- PyTorch 深度学习实战(19):离线强化学习与 Conservative Q-Learning (CQL) 算法
进取星辰
PyTorch深度学习实战深度学习pytorch算法
在上一篇文章中,我们探讨了分布式强化学习与IMPALA算法,展示了如何通过并行化训练提升强化学习的效率。本文将聚焦离线强化学习(OfflineRL)这一新兴方向,并实现ConservativeQ-Learning(CQL)算法,利用Minari提供的静态数据集训练安全的强化学习策略。一、离线强化学习与CQL原理1.离线强化学习的特点无需环境交互:直接从预收集的静态数据集学习数据效率高:复用历史经验
- 一切皆是映射:DQN训练加速技术:分布式训练与GPU并行
AI天才研究院
计算AI大模型企业级应用开发实战ChatGPT计算科学神经计算深度学习神经网络大数据人工智能大型语言模型AIAGILLMJavaPython架构设计AgentRPA
1.背景介绍1.1深度强化学习的兴起近年来,深度强化学习(DeepReinforcementLearning,DRL)在游戏、机器人控制、自然语言处理等领域取得了令人瞩目的成就。作为一种结合深度学习和强化学习的强大技术,DRL能够使智能体在与环境交互的过程中学习最优策略,从而实现自主决策和控制。1.2DQN算法及其局限性深度Q网络(DeepQ-Network,DQN)是DRL的一种经典算法,它利用
- 实战LLM强化学习——使用GRPO(DeepSeek R1出圈算法)
大富大贵7
程序员知识储备1程序员知识储备2程序员知识储备3经验分享
引言近年来,深度强化学习(DRL)已经成为解决复杂决策问题的一个强有力工具,尤其是在自然语言处理(NLP)领域的广泛应用。通过不断优化决策策略,DRL能在大量数据中学习最佳行为,尤其是大型语言模型(LLM)在任务中展现出的巨大潜力。然而,随着模型规模的扩大和任务复杂性的增加,传统的强化学习算法开始暴露出训练效率低、收敛速度慢等问题。为了解决这些挑战,DeepSeek公司提出了一个新的强化学习算法—
- Ai时代初期全球不同纬度的层级辐射现象
龙胥伯
人工智能
基于最新研究成果与行业动态,AI时代的"层级辐射"现象可被科学解构为以下六大维度,结合技术演进、产业实践和社会影响进行系统性分析:一、技术能力的层级跃迁模型效率革命DeepSeek研发的R1-Zero模型通过动态架构设计,将样本利用率提升40%以上,训练周期大幅缩短。这种技术突破推动AI从实验室走向规模化应用,在智能制造、生物医药等领域催生新生态。大语言模型的训练方式(预训练→多任务学习→强化学习
- PyTorch 深度学习实战(12):Actor-Critic 算法与策略优化
进取星辰
PyTorch深度学习实战深度学习pytorch算法
在上一篇文章中,我们介绍了强化学习的基本概念,并使用深度Q网络(DQN)解决了CartPole问题。本文将深入探讨Actor-Critic算法,这是一种结合了策略梯度(PolicyGradient)和值函数(ValueFunction)的强化学习方法。我们将使用PyTorch实现Actor-Critic算法,并应用于经典的CartPole问题。一、Actor-Critic算法基础Actor-Cri
- PyTorch 深度学习实战(17):Asynchronous Advantage Actor-Critic (A3C) 算法与并行训练
进取星辰
PyTorch深度学习实战深度学习pytorch算法
在上一篇文章中,我们深入探讨了SoftActor-Critic(SAC)算法及其在平衡探索与利用方面的优势。本文将介绍强化学习领域的重要里程碑——AsynchronousAdvantageActor-Critic(A3C)算法,并展示如何利用PyTorch实现并行化训练来加速学习过程。一、A3C算法原理A3C算法由DeepMind于2016年提出,通过异步并行的多个智能体(Worker)与环境交互
- DeepSeek在智慧物流管控中的全场景落地方案
猴的哥儿
笔记大数据交通物流python数据仓库微服务
