【论文阅读】End-to-End Object Detection with Transformers
【论文阅读】End-to-End Object Detection with Transformers
- 损失函数
- 网络架构
- Transformer
- 代码运行
创新:
- 引入transformer,提出DETR(DEtection TRansformer)模型
- 去除以往模型引入的先验知识(achor、nms)
- 大物体精度高—得益于transformer的non-local computations,但是对小物体精度低
损失函数
网络的输出为N个检测框(包含类别),因为很难去度量检测结果的好坏,就提出了一个损失。首先将gt box也变成长度为N的序列以便和网络输出进行匹配,不够长度的用 ∅ \emptyset ∅补充,然后对这个序列排列组合,找到和预测的N个序列损失最小的序列来优化。这样就可以得到一对一的关系,也不用后处理操作NMS。
损失函数具体实现??
网络架构
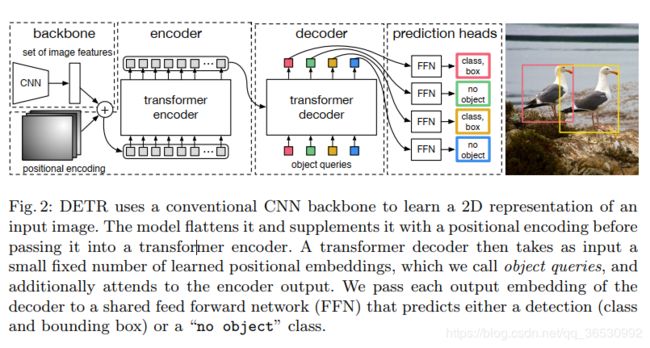
结构分为3部分:
- backbone:[3, H, W] 变为[2048, H/32, W/32]
- encoder-decoder transformer
- FFN(feed forward network)
Transformer
这部分建议不懂得可以先看李宏毅老师的transformer讲解(b站自行搜索)以及https://jalammar.github.io/illustrated-transformer/
看论文过程中不太懂
positional encoding如何表达??
代码运行
数据处理部分:(只对部分代码进行说明,基本的数据提取和变换不做介绍)
构建一个batch的时候,通过collate_fn传入到dataloader里面收集处理该batch,对图像的像素主要通过NestedTensor这个类进行处理,从而可以处理不同大小的图片,处理之后每个batch的大小可能不一样,batch里面的图像大小是一样的。
# DETR/util/misc.py
def collate_fn(batch):
#print(len(batch)) #2
#print(batch[0][0].shape) #和batch[0][1]中‘size’一样
#print(batch[0][1]) #包含0图片的各种信息
# batch 是多个img boxes label 等信息组成的列表 通过zip从里面各取出元素组成新的列表
batch = list(zip(*batch))
batch[0] = NestedTensor.from_tensor_list(batch[0]) # batch[0]就仅仅包含了reshape后的batch img
return tuple(batch)
class NestedTensor(object):
def __init__(self, tensors, mask):
self.tensors = tensors
self.mask = mask
def to(self, *args, **kwargs):
cast_tensor = self.tensors.to(*args, **kwargs)
cast_mask = self.mask.to(*args, **kwargs) if self.mask is not None else None
return type(self)(cast_tensor, cast_mask)
def decompose(self):
return self.tensors, self.mask
@classmethod # 可以不需要实例化
def from_tensor_list(cls, tensor_list): # 表示自身对象的self和自身类的cls参数
# TODO make this more general
if tensor_list[0].ndim == 3:
# TODO make it support different-sized images
max_size = tuple(max(s) for s in zip(*[img.shape for img in tensor_list]))
#print(max_size) # 该batch里面长宽最大的值
#print(len(tensor_list)) # 2
# min_size = tuple(min(s) for s in zip(*[img.shape for img in tensor_list]))
batch_shape = (len(tensor_list),) + max_size
#print(batch_shape)
b, c, h, w = batch_shape
dtype = tensor_list[0].dtype
device = tensor_list[0].device
tensor = torch.zeros(batch_shape, dtype=dtype, device=device)
mask = torch.ones((b, h, w), dtype=torch.bool, device=device)
for img, pad_img, m in zip(tensor_list, tensor, mask):
pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
m[: img.shape[1], :img.shape[2]] = False
else:
raise ValueError('not supported')
return cls(tensor, mask)
def __repr__(self):
return repr(self.tensors)
网络结构
- backbone部分主要由resnet50和PosionEncoding两个层构成,将resnet50最后一层的输出再输入到PosionEncoding里面进行对位置的编码。其主要变换就是对特征图上的每一个像素的x和y坐标分别生成一个128维的向量,前半部分由sin函数得到,后半部分由cos函数得到。然后将x和y生成的encoding向量拼接起来。
class PositionEmbeddingSine(nn.Module):
"""
This is a more standard version of the position embedding, very similar to the one
used by the Attention is all you need paper, generalized to work on images.
