Flink面试题整理,全是干货,自己整理的
-
一,前言
俗话说,金九银十,为了帮助广大同行面试准备,或者帮助想要了解Flink的同学带着问题思考去学习Flink,我先做了一个初步的面试题汇总,这些面试题有些是大家问的比较多的,有些是自己遇到的,有些是在群里面大家问到的问题,可能有的有答案,有的没有答案,如果有大佬或者谁有时间可以补全之后再发出来 ,这个只是抛砖引玉。二,Flink学习资料怎么找~
1,首先作为初学者我建议大家先了解一下官网,官网是最全的API,磨刀不误砍柴工
官网地址:https://flink.apache.org/
为了不动脑子的人,官网也整理了个中文版:
https://flink.apache.org/zh/
2,当有了基础概念之后,可以下载代码动手操作了:
https://github.com/apache/flink
可以练习手写一些案例,不手写代码就能学好的,我没见过,天才除外。
3,这时候你学会了基础,然后又对一些概念或者知识点有疑问,赶紧打开网站:
https://www.bilibili.com/ 搜索 ‘Flink关键字’:
你会看到很多资料,先不要看其他的,点开如下图(看这个up主的视频):
附上官网指定路径:
https://ververica.cn/developers/flink-training-course3/
4,看完这些,你又手痒想写项目代码怎么样,这个时候你可以看看一些培训机构的项目实战视频了,就是spark的电商项目的转化代码,B站上有很多,感兴趣的可以自己看:
5,如果想做一些有意思的项目跟场景而又无处下手怎么办,这是很多想学,想做Flink的朋友的瓶颈,没关系,业务场景都在这里:
https://yq.aliyun.com/articles/691499?spm=a2c4e.11153940.blogcont692364.11.76bf2da5mHGlBB
简单的案例(是不是觉得没那么难~): -
6,公众号: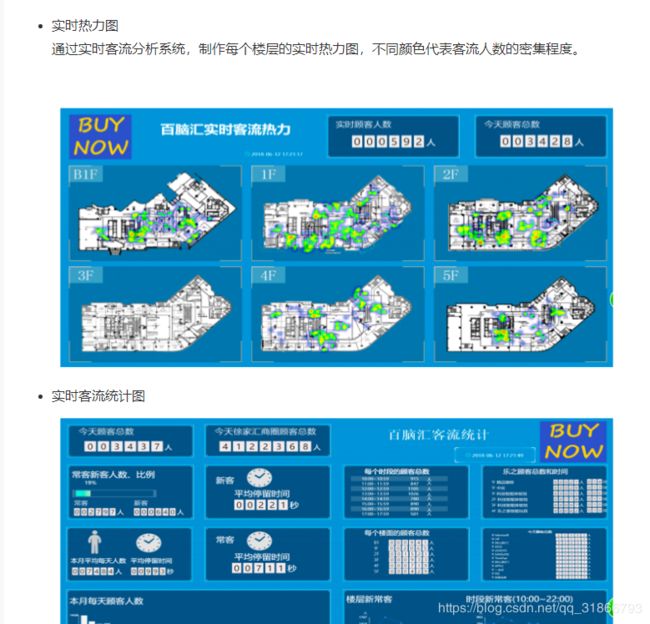

-

-

-
7,在你动手实现这写业务场景的时候肯定会遇到各种问题,毕竟你才开始学习跟开发,遇到问题怎么办???