一、智慧物流核心痛点与DeepSeek解决方案矩阵物流环节行业痛点DeepSeek技术方案价值增益仓储管理库存预测误差率>30%多模态时空预测模型库存周转率↑40%运输调度车辆空驶率35%强化学习动态调度引擎运输成本↓25%路径规划突发路况响应延迟>30分钟实时路况语义理解+自适应规划准时交付率↑18%异常检测50%异常依赖人工发现多传感器融合的异常模式识别异常发现时效↑6倍客户服务50%咨询需人
- 探索DeepSeek:前端开发者不可错过的新一代AI技术实践指南
formerlyai
人工智能前端
引言:为什么DeepSeek成为技术圈焦点?最近,国产AI模型DeepSeek凭借其低成本训练、高性能输出和开源策略,迅速成为开发者社区的热门话题。作为覆盖语言、代码、视觉的多模态技术矩阵,DeepSeek不仅实现了与ChatGPT相媲美的能力,还通过强化学习驱动的架构创新,解决了大模型落地中的成本与效率瓶颈。对于前端开发者而言,DeepSeek的API接入能力和私有化部署方案,为智能应用开发提供
- 【sklearn 02】监督学习、非监督下学习、强化学习
@金色海岸
sklearn学习人工智能
监督学习、非监督学习、强化学习**机器学习通常分为无监督学习、监督学习和强化学习三类。-第一类:无监督学习(unsupervisedlearning),指的是从信息出发自动寻找规律,分析数据的结构,常见的无监督学习任务有聚类、降维、密度估计、关联分析等。-第二类:监督学习(supervisedlearning),监督学习指的是使用带标签的数据去训练模型,并预测未知数据的标签。监督学习有两种,当预测
- 【人工智能基础2】机器学习、深度学习总结
roman_日积跬步-终至千里
人工智能习题人工智能机器学习深度学习
文章目录一、人工智能关键技术二、机器学习基础1.监督、无监督、半监督学习2.损失函数:四种损失函数3.泛化与交叉验证4.过拟合与欠拟合5.正则化6.支持向量机三、深度学习基础1、概念与原理2、学习方式3、多层神经网络训练方法一、人工智能关键技术领域基础原理与逻辑机器学习机器学习基于数据,研究从观测数据出发寻找规律,利用这些规律对未来数据进行预测。基于学习模式,机器学习可以分为监督、无监督、强化学习
- 从过拟合到强化学习:机器学习核心知识全解析
吴师兄大模型
0基础实现机器学习入门到精通机器学习人工智能过拟合强化学习pythonLLMscikit-learn
Langchain系列文章目录01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南02-玩转LangChainMemory模块:四种记忆类型详解及应用场景全覆盖03-全面掌握LangChain:从核心链条构建到动态任务分配的实战指南04-玩转LangChain:从文档加载到高效问答系统构建的全程实战05-玩转LangChain:深度评估问答系统的三种高效方法(示例生成、手
- 基于DeepSeek R1构建下一代Manus通用型AI智能体的技术实践
zhangjiaofa
DeepSeekR1&AI人工智能大模型DeepSeekManus智能体AI
目录一、技术背景与目标定位1.1大模型推理能力演进趋势1.2DeepSeekR1核心特性解析-混合专家架构(MoE)优化-组相对策略优化(GRPO)原理-多阶段强化学习训练范式1.3Manus智能体框架设计理念-多智能体协作机制-安全执行沙箱设计二、系统架构设计2.1整体架构拓扑图-分层模块交互机制-数据流与控制流设计2.2核心组件实现-规划模块(GRPO算法集成)-记忆系统分级存储架构-工具调用
- 强化学习:时间差分(TD)(SARSA算法和Q-Learning算法)(看不懂算我输专栏)——手把手教你入门强化学习(六)
wxchyy
强化学习算法
目录前言前期回顾一、SARSA算法二、Q-Learning算法三、总结总结前言 前两期我们介绍了动态规划算法,还有蒙特卡洛算法,不过它们对于状态价值函数的估值都有其缺陷性,像动态规划,需要从最下面向上进行递推,而蒙特克洛则需要一个Episode(回合)结束才能对其进行估值,有没有更直接的方法,智能体能边做动作,边估值一次,不断学习策略?答案是有的。这就是本期需要介绍的算法,时间差分法(TimeDi
