yolo-nano详解
yolo-nano详解
简介
论文:https://arxiv.org/abs/1910.01271
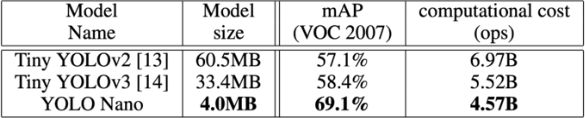
在本文中,来自滑铁卢大学与 Darwin AI 的研究者提出了名为 YOLO Nano 的网络,他们通过人与机器协同设计模型架构大大提升了性能。YOLO Nano 大小只有 4.0MB 左右,比 Tiny YOLOv2 和 Tiny YOLOv3 分别小了 15.1 倍和 8.3 倍,在计算上需要 4.57B 次推断运算,比后两个网络分别少了 34% 和 17%,在性能表现上,在 VOC2007 数据集取得了 69.1% 的 mAP,准确率比后两者分别提升了 12 个点和 10.7 个点,具体如下图。
设计思路
机器驱动的探索设计:
在这一阶段,研究者让机器使用最初的原型网络(论文中未给出)、数据(voc2007)和指标(1r(·) ),然后机器驱动的探索设计会决定模块级别的宏架构和微架构,用于最终的 YOLO Nano 网络。
可以转换为网络生成器 G 的一个带约束的最优化问题:即在给定一系列种子 S 的情形下,生成网络 {N_s|s ∈ S} 在指标函数1r(·)的约束限制下,最大化全局性能函数 U。

由于求解方程式中的约束优化问题中的全局最优解在计算上难以解决,我们通过迭代优化来求解近似解^ G,设置初始解^ G0,并逐步迭代更新(每个连续的近似解^ Gk都比以前的近似解(即^ G1,:::,Gk-1等)获得更高的U值),最终的 G创建YOLO Nano网络。约束函数1r(·)设置为:VOC 2007的平均平均精度(mAP)为65%;计算成本5B;8位权重精度。
注:以上只是概括的探索设计思路,具体的网络生成器以及性能函数的具体设计并未给出(这是核心所在)。
最终的网络架构:

残差 PEP 宏架构:
一个 1*1 卷积的映射层,它将输入的特征图映射到较低维度的张量,PEP(num)中的num为较低的维度;
一个 1*1 卷积的扩张层,它会将特征图的通道再扩张到高一些的维度;
一个逐深度(depth-wise)的卷积层,它会通过不同滤波器对不同的扩张层输出通道执行空间卷积;
一个 1*1 卷积的映射层,它将前一层的输出通道映射到较低维度。
结构解析:
前两步组合跨通道融合特征;
第二步增加特征维度后,使第三步中更多的通道特征做空间的特征融合(提高特征的抽象和表征能力);
第三步深度卷积部分(空间卷积);
第四步逐点卷积部分(通道卷积),降低通道减少后边卷积带来的巨大计算量;
后两部组成深度可分离式卷积,实现降低计算复杂度情况下保证模型的表征能力。
残差 PEP 宏架构的使用可以显著降低架构和计算上的复杂度,同时还能保证模型的表征能力。
全连接注意力宏架构:
通过机器驱动设计的探索过程,研究者在神经网络引入了轻量级的全连接注意力(FCA)模块。FCA 宏架构由两个全连接层组成,它们可以学习通道之间的动态、非线性内部依赖关系,并通过通道级的乘法重新加权通道的重要性。
FCA 的使用有助于基于全局信息关注更加具有信息量的特征,因为它再校准了一遍动态特征。这可以更有效利用神经网络的能力,即在有限参数量下尽可能表达重要信息。因此,该模块可以在修剪模型架构、降低模型复杂度、增加模型表征力之间做更好的权衡。
FCA模块详细解析:
此模块类似于SENet中的SE模块,如下图所示:
论文:《Squeeze-and-Excitation Networks》
论文链接:https://arxiv.org/abs/1709.01507
代码地址:https://github.com/hujie-frank/SENet
PyTorch代码地址:https://github.com/miraclewkf/SENet-PyTorch

