大话数据结构 -- KMP模式匹配算法
串这一节在大一学数据结构时老师并没有着重讲解,只让我们会求一个字符串的next数组就行了,这次学习的时候认真看了下,也花了挺长时间的,好好总结一下:
1、串的匹配是串的基础同时也非常重要的操作,最初人们用朴素的模式匹配算法,即:
int Index(String S, String T, int pos){ //在主串S中找到从pos开始与子串T相匹配的第一个字符的位置
int i=pos;
int j=1;
while(i<=S[0]&&j<=T[0]){ // 注意i<=S[0]和j<=T[0]要同时满足
if(S[i]==T[j]){ //匹配一致,则均后移继续匹配
i++;
j++;
}
else{ //匹配不一致,则主串下标后移一位,子串下标置1
i=i-j+2;
j=1;
}
}
if(j>T[0]) //j>T[0]说明子串全部比较完且与主串中某一部分一致
return i-T[0]; // 注意i才是主串的下标,i-T[0]返回开始匹配的位置
else
return 0;
}
主要特征是当匹配不一致时,主串的下标会后移一位,而子串下标直接置1从头开始比较。
这种方法有什么不好呢?来看一个极端情况:
主串为S="00000000000000000000000000000000000000000000000001",而要匹配的子串为T="0000000001",前者是有49个“0”和1个“1”的主串,后者是9个“0”和1个“1”的子串。在匹配时,每次都得将T中字符循环到最后一位才发现:哦,原来它们是不匹配的。这样等于T串需要在S串的前40个位置都需要判断10次,并得出不匹配的结论,如图5-6-6所示。
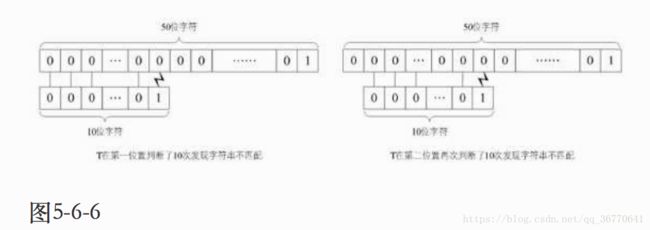
直到最后第41个位置,因为全部匹配相等,所以不需要再继续进行下去,如图5-6-7所示。如果最终没有可匹配的子串,比如是T="0000000002",到了第41位置判断不匹配后同样不需要继续比对下去。因此最坏情况的时间复杂度为O((n-m+1)*m)。
如何改进?
2、KMP模式匹配算法发现了朴素算法的不足,主要特点是:
1)、待匹配串某几位互不相等,而它们又在主串中有对应的子串,当后一位匹配失败时,待匹配串中的这几位不必再与主串中明显与自己不相等的字符去比较;
2)、待匹配串中存在回文相等,且它们在主串中有对应的子串,当后一位匹配失败时,待匹配串中回文串的前几位不必再与主串中明显与自己相等的字符去比较。
// 通过计算返回子串T的next数组
void get_next(String T, int *next){
int i,j;
i=1;
j=0;
next[1]=0;
// 此处T[0]表示串T的长度
while(iT[0]){
return i-T[0];
}
else
return 0;
}
简而言之就是,比较过的,明显不相等的,不用再比;比较过的,明显相等的,也不用再比。由此,效率大大提升。
若T的长度为m,因只涉及到简单的单循环,其时间复杂度为O(m),而由于i值的不回溯,使得KMP算法效率得到了提高,while循环的时间复杂度为O(n)。因此,整个算法的时间复杂度为O(n+m)。相较于朴素模式匹配算法的O((n-m+1)*m)来说,是要好一些。
这里也需要强调,KMP算法仅当模式与主串之间存在许多“部分匹配”的情况下才体现出它的优势,否则两者差异并不明显。
3、KMP模式匹配算法的改进:
考虑这样一种情况:待匹配串的前i位均为同一字符,且与主串匹配成功,第i+1位仍为这个字符,而主串中则不是,此时匹配失败。这时如果用上述KMP算法,会发现next[i+1]=i,所以又从i位开始匹配,还是同样的失败——又从i-1位,i-2位,....,一直到第一位。我们会发现,这些比较是不必要的。因为前i+1位字符都相同,第i+1位不匹配,前i位肯定也不匹配。故对KMP算法作以下改进:(并引入nextval数组)
1)、若当前字符与前缀字符不同,则当前的j为nextval在i位置的值;
2)、若当前字符与前缀字符相同,则将前缀字符的nextval值赋值给nextval在i位置的值。
//KMP模式匹配算法的改进
// 求模式串T的next函数修正值并存入数组nextval
void get_nextval(String T,int *nextval){
int i,j;
i=1;
j=0;
nextval[1]=0;
while(i关于串的KMP模式匹配算法的个人总结大致如上。
--------------------------------------------------------
以下是摘录自《大话数据结构》的详细讲解:
概念引入
如果主串S="abcdefgab",其实还可以更长一些,我们就省略掉只保留前9位,我们要匹配的T="abcdex",那么如果用前面的朴素算法的话,前5个字母,两个串完全相等,直到第6个字母,“f”与“x”不等,如图5-7-1的①所示。

