评分卡开发流程全解析---python版
一、背景
从去年暑假到今年2月份曾在两家互金公司实习,接触了很多金融信贷场景下的知识,其中最基础的当属评分卡的开发了。接下来将结合我在实习中的工作讲一下评分卡的开发全流程,有兴趣的童鞋可以看一下,有任何不对的地方希望大家批评指正。
二、正文
首先评分卡的开发流程大致包含下面这些步骤:
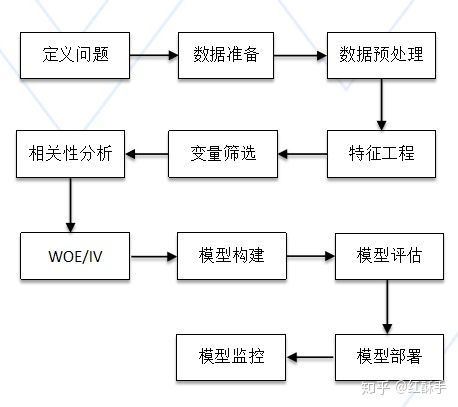
(一)定义问题
确定两类重要的问题:观察期和表现期、好坏客户的定义。
观察期相当于X变量,即搜集用户的行为;表现期相当于Y变量,即用户的表现,在评分卡中通常就是好坏两类。观察期从观察时点起向前回溯的最远时长,表现期从观察时点起根据账龄分析来决定。
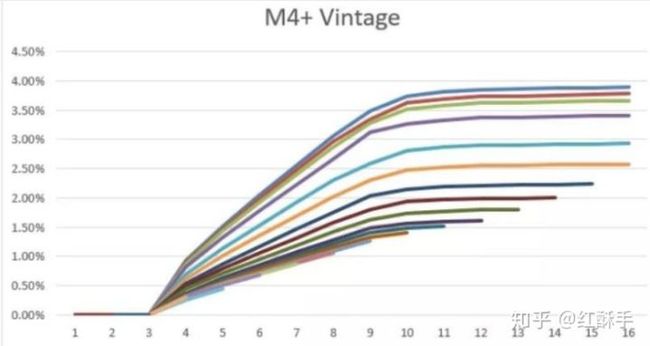
从图中可看出,在9个月以后的坏账率趋于稳定,说明坏客户重复暴露的时间为9个月,那么就定义表现期为9个月。
好坏客户通过滚动率和迁移率来分析。滚动率分析就是从某个观察点之前的一段时间(称为观察期)的最坏的状态向观察点之后的一段时间(称为表现期)的最坏状态的发展变化情况,如下所示:
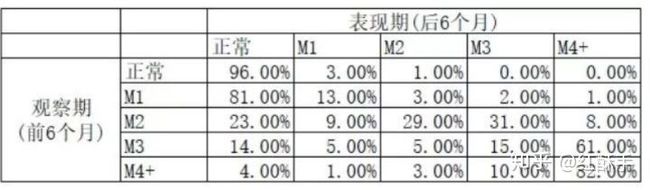
从上看出,在观察期正常还款的在表现期还正常还款的概率为96%,在观察期逾期3个月的客户在表现期逾期4个月的概率为61%,说明M3的用户有很大概率会更坏变为M4,故定义M3为坏客户,即逾期60-90的人。
(二)数据准备和预处理
贯穿全文的包---scorecardpy
根据定义的观察期和表现期拉取数据,预处理主要是对异常值、缺失值,有些情况还需要特征缩放即归一化和标准化处理,比如时间和金额等等和其他字段的取值相差很大时,可以利用已有的方法也可以自定义,如下所示:
#相当于数据预处理, 设定要删除的规则,主要是指缺失率,iv<0.02等等
dt_s = sc.var_filter(data, y="flagy")
print("变量预处理前后变化:",data.shape[1],"->",dt_s.shape[1])(三)特征工程
可以从数据来源、业务类型、时间范围和统计单位4个维度来衍生,将4个维度作笛卡尔积交叉组合特征。
除此之外维度指标有频次(近3个月的f贷款申请次数)、总和、平均、占比、一致性(身份证和手机号所在的省份是否一致)、距离、波动、占比趋势和对比趋势等。还有一些可以结合具体的业务来,如在信用卡业务中对于还款有近1、3、6、12、24个月的还款次数、最大单笔还款距今时长、最后一次还款距今时长等等。
(四)变量筛选
在评分卡中由于需要业务具有很强的解释性,通常入模的变量为8~16个,需要筛选变量。变量筛选的方式有以下几种:
- 如果不使用预测模型,有监督的可以使用信息值、卡方统计量和gini系数;无监督的可以使用相关性、聚类和PCA等
- 若使用预测模型,可以使用逐步回归、正则化(AIB,BIC,lasso)、交叉验证和机器学习如xgb等自带筛选特征,在经过预处理后保留下来的变量有707个,故必须要筛选变量,采用了两种方法lasso和xgb,xgb的方法如下:
# 进行Xgboost之前需要处理数据,要预先处理数据 都要转化成float类型,而且要没有缺失值
import re
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split
def float_1(x):
try:
return float(x)
except:
return np.nan
y = dt_s['flagy']
col = set(dt_s.columns)
X = dt_s.ix[:, [x for x in col if not re.search('flagy', x)]]
X = X.applymap(float_1)
X = X.astype(np.float)
X = X.fillna(0)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=10)选择合适的参数
import xgboost as xgb
dtrain = xgb.DMatrix(X_train, y_train)
params={
'booster':'gbtree',
'objective': 'binary:logistic',
'eval_metric': 'auc',
'max_depth': 3,
'lambda': 5,
'subsample': 0.8,
'colsample_bytree': 0.8,
'min_child_weight': 20,
'eta': 0.025,
'nthread': 8
}
# 交叉验证选出test-auc-mean最高时对应的迭代次数
cv_log = xgb.cv(params,dtrain,num_boost_round=500,
nfold=5,
metrics='auc',
early_stopping_rounds=10)
bst_auc = cv_log['test-auc-mean'].max()
cv_log['nb'] = cv_log.index
cv_log.index = cv_log['test-auc-mean']
nround = cv_log.nb.to_dict()[bst_auc]lasso方法如下:
# 交叉验证拟合Lasso模型
from sklearn.linear_model import LassoCV