- 大型语言模型与强化学习的融合:迈向通用人工智能的新范式——基于基础复现的实验平台构建
(initial)
大模型科普人工智能强化学习
1.引言大型语言模型(LLM)在自然语言处理领域的突破,展现了强大的知识存储、推理和生成能力,为人工智能带来了新的可能性。强化学习(RL)作为一种通过与环境交互学习最优策略的方法,在智能体训练中发挥着重要作用。本文旨在探索LLM与RL的深度融合,分析LLM如何赋能RL,并阐述这种融合对于迈向通用人工智能(AGI)的意义。为了更好地理解这一融合的潜力,我们基于“LargeLanguageModela
- 强化学习-Chapter2-贝尔曼方程
Rsbs
算法机器学习概率论
强化学习-Chapter2-贝尔曼方程贝尔曼方程推导继续展开贝尔曼方程的矩阵形式状态值的求解动作价值函数与状态价值函数的关系贝尔曼方程推导Vπ(s)=E[Gt∣St=s]=E[rt+1+(γrt+2+…)∣St=s]=E[rt+1+γGt+1∣St=s]=∑a∈Aπ(s,a)∑s′∈SPs→s′a⋅(Rs→s′a+γE[Gt+1∣St+1=s′])=∑a∈Aπ(s,a)∑s′∈SPs→s′a⋅(R
- 【开源代码解读】AI检索系统R1-Searcher通过强化学习RL激励大模型LLM的搜索能力
accurater
人工智能深度学习R1-Searcher
关于R1-Searcher的报告:第一章:引言-AI检索系统的技术演进与R1-Searcher的创新定位1.1信息检索技术的范式转移在数字化时代爆发式增长的数据洪流中,信息检索系统正经历从传统关键词匹配到语义理解驱动的根本性变革。根据IDC的统计,2023年全球数据总量已突破120ZB,其中非结构化数据占比超过80%。这种数据形态的转变对检索系统提出了三个核心的挑战:语义歧义消除:如何准确理解"A
- PyTorch 深度学习实战(13):Proximal Policy Optimization (PPO) 算法
进取星辰
PyTorch深度学习实战深度学习pytorch算法
在上一篇文章中,我们介绍了Actor-Critic算法,并使用它解决了CartPole问题。本文将深入探讨ProximalPolicyOptimization(PPO)算法,这是一种更稳定、更高效的策略优化方法。我们将使用PyTorch实现PPO算法,并应用于经典的CartPole问题。一、PPO算法基础PPO是OpenAI提出的一种强化学习算法,旨在解决策略梯度方法中的训练不稳定问题。PPO通过
- 院士领衔、IEEE Fellow 坐镇,清华、上交大、复旦、同济等专家齐聚 2025 全球机器学习技术大会
CSDN资讯
机器学习人工智能
随着Manus出圈,OpenManus、OWL迅速开源,OpenAI推出智能体开发工具,全球AI生态正经历新一轮智能体革命。大模型如何协同学习?大模型如何自我进化?新型强化学习技术如何赋能智能体?围绕这些关键问题,由CSDN&Boolan联合举办的「2025全球机器学习技术大会」将于4月18-19日在上海隆重举行。大会云集院士、10所高校科研工作者、近30家一线科技企业技术实战专家组成的超50位重
- 推理大模型:技术解析与未来趋势全景
时光旅人01号
深度学习人工智能pythonpytorch神经网络
1.推理大模型的定义推理大模型(ReasoningLLMs)是专门针对复杂多步推理任务优化的大型语言模型,具备以下核心特性:输出形式创新展示完整逻辑链条(如公式推导、多阶段分析)任务类型聚焦擅长数学证明、编程挑战、多模态谜题等深度逻辑任务训练方法升级融合强化学习、思维链(CoT)、测试时计算扩展等技术2.主流推理大模型图谱2.1国际前沿模型OpenAIo1系列内部生成"思维链"机制数学/代码能力标
- 一文读懂强化学习:从基础到应用
LHTZ
算法时序数据库大数据数据库架构动态规划