三,遇到问题怎么去解决~
1,百度:xxxxx
2,Flink有自己的邮件网站 :http://apache-flink.147419.n8.nabble.com/ -
3,Stack Overflow : Committer 们会关注 Stack Overflow 上 apache-flink 相关标签的问题
4,还有具体的方式参考:
https://flink.apache.org/zh/community.html#stack-overflow5,在阿里社区,华为社区,腾讯社区都有相应的模块:
1)https://cloud.tencent.com/developer/search/article-Flink (腾讯)2)https://yq.aliyun.com/teams/67/type_blog-cid_345-page_1?spm=a2c4e.11153959.0.0.26f735e8zAh24a(阿里云)
3)https://www.aboutyun.com/forum.php?mod=forumdisplay&fid=443&orderby=lastpost&filter=lastpost&orderby=lastpost&page=2 (about云)
6,https://segmentfault.com/t/flink 搜索相关答案
7,在钉钉群或者QQ群提问,下面会说。
8,最后提一句啊,有人在一些群里,你问问题,他会说私聊他,找你要红包啥的,别信,在群里回答问题要红包的遇到之后要坚决举报!!!个人非常反感。四,有哪些好的群或者论坛可以去了解学习Flink~
1,有兴趣的可以加入: -
2,
3,
4,钉钉群(交流的很多): -
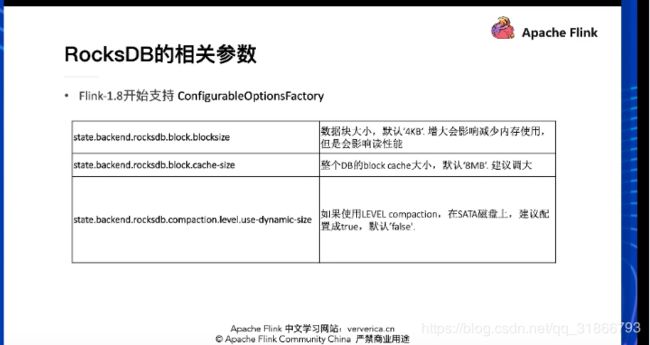
五,问题整理,大部分都是网上找,还有部分是群里实际问题整理,如果有侵权的请提醒,我只是个搬运工~
1,Flink运行一段时候之后报错(生产遇到的问题):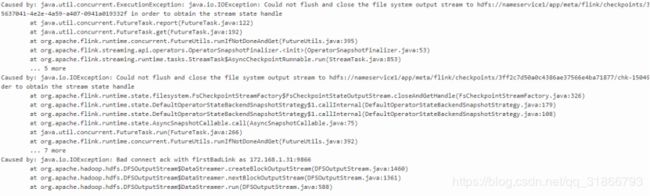
2,运行报错(生产遇到的问题): -
3,flink 怎么在不同作业之间写不同的子目录,这个是哪个参数控制?
4,请问群里有自己实现Flink CEP里面timeEnd算子的吗?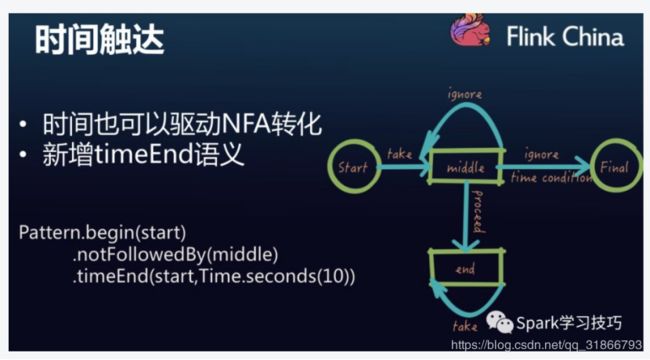
5,cep规则能动态更新吗?
参考答案:改nfa那个类,对上层封装接口,动态加载,替换原来的nfa。6,怎么统计原生数量,spark有个countBykey算子,Flink怎么统计呢?
1)wordCount 都变成 (key,1) 然后sum(1)
2)使用累加器累加7,广播流怎么实现。具体实现步骤,实现哪几个方法?