lassocv = LassoCV()
lassocv.fit(X,y)
# 交叉验证选择的参数alpha
print(lassocv.alpha_)
# 最终Lasso模型中的变量系数
print(lassocv.coef_[:10])
# Lasso细筛出的变量个数
print(np.sum(lassocv.coef_ > 0))然后可以将两者的特征交集作为初步的变量。
#将两种方法取交集,得到的变量入模
features_chosen = ['pc_rcnt_income', 'location_cell_stab', 'location_cell_use_days',
'als_m6_id_nbank_cons_allnum', 'ir_id_x_cell_notmat_days',
'pc_business_type', 'als_m12_id_caoff_orgnum', 'pc_noincome_lst_mons',
'stab_mail_num', 'pc_long_income', 'als_m12_id_cooff_orgnum',
'pc_mobile_cons', 'pc_regincome_sta', 'als_fst_cell_nbank_inteday',
'location_online_fre', 'als_m6_cell_nbank_p2p_allnum',
'als_m6_cell_bank_min_inteday', 'als_m12_id_nbank_max_inteday',
'location_id_attr', 'als_m12_cell_nbank_nsloan_allnum',
'cons_max_m12_pay', 'cons_tot_m3_visits', 'cons_tot_m3_pay', 'als_m12_id_nbank_allnum'
](五)相关性分析
可以利用皮尔森相关系数>0.7,和方差扩大因子vif>3来筛选变量。
#将vif>3的去掉,statsmodels不允许有缺失值
col = np.array(data[features_chosen])
from statsmodels.stats.outliers_influence import variance_inflation_factor as vif
data[features_chosen] = data[features_chosen].fillna(0)
for i in range(len(features_chosen)):
print('{} VIF是{}'.format(features_chosen[i],vif(col,i)))(六)WOE/IV
在计算WOE和IV值之前先要划分训练集、测试集和跨时间验证样本,比例为5:2:3,接下来是分箱,分箱应该在训练集上而不是整个数据上,因为如果在整个数据集上先分箱,然后再用其中的一部分作为测试集,将会导致过拟合。
dt_var = data[features_chosen]
dt_var['flagy'] = data['flagy']
train, test = sc.split_df(dt_var,'flagy').values()
print("训练集、测试集划分比例为",train.shape[0],":",test.shape[0])然后接下来分箱
#bins是对训练集作的分箱
bins_train = sc.woebin(train, y="flagy",save_breaks_list=True)
#测试集以在训练集上分箱的情况作为标准
bins_test = sc.woebin(test, y="flagy",breaks_list=breaks_list)
train_woe = sc.woebin_ply(train, bins_train)
test_woe = sc.woebin_ply(test, bins_test)
y_train = train_woe.loc[:,'flagy']
X_train = train_woe.loc[:,train_woe.columns != 'flagy']
y_test = test_woe.loc[:,'flagy']
X_test = test_woe.loc[:,train_woe.columns != 'flagy']
X_train.to_csv('X_train_final.csv',index=False,sep=',',header=None)
y_train.to_csv('y_train_final.csv',index=False,sep=',',header=None)计算的IV值
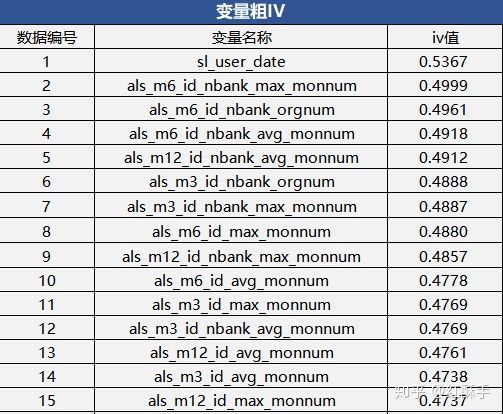
分箱的结果,对于非单调的可以手动分箱:
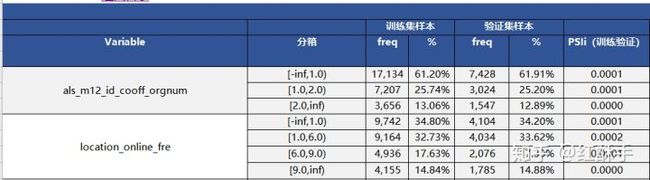
(七)模型构建
用到LR和LightGBM,部分代码如下:
LR代码:
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
#需要调优的参数
penaltys = ['l1','l2']
Cs = [0.001, 0.01, 0.1, 1, 10, 100, 1000]
tuned_parameters = dict(penalty = penaltys, C = Cs)
lr_penalty= LogisticRegression()
