集和存储的所有数据资产?我们能够从中提取有意义的见解吗?”,相信这些问题的答案是:“没有”。基于云科技的公司本质上都是数据驱动的,将数据视为战略资产是他们的灵魂。然而这种观念对于大多数组织来说都是无效的。
系统的知识提取过程:需要有一个有条不紊的过程来提取数据中的隐藏的见解。这个过程应该有明确的阶段和明确的可交付成果。跨行业数据挖掘标准过程(CRISP-DM)就是这样一个过程。
沉浸在数据中:组织需要投资于对数据充满热情的人。将数据转化为洞察力不是炼金术,而且也没有炼金术士
。他们需要了解数据价值的传播者,并且需要具有数据素养和创造力的传道人。更加需要能够连接数据,技术和业务的人。
拥抱不确定性:数据科学并不是一颗银弹,也不是一颗水晶球。像报告和关键绩效指标一样,它是一个决策的辅助者。数据科学是一个工具但是并不仅限于此,而且数据科学也不是一个绝对的科学,它是一个概率的领域,管理者和决策者需要接受这个事实。他们需要在决策过程中体现出量化的不确定性。如果组织文化采用快速学习失败的方法,这种不确定性只能根深蒂固。只有组织选择一种实验文化,它才会兴旺发达。
BAB(Business-Analytics-Business)原则:这是最重要的原则。许多数据科学文献的重点是模型和算法,而这些大多都没有实际的商业实践背景。业务-分析-业务(BAB)是强调模型和算法在业务部分应用的原则。把它们放在商业环境中是至关重要的,定义业务问题,使用分析来解决该业务问题,并将输出集成到业务流程中。
过程(Process)
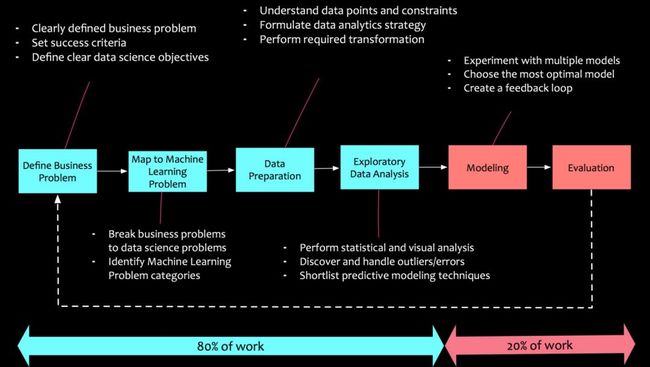
从上述原则#2中可以看到,数据科学的过程对于实现数据科学至关重要,一个典型的数据科学项目可分为如下几个阶段:
1. 定义业务问题
阿尔伯特·爱因斯坦曾经引用过“凡事尽可能简洁,但不能太过简单”,而这句话也正是定义业务问题的核心。问题的表述需要事情的发展历程和所在场景,需要建立明确的成功标准。几乎在所有的企业中,业务团队总是繁忙无比,但是这并不意味着他们没有需要解决的挑战。头脑风暴会议、研讨会和访谈可以帮助揭开任何问题的面纱并提出可能的解决方案或者假设。而对于如何定义业务问题?可参考下例:
一家电信公司由于其客户群减少而导致其收入同比下降。面对这种情况,业务问题可能被定义为:
该公司需要通过瞄准新的细分市场和减少客户流失来扩大客户群。
2. 分解为机器学习任务
业务问题一旦定义好之后,就应该分解为机器学习任务。例如上述的示例,如果该公司需要通过瞄准新的细分市场和减少客户流失来扩大客户群。该如何分解该业务问题为机器学习任务呢?下面是一种分解的示例:
将顾客的流失减少x%。
为有针对性的营销确定新的客户群。
3. 数据准备
一旦确定了业务问题并将其分解为机器学习问题,就需要开始深入研究数据了。对于数据的理解应该明确的针对当前问题,因为当前问题能够帮助制定合适的数据分析策略,并且要注意的是数据的来源、数据的质量以及数据的偏差等。
4. 探索性数据分析