参考 :
https://mp.weixin.qq.com/s?__biz=Mzg3ODI1NzQ0MA==&mid=2247483655&idx=1&sn=e42be0461899397f121cfaf78f717d94&chksm=cf173548f860bc5eb204d7cc59aa11f98e0fa48f74e3f0410635bdf7d21727f26c0880dbef3f&mpshare=1&scene=23&srcid=#rdhttps://www.jianshu.com/p/c8c99f613f10
8,问个问题,flink消费kafka数据,读字符串的时候怎么指定用avro反序列化 ,还是默认就是,或者是怎么读取Avro的kafka数据。
9,flink输出的文件名,需要根据记录来决定,输出到哪个文件。也就是文件名是动态的。这个要怎么实现呢?根据记录的日期,输出到 yyyy-mm-dd.log 文件?参考官网:https://ci.apache.org/projects/flink/flink-docs-release-1.8/dev/connectors/filesystem_sink.html
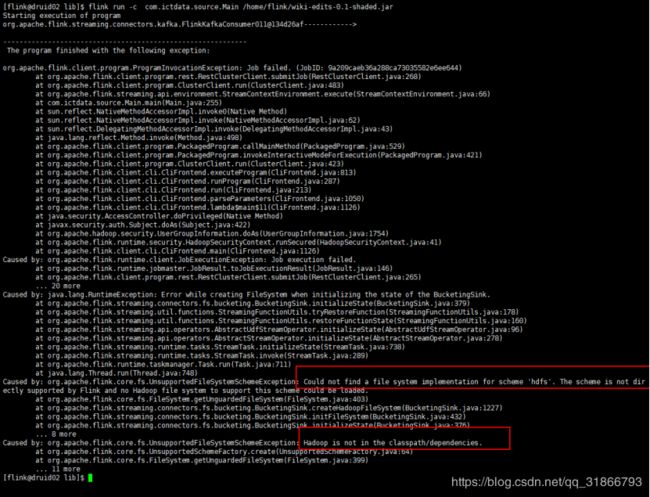
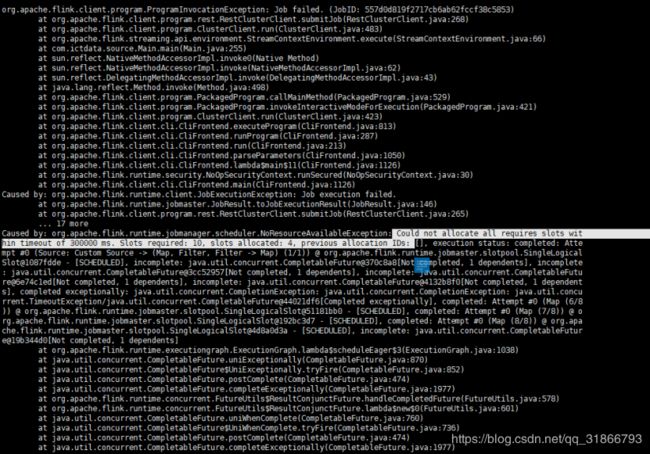
10,集群挂掉错误信息(大部分是taskmamager):
-


-

-
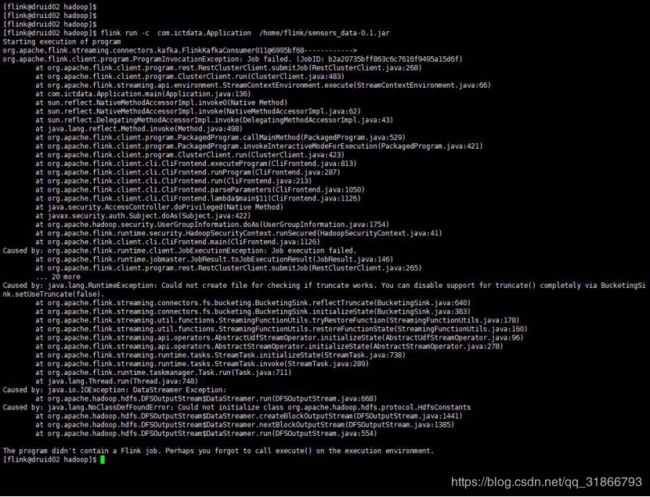
-
-
-
11,RocksDBStateBackend 已经开启增量备份为啥每隔3次就会一次全量?
flink 还是全量的,增量的意思是,checkpoint 文件,增量上传到 hdfs
12,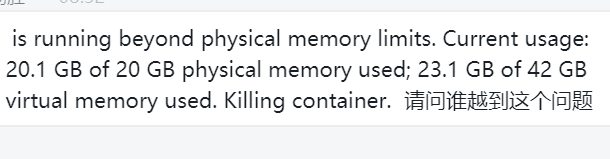
看一下是不是数据倾斜导致的 数据只堆积在一个线程上执行导致的内存不足
13,StreamingFileSink和BucketSink 有什么区别嘛?大部分参数设置都差不多。
bs可以理解成低级api,但是更强大?sfs是封装的高级api,集成了一些外部系统做了适配
有个大佬说 StreamingFileSink 是社区优化后推出的
14,问flink elastic search插入速度慢,导致kafka消息积压。这个怎么处理,es sink有异步插入这种配置吗15,有实现了写hdfs orc sink了么 ?