强化学习是什么强化学习是人工智能领域的一种学习方法,简单来说,就是让一个智能体(比如机器人、电脑程序)在一个环境里不断尝试各种行为。每次行为后,环境会给智能体一个奖励或者惩罚信号,智能体根据这个信号来调整自己的行为,目的是让自己在未来能获得更多奖励。就像训练小狗,小狗做对了动作(比如坐下),就给它零食(奖励),做错了就没有零食(惩罚),慢慢地小狗就知道怎么做能得到更多零食,也就是学会了最优行为。强
- QwQ-32B企业级本地部署:结合XInference与Open-WebUI使用
大势下的牛马
搭建本地gptRAG知识库人工智能QwQ-32B
QwQ-32B是阿里巴巴Qwen团队推出的一款推理模型,拥有320亿参数,基于Transformer架构,采用大规模强化学习方法训练而成。它在数学推理、编程等复杂问题解决任务上表现出色,性能可媲美拥有6710亿参数的DeepSeek-R1。QwQ-32B在多个基准测试中表现出色,例如在AIME24基准上,其数学问题解决能力得分达到79.5,超过OpenAI的o1-mini。它在LiveBench、
- LLM Weekly(2025.03.03-03.09)
UnknownBody
LLMDailyLLMWeekly语言模型人工智能
网络新闻QwQ-32B:拥抱强化学习的力量。研究人员推出了QwQ-32B,这是一个拥有320亿参数的模型,它利用强化学习来提升推理能力。尽管参数较少,但通过整合类似智能体的推理和反馈机制,QwQ-32B的表现可与更大规模的模型相媲美。该模型可在HuggingFace平台上获取。**人工智能领域的先驱安德鲁·巴托(AndrewBarto)和理查德·萨顿(RichardSutton)因对强化学习的开创
- Chebykan wx 文章阅读
やっはろ
深度学习
文献筛选[1]神经网络:全面基础[2]通过sigmoid函数的超层叠近似[3]多层前馈网络是通用近似器[5]注意力是你所需要的[6]深度残差学习用于图像识别[7]视觉化神经网络的损失景观[8]牙齿模具点云补全通过数据增强和混合RL-GAN[9]强化学习:一项调查[10]使用PySR和SymbolicRegression.jl的科学可解释机器学习[11]Z.Liu,Y.Wang,S.Vaidya,F
- 用物理信息神经网络(PINN)解决实际优化问题:全面解析与实践
青橘MATLAB学习
深度学习网络设计人工智能深度学习物理信息神经网络强化学习
摘要本文系统介绍了物理信息神经网络(PINN)在解决实际优化问题中的创新应用。通过将物理定律与神经网络深度融合,PINN在摆的倒立控制、最短时间路径规划及航天器借力飞行轨道设计等复杂任务中展现出显著优势。实验表明,PINN相比传统数值方法及强化学习(RL)/遗传算法(GA),在收敛速度、解的稳定性及物理保真度上均实现突破性提升。关键词:物理信息神经网络;优化任务;深度学习;强化学习;航天器轨道一、
- django allauth 自定义登录界面
waterHBO
djangopythondjango数据库sqlitepython笔记经验分享
起因,目的:为什么前几天还在写强化学习,今天又写django,问就是:客户需求>个人兴趣。问题来源:allauth默认的登录界面不好看,这里记录几个问题。1.注册页面SignUp这里增加,手机号,邮编等等。2.使用谷歌来登录这个步骤其实也简单。xxxxxxxx一定要修改关键的信息,不能随便暴露给别人。xxxxxxxx#HowtouseGoogleLogin.1.createsuperuser.(m
- 人工智能机器学习算法分类全解析
power-辰南
人工智能人工智能机器学习算法python
目录一、引言二、机器学习算法分类概述(一)基于学习方式的分类1.监督学习(SupervisedLearning)2.无监督学习(UnsupervisedLearning)3.强化学习(ReinforcementLearning)(二)基于任务类型的分类1.分类算法2.回归算法3.聚类算法4.降维算法5.生成算法(三)基于模型结构的分类1.线性模型2.非线性模型3.基于树的模型4.基于神经网络的模型