“当宇航员进入宇宙时,他们是不知道宇宙中有什么的。”同样的,数据科学家在开始对数据进行分析时,对于数据中隐含的特征等也都是未知数,他们需要穿过数据的表象去探求和开发新的数据涵义。探索性数据分析(Exploratory data analysis,EDA)是一项令人兴奋的任务,可以更好地理解数据,调查数据中的细微差别,发现隐藏模式,开发新功能并制定建模策略。
5. 模型化
探索性数据分析之后,将进入建模阶段。这个阶段中,会根据特定的机器学习问题,选择不同的算法,而机器学习算法有很多,耳熟能详的有回归、决策树、随机森林等等。
6. 部署与评估
最后,部署开发的模型,并且建立持续的检测机制,观察他们在现实世界中的变现并据此进行校准和优化。
机器学习问题类型
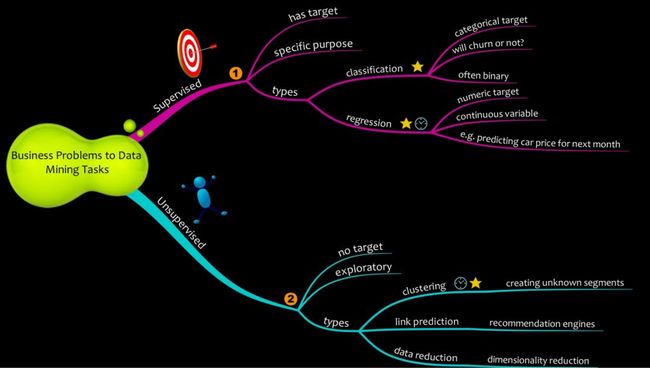
一般情况下,机器学习有两种类型:
监督学习
监督学习是一种机器学习任务,其中有一个明确的目标。从概念上讲,建模者将监督机器学习模型以实现特定目标。监督学习可以进一步分为两类:
回归
回归是机器学习任务中的主力,被用来估计或预测一个数值变量。例如下面两个问题:
下季度的潜在收入估计是多少?
明年我可以关闭多少项交易?
分类
顾名思义,分类模型是将某些东西进行分类,用在离散型变量。分类模型经常用于所有类型的应用程序。分类模型的几个例子是:
垃圾邮件过滤是分类模型的流行实现。在这里,每个传入的电子邮件根据特定的特征被分类为垃圾邮件或非垃圾邮件。
流失预测是分类模型的另一个重要应用。在电信公司广泛使用的流失模型来分类给定的客户是否会流失(即停止使用服务)。
无监督学习
无监督学习是一类没有目标的机器学习任务。由于无监督学习没有任何明确的目标,他们所产生的结果可能有时难以解释。有很多类型的无监督学习任务。几个关键的是:
聚类(Clustering):聚类是将类似的东西组合在一起的过程。客户细分使用聚类方法。
关联(Association):关联是一种查找频繁匹配的产品的方法。零售市场分析使用关联法将产品捆绑在一起。
链接预测(Link Prediction):链接预测用于查找数据项之间的连接。 Facebook,亚马逊和Netflix采用的推荐引擎大量使用链接预测算法来分别向我们推荐朋友,物品和电影。
数据简化(Data Reduction):数据简化方法用于简化从很多特征到几个特征的数据集。它需要一个具有许多属性的大型数据集,并找到用较少属性来表达它们的方法。
机器学习任务到模型到算法
一旦将业务问题分解为机器学习任务,一个或多个算法就可以解决给定的机器学习任务。通常,模型是在多种算法上进行训练的,选择提供最佳结果的算法或一组算法进行部署。
Azure机器学习有超过30种预建算法可用于训练机器学习模型。
结语
数据科学是一个广泛且令人兴奋的领域,而且是一门艺术和科学。这篇文章仅仅是冰山一角。如果“不知道”是什么,那么“如何”将是徒劳的。在随后的文章中,我们将探讨机器学习的“方式方法”。敬请期待!
原作者:Pradeep Menon
原文链接:
https://becominghuman.ai/data-science-simplified-principles-and-process-b06304d63308
译者:TalkingData 张永超