1.9 版本实现了
16, flink怎么批量查询hbase 或者类似的数据库:
https://ci.apache.org/projects/flink/flink-docs-release-1.7/dev/stream/operators/asyncio.html#the-need-for-asynchronous-io-operations异步查询,将结果放到队列或者kafka 啥的。
不是很懂。。。。
https://www.cnblogs.com/Springmoon-venn/p/11103558.html或者 Flink 自定义 connector
17,flink怎么通过rest api 重启一个job
参考:
https://blog.csdn.net/qq_27710549/article/details/80500857https://ci.apache.org/projects/flink/flink-docs-stable/monitoring/rest_api.html
18,想请问一下大家单个slot分配多大得资源啊
看数据量,看并行度。 -
19,.
用滑动窗口+redis来实现的
20,flink sink到hdfs,用BucketingSink还是StreamingFileSink好? 类似Flink写入 HDFS的问题出现过很多次了,重点要搞明白的,BucketingSink方式好一些。21,离线JDBC支持update吗,总是报语法错误
正确方式:
22, 请教大佬,flink StreamingSink 写入 hdfs,使用parquet格式。需要引入什么包嘛?
可能需要引入
https://yq.aliyun.com/ask/477987
https://www.e-learn.cn/content/wangluowenzhang/75642223,
请问一下,我想设置rocksdb到ssd盘上提高速度,希望通过localdir配置,配置是这样的:但是没有效果,还是会打印到类似于这种路径
/data/hadoop/yarn/local/usercache/hadoop/appcache/application_1563262803562_0170/
24,关于 状态存储,是否会存在时间过期,过期state是否会自动清除?怎么实现手动清除? Flink1.8 版本对state做了哪些改变?https://mp.weixin.qq.com/s/u6vmpcY673ZjkArBqETGHA
25,Flink CEP https://blog.51cto.com/1196740/2361712
25,Flink 的JOIN INTERVAL 了解吗?实现简单下订单跟付款超时SQL?26,怎么阅读Flink源码,你有阅读过Flink源码吗?说说你看过哪些部分。
27,
State你不设置TTL怎么会自动清除状态,除非你自己手动实现,1.8版本的更新不是默认自动清除State数据,只是对TTL做了一个性能上的优化,使TTL运作起来更有效率,不想清理不设置不就完了,默认就是没有开启的,状态就会一直累加28,任务的调度与执行过程:
29,Task slot是什么?
Task slot是一个TaskManager内资源分配的最小载体,代表了一个固定大小的资源子集,每个TaskManager会将其所占有的资源平分给它的slot。
通过调整 task slot 的数量,用户可以定义task之间是如何相互隔离的。每个 TaskManager 有一个slot,也就意味着每个task运行在独立的 JVM 中。每个 TaskManager 有多个slot的话,也就是说多个task运行在同一个JVM中。
而在同一个JVM进程中的task,可以共享TCP连接(基于多路复用)和心跳消息,可以减少数据的网络传输,也能共享一些数据结构,一定程度上减少了每个task的消耗30,Flink – SlotSharingGroup
怎么理解跟解释。怎么判断operator属于哪个 slot 共享组呢?默认情况下,所有的operator都属于默认的共享组default,也就是说默认情况下所有的operator都是可以共享一个slot的。而当所有input operators具有相同的slot共享组时,该operator会继承这个共享组。最后,为了防止不合理的共享,用户也能通过API来强制指定operator的共享组,比如:someStream.filter(...).slotSharingGroup("group1");就强制指定了filter的slot共享组为group1。
31,Flink Rich 函数 open 方法 是每来一条数据 执行一次还是怎么执行?
open 方法是每个并发线程执行一次,一般用来初始化,而不是每条数据都执行一次。
32,Flink HA部署, Flink on Yarn搭建,这个~对新手可能会问一下,百度都有。33,Flink 怎么设置jvm的参数,对应哪些参数
34,Flink rebalance算子使用?怎么看数据倾斜?