- 怎么定义世界模型,Sora/Genie/JEPA 谁是世界模型呢?(1)
周博洋K
分布式人工智能深度学习自然语言处理机器学习
说这个问题之前先看一下什么是世界模型,它的定义是什么?首先世界模型的起源是咋回事呢?其实世界模型在ML领域不是什么新概念,远远早于Transfomer这些东西被提出来,因为它最早是强化学习RL领域的,在20世纪90年代由JuergenSchmiduber实验室给提出来的。2018年被Ha和Schmiduber发表了用RNN来做世界模型的论文,相当于给他重新做了一次定义。然后就是最近跟着Sora,G
- 《Natural Actor-Critic》译读笔记
songyuc
笔记
《NaturalActor-Critic》摘要本文提出了一种新型的强化学习架构,即自然演员-评论家(NaturalActor-Critic)。Theactor的更新通过使用Amari的自然梯度方法进行策略梯度的随机估计来实现,而评论家则通过线性回归同时获得自然策略梯度和价值函数的附加参数。本文展示了使用自然策略梯度的actor改进特别有吸引力,因为这些梯度与所选策略表示的坐标框架无关,并且比常规策
- LLM Weekly(2025.02.17-02.23)
UnknownBody
LLMDailyLLMWeekly人工智能自然语言处理
本文是LLM系列文章,主要是针对2025.02.17-02.23这一周的LLM相关新闻与文章、GitHub资源分享。网络新闻Grok3Beta——推理代理的时代。Grok发布了Grok3Beta,通过强化学习、扩展计算和多模态理解提供卓越的推理能力。Grok3和Grok3mini在学术基准上取得了高分,其中Grok3在AIME’25上获得了93.3%的分数。Grok3的推理可通过“思考”按钮访问,
- 大话机器学习三大门派:监督、无监督与强化学习
安意诚Matrix
机器学习笔记机器学习人工智能
以武侠江湖为隐喻,系统阐述了机器学习的三大范式:监督学习(少林派)凭借标注数据精准建模,擅长图像分类等预测任务;无监督学习(逍遥派)通过数据自组织发现隐藏规律,在生成对抗网络(GAN)等场景大放异彩;强化学习(明教)依托动态环境交互优化策略,驱动AlphaGo、自动驾驶等突破性应用。文章融合技术深度与江湖趣味,既解析了CNN、PCA、Q-learning等核心算法的"武功心法"(数学公式与代码实现
- TOMCAT在POST方法提交参数丢失问题
357029540
javatomcatjsp
摘自http://my.oschina.net/luckyi/blog/213209
昨天在解决一个BUG时发现一个奇怪的问题,一个AJAX提交数据在之前都是木有问题的,突然提交出错影响其他处理流程。
检查时发现页面处理数据较多,起初以为是提交顺序不正确修改后发现不是由此问题引起。于是删除掉一部分数据进行提交,较少数据能够提交成功。
恢复较多数据后跟踪提交FORM DATA ,发现数
- 在MyEclipse中增加JSP模板 删除-2008-08-18
ljy325
jspxmlMyEclipse
在D:\Program Files\MyEclipse 6.0\myeclipse\eclipse\plugins\com.genuitec.eclipse.wizards_6.0.1.zmyeclipse601200710\templates\jsp 目录下找到Jsp.vtl,复制一份,重命名为jsp2.vtl,然后把里面的内容修改为自己想要的格式,保存。
然后在 D:\Progr
- JavaScript常用验证脚本总结
eksliang
JavaScriptjavaScript表单验证
转载请出自出处:http://eksliang.iteye.com/blog/2098985
下面这些验证脚本,是我在这几年开发中的总结,今天把他放出来,也算是一种分享吧,现在在我的项目中也在用!包括日期验证、比较,非空验证、身份证验证、数值验证、Email验证、电话验证等等...!