上图是SE 模块的示意图。给定一个输入 x,其特征通道数为 c_1,通过一系列卷积等一般变换后得到一个特征通道数为 c_2 的特征。与传统的 CNN 不一样的是,接下来通过三个操作来重标定前面得到的特征。
Squeeze 操作:
顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。

公式非常简单,就是一个global average pooling,将H * W * C的输入转换成1 * 1 * C的输出。
Excitation 操作:
它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。

直接看最后一个等号,前面squeeze得到的结果是z,这里先用W1乘以z,就是一个全连接层操作,W1的维度是C/r * C,这个r是一个缩放参数,在文中取的是16(yolo-nano网络中取的8),这个参数的目的是为了减少channel个数从而降低计算量。又因为z的维度是1 * 1 * C,所以W1z的结果就是1 * 1 * C/r;然后再经过一个ReLU层,输出的维度不变;然后再和W2相乘,和W2相乘也是一个全连接层的过程,W2的维度是C * C/r,因此输出的维度就是1 * 1 *C;最后再经过sigmoid函数,得到s。
s其实是本文的核心,它是用来刻画tensor U中C个feature map的权重。而且这个权重是通过前面这些全连接层和非线性层学习得到的,因此可以end-to-end训练。这两个全连接层的作用就是融合各通道的feature map信息,因为前面的squeeze都是在某个channel的feature map里面操作。
Reweight 的操作:
将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。

就是channel-wise multiplication,uc是一个二维矩阵,sc是一个数,也就是权重,因此相当于把uc矩阵中的每个值都乘以sc。
SE模块 在具体网络中应用:

上左图是将 SE 模块嵌入到 Inception 结构的一个示例。方框旁边的维度信息代表该层的输出。
这里我们使用 global average pooling 作为 Squeeze 操作。紧接着两个 Fully Connected 层组成一个 Bottleneck 结构去建模通道间的相关性,并输出和输入特征同样数目的权重。我们首先将特征维度降低到输入的 1/16,然后经过 ReLu 激活后再通过一个 Fully Connected 层升回到原来的维度。这样做比直接用一个 Fully Connected 层的好处在于:1)具有更多的非线性,可以更好地拟合通道间复杂的相关性;2)极大地减少了参数量和计算量。然后通过一个 Sigmoid 的门获得 0~1 之间归一化的权重,最后通过一个 Scale 的操作来将归一化后的权重加权到每个通道的特征上。
除此之外,SE 模块还可以嵌入到含有 skip-connections 的模块中。上右图是将 SE 嵌入到 ResNet 模块中的一个例子,操作过程基本和 SE-Inception 一样,只不过是在 Addition 前对分支上 Residual 的特征进行了特征重标定。如果对 Addition 后主支上的特征进行重标定,由于在主干上存在 0~1 的 scale 操作,在网络较深 BP 优化时就会在靠近输入层容易出现梯度消散的情况,导致模型难以优化。
目前大多数的主流网络都是基于这两种类似的单元通过 repeat 方式叠加来构造的。由此可见,SE 模块可以嵌入到现在几乎所有的网络结构中。通过在原始网络结构的 building block 单元中嵌入 SE 模块,我们可以获得不同种类的 SENet。如 SE-BN-Inception、SE-ResNet、SE-ReNeXt、SE-Inception-ResNet-v2 等等。
可行性评估:
1.没有开源工程,论文中的信息不足以支撑实现代码的开发以及效果的复现(机器驱动的设计方法只提供了理论私思想)。
2.最终的网络架构以及提出的PEP和FCA模块,可以作为设计网络的借鉴之处。
3.原始yolov3在voc2007的MAP(79%左右),可以适当增加yolo-nano的网络复杂程度,继续提高模型性能。
4.最近看到项目开源(好像不是原作者,工程有待验证,后续会进行更新):https://github.com/liux0614/yolo_nano
参考:
yolo-nano: http://www.360doc.com/content/19/1007/06/46368139_865253393.shtml
SENet:https://blog.csdn.net/weixin_41923961/article/details/88983505
DWConv:https://blog.csdn.net/qq_30815237/article/details/95913655