35,使用mapstate保存中间状态时,checkpoint会把缓存清空,不清楚怎么回事,有大佬了解么?
36,在flink遇到性能瓶颈,如何查看是哪个算子卡住了呢?
查看web UI :
37,请问,流处理多流join如何保证流之间的数据同步?38,怎么看反压,就是数据积压?
job页面有backpress..
39,使用 flink-parquet 包 中 ParquetAvroWriters 类 将 bean 的 json数据 写入hdfs 中,发现 bean 的字段值为 null 的时候,写数据会报错 java.lang.RuntimeException: Null-value for required field ,请问 这怎么解决?40,State参数调优:
-
-

-
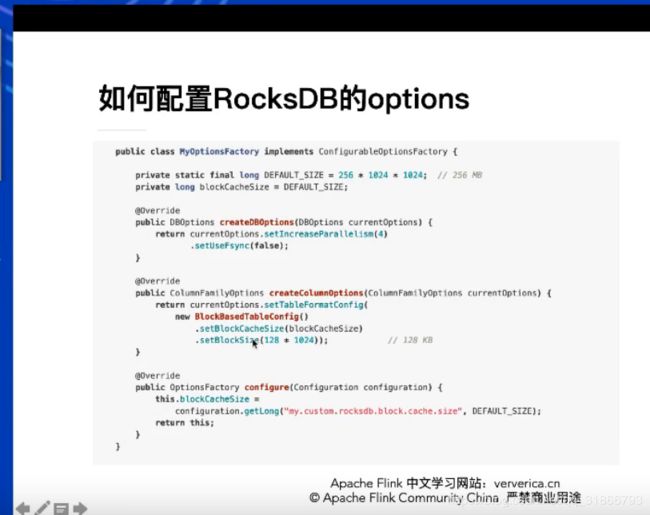

41,实现业务,2秒触发一次,取topN ,下图代码不对,供参考
42,https://github.com/hiliuxg/example/blob/master/src/test/java/com/hiliuxg/example/todaywindow/TodayWindowAssignersTest.java
案例代码 经常会遇到的统计每天凌晨开始的数据类型总数:
package com.hiliuxg.example.todaywindow;import com.hiliuxg.example.todaywindows.TodayEventTimeWindows;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.junit.Test;
import java.text.SimpleDateFormat;
import java.util.HashMap;
import java.util.Map;public class TodayWindowAssignersTest {
/**
* 每个一分钟,计算用户从0晨到当前时间访问某个网页链接的PV和UV
* @throws Exception
*/
@Test
public void testTodayPVUV() throws Exception {SimpleDateFormat sf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss") ;
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.setParallelism(1);DataStream
.map(new MapFunction
@Override
public Tuple3
String[] input = value.split(",") ;
Long timestamp = sf.parse(input[0]).getTime() ; //获取访问的当前时间
Long userId = Long.parseLong(input[1]) ; //获取用户ID
String link =input[2] ; //网页链接
return Tuple3.of(timestamp,userId,link) ;
}
}) //分配watermark,最多迟到5秒
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor
@Override
public long extractTimestamp(Tuple3
return element.f0;
}
});//计算PV和UV,TodayEventTimeWindows这窗口,定义了0晨到当前时间的窗口
ds.keyBy(2).window(TodayEventTimeWindows.of(Time.minutes(1)))
.apply(new WindowFunction
@Override
public void apply(Tuple tuple, TimeWindow window, Iterable
Map
final int[] pv = {0};
input.forEach(item -> {
uv.put(item.f1,1L);
pv[0]++;
});out.collect(Tuple4.of(sf.format(window.getEnd()),tuple.getField(0),uv.size(), pv[0]));
}
}).addSink(new SinkFunction
@Override
public void invoke(Tuple4
System.out.println(value);
}
});env.execute();
}}
43,ProcessWindowFunction一次性迭代整个窗口里的所有元素 。该算子会浪费很多性能吧,主要原因是不增量计算,要缓存整个窗口然后再去处理,所以要设计好内存。
参考文章:https://blog.csdn.net/rlnLo2pNEfx9c/article/details/88266230
有些小伙伴在写代码发现cpu 内存使用很多,就是因为使用了这个算子,可以进行业务代码算子优化,比如使用增量算子 reduce等等
44,我设置了一个24小时的窗口 然后发现差了8小时 请问应该如何设置时区 ?