&nb
- 微软BI(4)
18289753290
微软BI SSIS
1)
Q:查看ssis里面某个控件输出的结果:
A MessageBox.Show(Dts.Variables["v_lastTimestamp"].Value.ToString());
这是我们在包里面定义的变量
2):在关联目的端表的时候如果是一对多的关系,一定要选择唯一的那个键作为关联字段。
3)
Q:ssis里面如果将多个数据源的数据插入目的端一
- 定时对大数据量的表进行分表对数据备份
酷的飞上天空
大数据量
工作中遇到数据库中一个表的数据量比较大,属于日志表。正常情况下是不会有查询操作的,但如果不进行分表数据太多,执行一条简单sql语句要等好几分钟。。
分表工具:linux的shell + mysql自身提供的管理命令
原理:使用一个和原表数据结构一样的表,替换原表。
linux shell内容如下:
=======================开始
- 本质的描述与因材施教
永夜-极光
感想随笔
不管碰到什么事,我都下意识的想去探索本质,找寻一个最形象的描述方式。
我坚信,世界上对一件事物的描述和解释,肯定有一种最形象,最贴近本质,最容易让人理解
&
- 很迷茫。。。
随便小屋
随笔
小弟我今年研一,也是从事的咱们现在最流行的专业(计算机)。本科三流学校,为了能有个更好的跳板,进入了考研大军,非常有幸能进入研究生的行业(具体学校就不说了,怕把学校的名誉给损了)。
先说一下自身的条件,本科专业软件工程。主要学习就是软件开发,几乎和计算机没有什么区别。因为学校本身三流,也就是让老师带着学生学点东西,然后让学生毕业就行了。对专业性的东西了解的非常浅。就那学的语言来说
- 23种设计模式的意图和适用范围
aijuans
设计模式
Factory Method 意图 定义一个用于创建对象的接口,让子类决定实例化哪一个类。Factory Method 使一个类的实例化延迟到其子类。 适用性 当一个类不知道它所必须创建的对象的类的时候。 当一个类希望由它的子类来指定它所创建的对象的时候。 当类将创建对象的职责委托给多个帮助子类中的某一个,并且你希望将哪一个帮助子类是代理者这一信息局部化的时候。
Abstr
- Java中的synchronized和volatile
aoyouzi
javavolatilesynchronized
说到Java的线程同步问题肯定要说到两个关键字synchronized和volatile。说到这两个关键字,又要说道JVM的内存模型。JVM里内存分为main memory和working memory。 Main memory是所有线程共享的,working memory则是线程的工作内存,它保存有部分main memory变量的拷贝,对这些变量的更新直接发生在working memo
- js数组的操作和this关键字
百合不是茶
js数组操作this关键字
js数组的操作;
一:数组的创建:
1、数组的创建
var array = new Array(); //创建一个数组
var array = new Array([size]); //创建一个数组并指定长度,注意不是上限,是长度
var arrayObj = new Array([element0[, element1[, ...[, elementN]]]
- 别人的阿里面试感悟
bijian1013
面试分享工作感悟阿里面试
原文如下:http://greemranqq.iteye.com/blog/2007170
一直做企业系统,虽然也自己一直学习技术,但是感觉还是有所欠缺,准备花几个月的时间,把互联网的东西,以及一些基础更加的深入透析,结果这次比较意外,有点突然,下面分享一下感受吧!