# GridSearchCV(estimator, param_grid, ... cv=None, ...)
# estimator: 模型, param_grid:字典类型的参数, cv:k折交叉验证
grid= GridSearchCV(lr_penalty, tuned_parameters, cv=5)
grid.fit(X_train,y_train) # 网格搜索训练
grid.cv_results_ #训练的结果
# examine the best model
print(grid.best_score_) # 最好的分数
print(grid.best_params_) # 最好的参数
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(penalty='l1',C=0.1,solver='saga',n_jobs=-1)
lr.fit(X_train,y_train)对于变量还要计算其显著性,如P值、Z值,然后将P>|Z|的变量去掉
from scipy import stats
def stat_model(x, y, y_pred, const, coef):
'''
'''
x = x.copy()
x.reset_index(drop=True,inplace=True)
y = y.copy()
y.reset_index(drop=True,inplace=True)
newX = pd.DataFrame({"Constant": np.ones(len(x))}).join(pd.DataFrame(x))
MSE = (sum((y - y_pred)**2))/(len(newX)-len(newX.columns))#分母应该是N
params = np.append(const,coef)
var_b = MSE*(np.linalg.inv(np.dot(newX.T,newX)).diagonal())
st_error = np.sqrt(var_b)
t_v = params/st_error
p_values = [2*(1-stats.t.cdf(np.abs(i),len(newX)-1)) for i in t_v]
result = pd.DataFrame({'Coefficients':params,
'Standard Errors':st_error,
't values':t_v,
'P_values':p_values}) \
.apply(lambda x: round(x,3)) \
.assign(Variable = newX.columns.tolist())
return result
#intercept_是截距,coef_是训练后的输入端模型系数,如果label有两个,即y值有两列。
summary = stat_model(X_train,y_train,train_pred,lr.intercept_,lr.coef_)
summary[['Variable','Coefficients','P_values']]
#得到的constant是截距项,不用管
LightGBM代码(找不到了...):

(八)模型评估
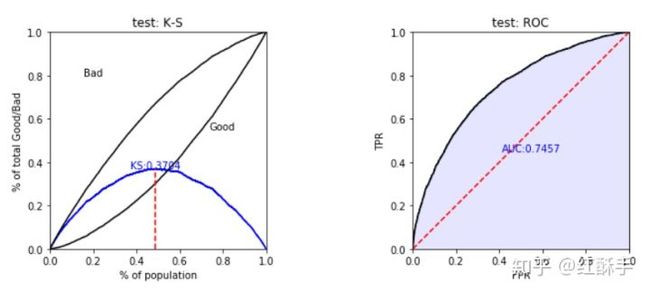
模型评估使用ks、auc和psi来评价
train_perf = sc.perf_eva(y_train, train_pred, title = "train")
test_perf = sc.perf_eva(y_test, test_pred, title = "test")
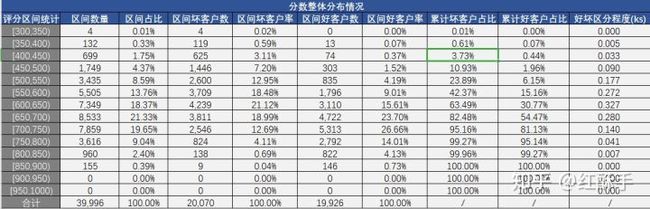
最终模型的分值分布如下:

(九)模型部署
在风控后台上配置模型规则,对于复杂的模型还需要将模型文件作转换,封装成类,由其他代码来调用
(十)模型监控
前期主要监控模型的稳定性psi,变量的psi,也要比较模型每日的拒绝率和线下拒绝率
后期等到用户有一定表现后可以用auc、ks和iv等来对比线上和线下的区别。
三、结语
在互金实习了两段,最终还是选择了互联网,这也是对自己实习部分工作的回顾和总结。评分卡建模流程基本如上,欢迎大家指正交流。