.windowAll(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))45,flink如何动态更改window的时间?
46,
请问,Flink里面用druid数据源,遇到SqlSessionTemplate不可序列化,大家是怎么解决的?47, 这运行不到2个小时 taskmanager就死掉了,然后把job杀掉了
增大tm的心跳超时时间
-
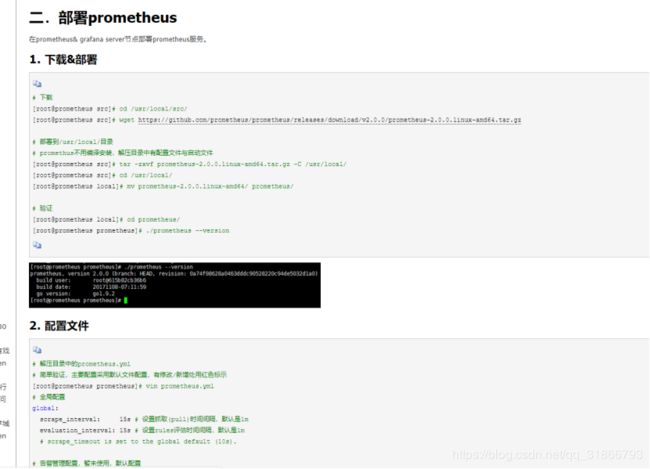
48,Flink 怎么添加监控,类似下图: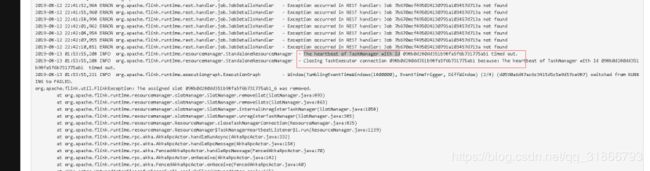
-
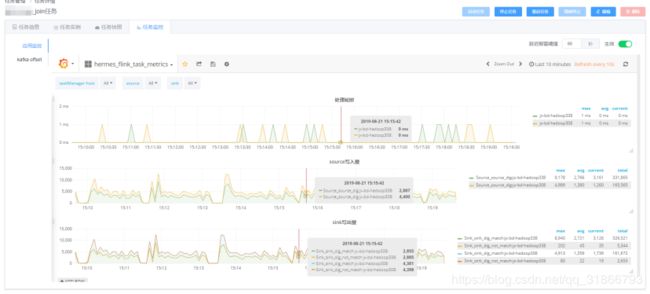
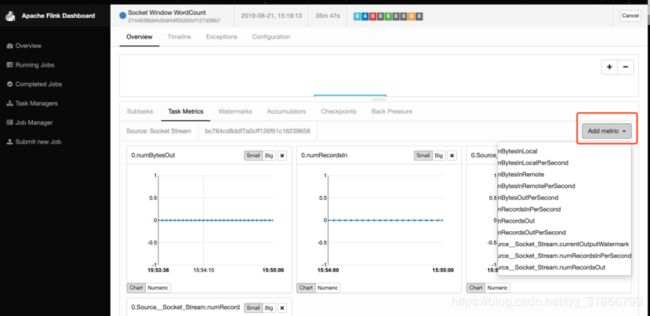
-
-
49,邮件地址
Apache Flink 中文用户邮件列表 | Mailing List ArchiveApache Flink 中文用户邮件列表 forum and mailing list archive. Apache Flink 中文用户邮件列表
http://apache-flink.147419.n8.nabble.com/
-
50,监控
-
51,Flink 1.9 结合 Hive
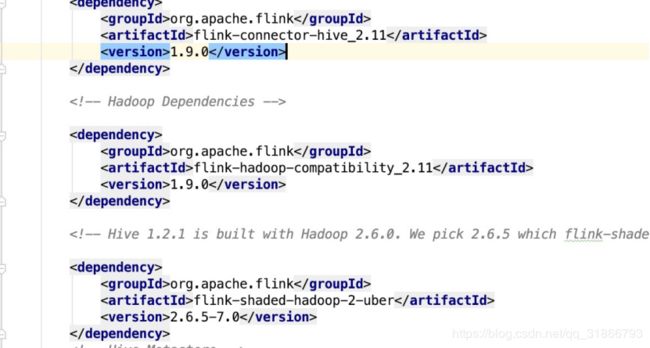
52,简诉Flink 1.9新特性 :
1,代码提交了巨大,改动非常多
2,支持hive读写,支持UDF,不过写很简单,还在优化阶段
3,SQL优化了,更强大
4,Checkpoint跟savepoint针对实际业务场景做了优化(大家都知道 Flink 会周期性的进行 Checkpoint,并且维护了一个全局的状态快照。假如我们碰到这种场景:用户在两个Checkpoint 周期中间主动暂停了作业,然后过一会又进行重启。这样,Flink 会自动读取上一次成功保存的全局状态快照,并开始计算上一次全局快照之后的数据。虽然这么做能保证状态数据的不多不少,但是输出到 Sink 的却已经有重复数据了。有了这个功能之后,Flink 会在暂停作业的同时做一次全局快照,并存储到Savepoint。下次启动时,会从这个 Savepoint 启动作业,这样 Sink 就不会收到预期外的重复数据了。不过,这个做法并不能解决作业在运行过程中自动Failover而引起的输出到 Sink 数据重复问题)
5,可以查询state了,这是很多开发者有需要的地方:
53,checkpoint目录下面有很多 chk-* 文件,有配置可以只留最近的几个么?太占空间
解决方法:配置里有一个 retain。54,Flink追加写入不同的hdfs文件,按key 或者时间日期怎么实现?
https://www.jianshu.com/p/a5308d7f3463
55,在Kafka 集群中怎么指定读取/写入数据到指定broker或从指定broker的offset开始消费?
Kafka知道API :
Map
offsets.put(new KafkaTopicPartition("dianyou_wxgz2", 0), 17578582L);
// //todo 指定输入数据为kafka topic
DataStreamkafkaDstream = env.addSource(new FlinkKafkaConsumer010 (
"topic_filter",
pros).setStartFromSpecificOffsets(offsets)).setParallelism(6);
56,flink中watermark究竟是如何生成的,生成的规则是什么,怎么用来处理乱序数据?
看这里,下面的文章讲的最好了:
https://blog.csdn.net/lmalds/article/details/5270417057,消费kafka数据的时候,如果遇到了脏数据,或者是不符合规则的数据等等怎么处理呢?
先做filter过滤算子呗,不符合要求的过滤或者缓存到哪里57,flink jar包上传至集群上运行,挂掉后,挂掉期间kafka中未被消费的数据,在重新启动程序后,是自动从checkpoint获取挂掉之前的kafka offset位置,自动消费之前的数据进行处理,还是需要某些手动的操作呢?
明白一点,Flink+kafka 不需要我们去报错offset了,它会自动checkpoint58,Flink jobManager跟 taskManager内存大小设置多少比较好 ?
这个没有标准答案,看你的数据量跟业务处理,因为数据量大的话 你使用有状态的算子多,而且状态多的话,会吃内存,taskmanager 一般4G起步,如果日志报内存不足 或者GC问题,要代码业务调优,加大内存资源。59,taskManager Slot core的关系?
taskManager 里面有一个或者多个slot,一个slot有一个或者多个core,默认都是1个,需要调整的。60,flink的Python api怎样?bug多吗?