&nb
- 淘宝的测试框架Itest
Bill_chen
springmaven框架单元测试JUnit
Itest测试框架是TaoBao测试部门开发的一套单元测试框架,以Junit4为核心,
集合DbUnit、Unitils等主流测试框架,应该算是比较好用的了。
近期项目中用了下,有关itest的具体使用如下:
1.在Maven中引入itest框架:
<dependency>
<groupId>com.taobao.test</groupId&g
- 【Java多线程二】多路条件解决生产者消费者问题
bit1129
java多线程
package com.tom;
import java.util.LinkedList;
import java.util.Queue;
import java.util.concurrent.ThreadLocalRandom;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.loc
- 汉字转拼音pinyin4j
白糖_
pinyin4j
以前在项目中遇到汉字转拼音的情况,于是在网上找到了pinyin4j这个工具包,非常有用,别的不说了,直接下代码:
import java.util.HashSet;
import java.util.Set;
import net.sourceforge.pinyin4j.PinyinHelper;
import net.sourceforge.pinyin
- org.hibernate.TransactionException: JDBC begin failed解决方案
bozch
ssh数据库异常DBCP
org.hibernate.TransactionException: JDBC begin failed: at org.hibernate.transaction.JDBCTransaction.begin(JDBCTransaction.java:68) at org.hibernate.impl.SessionImp
- java-并查集(Disjoint-set)-将多个集合合并成没有交集的集合
bylijinnan
java
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.ut
- Java PrintWriter打印乱码
chenbowen00
java
一个小程序读写文件,发现PrintWriter输出后文件存在乱码,解决办法主要统一输入输出流编码格式。
读文件:
BufferedReader
从字符输入流中读取文本,缓冲各个字符,从而提供字符、数组和行的高效读取。
可以指定缓冲区的大小,或者可使用默认的大小。大多数情况下,默认值就足够大了。
通常,Reader 所作的每个读取请求都会导致对基础字符或字节流进行相应的读取请求。因
- [天气与气候]极端气候环境
comsci
环境
如果空间环境出现异变...外星文明并未出现,而只是用某种气象武器对地球的气候系统进行攻击,并挑唆地球国家间的战争,经过一段时间的准备...最大限度的削弱地球文明的整体力量,然后再进行入侵......
那么地球上的国家应该做什么样的防备工作呢?
&n
- oracle order by与union一起使用的用法
daizj
UNIONoracleorder by
当使用union操作时,排序语句必须放在最后面才正确,如下:
只能在union的最后一个子查询中使用order by,而这个order by是针对整个unioning后的结果集的。So:
如果unoin的几个子查询列名不同,如
Sql代码
select supplier_id, supplier_name
from suppliers
UNI
- zeus持久层读写分离单元测试
deng520159
单元测试
本文是zeus读写分离单元测试,距离分库分表,只有一步了.上代码:
1.ZeusMasterSlaveTest.java
package com.dengliang.zeus.webdemo.test;
import java.util.ArrayList;
import java.util.List;
import org.junit.Assert;
import org.j
- Yii 截取字符串(UTF-8) 使用组件
dcj3sjt126com
yii
1.将Helper.php放进protected\components文件夹下。
2.调用方法:
Helper::truncate_utf8_string($content,20,false); //不显示省略号 Helper::truncate_utf8_string($content,20); //显示省略号
&n
- 安装memcache及php扩展
dcj3sjt126com
PHP
安装memcache tar zxvf memcache-2.2.5.tgz cd memcache-2.2.5/ /usr/local/php/bin/phpize (?) ./configure --with-php-confi
- JsonObject 处理日期
feifeilinlin521
javajsonJsonOjbectJsonArrayJSONException
写这边文章的初衷就是遇到了json在转换日期格式出现了异常 net.sf.json.JSONException: java.lang.reflect.InvocationTargetException 原因是当你用Map接收数据库返回了java.sql.Date 日期的数据进行json转换出的问题话不多说 直接上代码
&n
- Ehcache(06)——监听器
234390216
监听器listenerehcache
监听器
Ehcache中监听器有两种,监听CacheManager的CacheManagerEventListener和监听Cache的CacheEventListener。在Ehcache中,Listener是通过对应的监听器工厂来生产和发生作用的。下面我们将来介绍一下这两种类型的监听器。
- activiti 自带设计器中chrome 34版本不能打开bug的解决
jackyrong
Activiti
在acitivti modeler中,如果是chrome 34,则不能打开该设计器,其他浏览器可以,
经证实为bug,参考
http://forums.activiti.org/content/activiti-modeler-doesnt-work-chrome-v34
修改为,找到
oryx.debug.js
在最头部增加
if (!Document.