"""
def __init__(self, num_pos_feats=64, temperature=10000, normalize=False, scale=None):
super().__init__()
self.num_pos_feats = num_pos_feats # embedding的一半
self.temperature = temperature
self.normalize = normalize
if scale is not None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
if scale is None:
scale = 2 * math.pi
self.scale = scale
def forward(self, tensor_list):
ipdb.set_trace()
x = tensor_list.tensors
mask = tensor_list.mask # mask中以左上角为起始点,resize后的原图大小区域为false,其他区域为1
not_mask = ~mask
y_embed = not_mask.cumsum(1, dtype=torch.float32) # 按列累加
x_embed = not_mask.cumsum(2, dtype=torch.float32) # 按行累加
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale # y_embed[:, -1:, :] 最大的数
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats) # 128
pos_x = x_embed[:, :, :, None] / dim_t # torch.Size([2, 24, 36, 128])
pos_y = y_embed[:, :, :, None] / dim_t
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
return pos # torch.Size([2, 256, 24, 36])
- Encoder
TransformerEncoder(
(layers): ModuleList(
(0): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(1): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(2): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(3): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(4): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(5): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
)
)
- Decoder
TransformerDecoder(
(layers): ModuleList(
(0): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
(1): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
(2): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
(3): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
(4): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
(5): TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
)
(norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
- detr
class DETR(nn.Module):
""" This is the DETR module that performs object detection """
def __init__(self, backbone, transformer, num_classes, num_queries, aux_loss=False):
""" Initializes the model.
Parameters:
backbone: torch module of the backbone to be used. See backbone.py
transformer: torch module of the transformer architecture. See transformer.py
num_classes: number of object classes
num_queries: number of object queries, ie detection slot. This is the maximal number of objects
DETR can detect in a single image. For COCO, we recommend 100 queries.
aux_loss: True if auxiliary decoding losses (loss at each decoder layer) are to be used.
"""
super().__init__()
self.num_queries = num_queries # 100
self.transformer = transformer
hidden_dim = transformer.d_model
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3) # 3个全连接层
self.query_embed = nn.Embedding(num_queries, hidden_dim)
self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1)
self.backbone = backbone
self.aux_loss = aux_loss
def forward(self, samples: NestedTensor):
""" The forward expects a NestedTensor, which consists of:
- samples.tensors: batched images, of shape [batch_size x 3 x H x W]
- samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixels
It returns a dict with the following elements:
- "pred_logits": the classification logits (including no-object) for all queries.
Shape= [batch_size x num_queries x (num_classes + 1)]
- "pred_boxes": The normalized boxes coordinates for all queries, represented as
(center_x, center_y, height, width). These values are normalized in [0, 1],
relative to the size of each individual image (disregarding possible padding).
See PostProcess for information on how to retrieve the unnormalized bounding box.
- "aux_outputs": Optional, only returned when auxilary losses are activated. It is a list of
dictionnaries containing the two above keys for each decoder layer.
"""
if not isinstance(samples, NestedTensor):
samples = NestedTensor.from_tensor_list(samples)
features, pos = self.backbone(samples) # self.backbone长度为2 resnet和PositionEmbeddingSine()
src, mask = features[-1].decompose()
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0] # torch.Size([6, 2, 100, 256])
outputs_class = self.class_embed(hs) # torch.Size([6, 2, 100, 92])
outputs_coord = self.bbox_embed(hs).sigmoid() # torch.Size([6, 2, 100, 4])
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]} # [2, 100, 92] [2, 100, 4]
if self.aux_loss:
out['aux_outputs'] = [{'pred_logits': a, 'pred_boxes': b}
for a, b in zip(outputs_class[:-1], outputs_coord[:-1])] # 将前面的5个decoder的输出作为aux_loss
return out
损失函数部分
首先是利用HungarianMatcher(models/matcher.py)进行匹配,这个部分主要计算了3个损失。对于分类损失cost_class,将相对应图片上的所有类别通道的预测值取出来([2, 100, num_class]变为[2, 100 ,num_obj]),然后再取负号。对于回归损失,直接计算所有2x100个序列的预测值和所有该batch中gt bbox的距离。最后再计算一个giou损失。将这三个损失加权相加得到最后的损失。然后利用scipy.optimize中的linear_sum_assignmen函数完成匈牙利算法(一个出发点只能对应一个终点),选出3个最佳序列。
然后就是计算真正的损失了,分类损失用NLL,回归损失用L1,cardinality error计算的是真正的gt数和预测出来的gt数的差距,不是真正意义上的损失,不进行梯度回传。
测试阶段
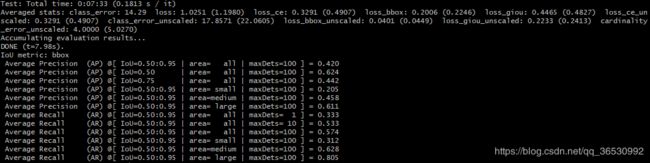
他将最终的100的预测结果都进评估。