哈哈哈哈,有朋友在使用python开发,可以用,但是部分算子 API不一样。61,Flink VS Spark VS Storm ??
Storm淘汰掉把。Spark离线处理,ML目前还是主流,Flink两者特点都有,干就完事了 。62,使用了ValueState来保存中间状态,在运行时中间状态保存正常,但是在手动停止后,再重新运行,发现中间状态值没有了,之前出现的键值是从0开始计数的,这是为什么?是需要实现CheckpointedFunction吗?
典型的没有理解state存储 ,state存储是在内存的 是通过checkpoint异步存储到磁盘或者hdfs,肯定要开启checkpoint的。63,Flink 1.9.0 ,flink-table_${scala_bin_version}这个artifact变成flink-table了,而且下载不到jar,我上central的repository看了,从1.7.2以上的版本,flink-table都缺少jar,哪位已经用起来1.9.0了,指点一下?
答:1.8之后就不再有flink-table的jar包了,都是用这个planner和common包
org.apache.flink
flink-table-planner_2.11
1.9.0
64,Flink 1.9写入 hbase ?
CREATE TABLE hbase_sink (
row_key VARCHAR,
family ROW
) WITH (
'connector.type' = 'hbase',
'connector.version' = '1.4.3',
'connector.property-version' = '1',
'connector.table-name' = 'test2',
'connector.zookeeper.quorum' = 'fjr-yz-0-134:2181',
'connector.zookeeper.znode.parent' = '/hbase'
);65,各位,flink interval join使用rocksdb做状态存储,发现checkpoint中shared不断增大,不过期是什么原因?
-
66,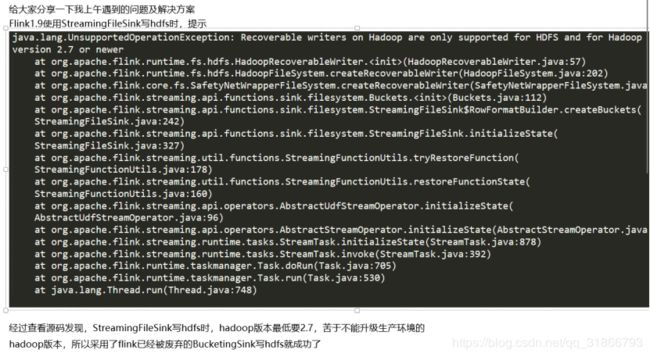
67,重要|flink的时间及时区问题解决
https://blog.csdn.net/rlnLo2pNEfx9c/article/details/91915550
https://www.cnblogs.com/liugh/p/8404706.html68,

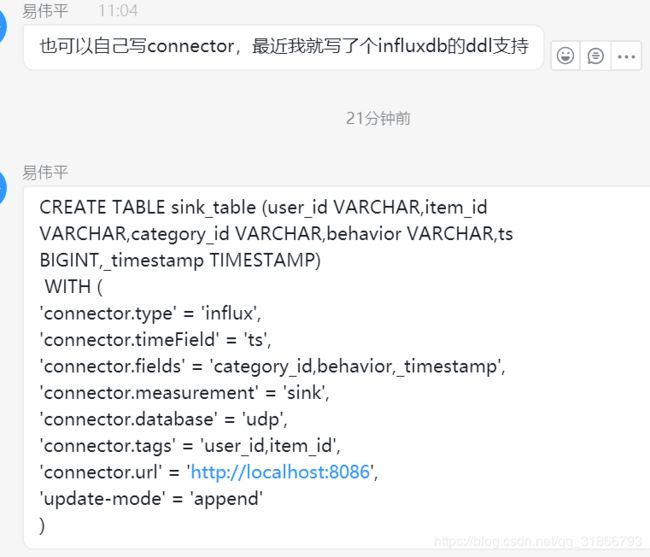
-
未完待续,.......................
-
-
-
-
六,一些基础点要懂的。
七,备份,补充:
如何在 Flink 1.9 中使用 Hive?
http://1t.click/TmE
Flink SQL 编程实践
http://1t.click/KZV
Flink 和 Prometheus:流式应用程序的云原生监控
http://1t.click/TjT