- 微信收货地址共享接口-终极解决
laotu5i0
微信开发
最近要接入微信的收货地址共享接口,总是不成功,折腾了好几天,实在没办法网上搜到的帖子也是骂声一片。我把我碰到并解决问题的过程分享出来,希望能给微信的接口文档起到一个辅助作用,让后面进来的开发者能快速的接入,而不需要像我们一样苦逼的浪费好几天,甚至一周的青春。各种羞辱、谩骂的话就不说了,本人还算文明。
如果你能搜到本贴,说明你已经碰到了各种 ed
- 关于人才
netkiller.github.com
工作面试招聘netkiller人才
关于人才
每个月我都会接到许多猎头的电话,有些猎头比较专业,但绝大多数在我看来与猎头二字还是有很大差距的。 与猎头接触多了,自然也了解了他们的工作,包括操作手法,总体上国内的猎头行业还处在初级阶段。
总结就是“盲目推荐,以量取胜”。
目前现状
许多从事人力资源工作的人,根本不懂得怎么找人才。处在人才找不到企业,企业找不到人才的尴尬处境。
企业招聘,通常是需要用人的部门提出招聘条件,由人
- 搭建 CentOS 6 服务器 - 目录
rensanning
centos
(1) 安装CentOS
ISO(desktop/minimal)、Cloud(AWS/阿里云)、Virtualization(VMWare、VirtualBox)
详细内容
(2) Linux常用命令
cd、ls、rm、chmod......
详细内容
(3) 初始环境设置
用户管理、网络设置、安全设置......
详细内容
(4) 常驻服务Daemon
- 【求助】mongoDB无法更新主键
toknowme
mongodb
Query query = new Query(); query.addCriteria(new Criteria("_id").is(o.getId())); &n
- jquery 页面滚动到底部自动加载插件集合
xp9802
jquery
很多社交网站都使用无限滚动的翻页技术来提高用户体验,当你页面滑到列表底部时候无需点击就自动加载更多的内容。下面为你推荐 10 个 jQuery 的无限滚动的插件:
1. jQuery ScrollPagination
jQuery ScrollPagination plugin 是一个 jQuery 实现的支持无限滚动加载数据的插件。
2. jQuery Screw
S

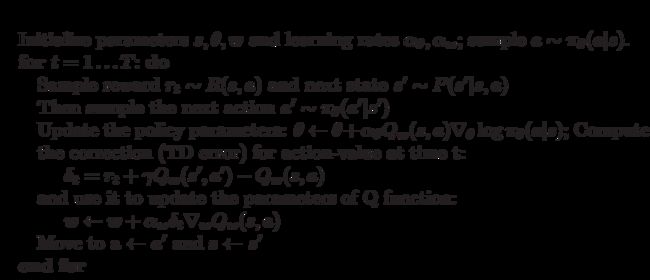


 关于 Critic 的更新,它借鉴了 DQN 和 Double Q learning 的方式,有两个计算 Q 的神经网络, Q_target( Q ′ Q' Q′) 中依据下一状态,用 Actor 来选择动作( u ′ u' u′),而这时的 Actor 也是一个 Actor_target (有着 Actor 很久之前的参数)。 使用这种方法获得的 Q_target 能像 DQN 那样切断相关性,提高收敛性。
关于 Critic 的更新,它借鉴了 DQN 和 Double Q learning 的方式,有两个计算 Q 的神经网络, Q_target( Q ′ Q' Q′) 中依据下一状态,用 Actor 来选择动作( u ′ u' u′),而这时的 Actor 也是一个 Actor_target (有着 Actor 很久之前的参数)。 使用这种方法获得的 Q_target 能像 DQN 那样切断相关性,提高收敛性。