接下来,按照朴素模式匹配算法,应该是如图5-7-1的流程②③④⑤⑥。即主串S中当i=2、3、4、5、6时,首字符与子串T的首字符均不等。
似乎这也是理所当然,原来的算法就是这样设计的。可仔细观察发现。对于要匹配的子串T来说,“abcdex”首字母“a”与后面的串“bcdex”中任意一个字符都不相等。也就是说,既然“a”不与自己后面的子串中任何一字符相等,那么对于图5-7-1的①来说,前五位字符分别相等,意味着子串T的首字符“a”不可能与S串的第2位到第5位的字符相等。在图5-7-1中,②③④⑤的判断都是多余。
注意这里是理解KMP算法的关键。如果我们知道T串中首字符“a”与T中后面的字符均不相等(注意这是前提,如何判断后面再讲)。而T串的第二位的“b”与S串中第二位的“b”在图5-7-1的①中已经判断是相等的,那么也就意味着,T串中首字符“a”与S串中的第二位“b”是不需要判断也知道它们是不可能相等了,这样图5-7-1的②这一步判断是可以省略的,如图5-7-2所示。

同样道理,在我们知道T串中首字符“a”与T中后面的字符均不相等的前提下,T串的“a”与S串后面的“c”、“d”、“e”也都可以在①之后就可以确定是不相等的,所以这个算法当中②③④⑤没有必要,只保留①⑥即可,如下图所示。

之所以保留⑥中的判断是因为在①中T[6]≠S[6],尽管我们已经知道T[1]≠T[6],但也不能断定T[1]一定不等于S[6],因此需要保留⑥这一步。
有人就会问,如果T串后面也含有首字符“a”的字符怎么办呢?
我们来看下面一个例子,假设S="abcababca",T="abcabx"。对于开始的判断,前5个字符完全相等,第6个字符不等,如图5-7-4的①。此时,根据刚才的经验,T的首字符“a”与T的第二位字符“b”、第三位字符“c”均不等,所以不需要做判断,图5-7-4的朴素算法步骤②③都是多余。

因为T的首位“a”与T第四位的“a”相等,第二位的“b”与第五位的“b”相等。而在①时,第四位的“a”与第五位的“b”已经与主串S中的相应位置比较过了,是相等的,因此可以断定,T的首字符“a”、第二位的字符“b”与S的第四位字符和第五位字符也不需要比较了,肯定也是相等的——之前比较过了,还判断什么,所以④⑤这两个比较得出字符相等的步骤也可以省略。
也就是说,对于在子串中有与首字符相等的字符,也是可以省略一部分不必要的判断步骤。如图5-7-5所示,省略掉右图的T串前两位“a”与“b”同S串中的4、5位置字符匹配操作。
我们把T串各个位置的j值的变化定义为一个数组next,那么next的长度就是T串的长度。于是我们可以得到下面的函数定义:

next数组推导
具体如何推导出一个串的next数组值呢,我们来看一些例子。
1.T="abcdex"
j 123456
模式串T abcdex
next[j] 011111
1)当j=1时,next[1]=0;
2)当j=2时,j由1到j-1就只有字符“a”,属于其他情况next[2]=1;
3)当j=3时,j由1到j-1串是“ab”,显然“a”与“b”不相等,属其他情况,next[3]=1;
4)以后同理,所以最终此T串的next[j]为011111。
2.T="abcabx"
j 123456
模式串T abcabx
next[j] 011123
1)当j=1时,next[1]=0;
2)当j=2时,同上例说明,next[2]=1;
3)当j=3时,同上,next[3]=1;
4)当j=4时,同上,next[4]=1;
5)当j=5时,此时j由1到j-1的串是“abca”,前缀字符“a”与后缀字符“a”相等(前缀用下划线表示,后缀用斜体表示),因此可推算出k值为2(由‘p1...pk-1’=‘pj-k+1...pj-1’,得到p1=p4)因此next[5]=2;
6)当j=6时,j由1到j-1的串是“abcab”,由于前缀字符“ab”与后缀“ab”相等,所以next[6]=3。
我们可以根据经验得到如果前后缀一个字符相等,k值是2,两个字符k值是3,n个相等k值就是n+1。
4.T="aaaaaaaab"
j 123456789
模式串T aaaaaaaab
next[j] 012345678
1)当j=1时,next[1]=0;
2)当j=2时,同上next[2]=1;
3)当j=3时,j由1到j-1的串是“aa”,前缀字符“a”与后缀字符“a”相等,next[3]=2;
4)当j=4时,j由1到j-1的串是“aaa”,由于前缀字符“aa”与后缀“aa”相等,所以next[4]=3;
5)……
6)当j=9时,j由1到j-1的串是“aaaaaaaa”,由于前缀字符“aaaaaaa”与后缀“aaaaaaa”相等,所以next[9]=8。
KMP算法的优化
后来有人发现,KMP还是有缺陷的。比如,如果我们的主串S="aaaabcde",子串T="aaaaax",其next数组值分别为012345,在开始时,当i=5、j=5时,我们发现“b”与“a”不相等,如图5-7-6的①,因此j=next[5]=4,如图中的②,此时“b”与第4位置的“a”依然不等,j=next[4]=3,如图中的③,后依次是④⑤,直到j=next[1]=0时,根据算法,此时i++、j++,得到i=6、j=1,如图中的⑥。
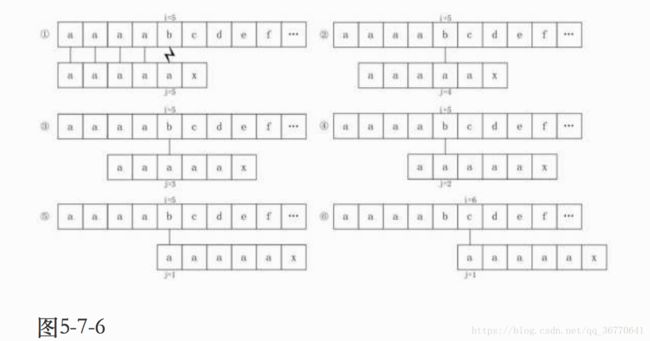
我们发现,当中的②③④⑤步骤,其实是多余的判断。由于T串的第二、三、四、五位置的字符都与首位的“a”相等,那么可以用首位next[1]的值去取代与它相等的字符后续next[j]的值,这是个很好的办法。因此我们对求next函数进行了改良。
nextval数组值推导
改良后,我们之前的例子nextval值就与next值不完全相同了。比如:
1.T="ababaaaba"
j 123456789
模式串T ababaaaba
next[j] 011234223
nextval[j] 010104210
先算出next数组的值分别为011234223,然后再分别判断。
1)当j=1时,nextval[1]=0;
2)当j=2时,因第二位字符“b”的next值是1,而第一位就是“a”,它们不相等,所以nextval[2]=next[2]=1,维持原值。
3)当j=3时,因为第三位字符“a”的next值为1,所以与第一位的“a”比较得知它们相等,所以nextval[3]=nextval[1]=0;如图5-7-7所示。

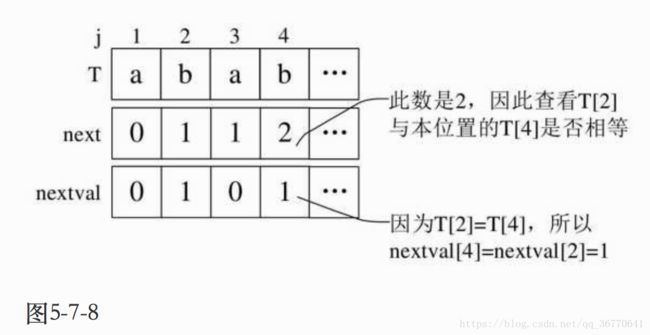
4)当j=4时,第四位的字符“b”next值为2,所以与第二位的“b”相比较得到结果是相等,因此nextval[4]=nextval[2]=1;如图5-7-8所示。
5)当j=5时,next值为3,第五个字符“a”与第三个字符“a”相等,因此nextval[5]=nextval[3]=0;
6)当j=6时,next值为4,第六个字符“a”与第四个字符“b”不相等,因此nextval[6]=4;
7)当j=7时,next值为2,第七个字符“a”与第二个字符“b”不相等,因此nextval[7]=2;
8)当j=8时,next值为2,第八个字符“b”与第二个字符“b”相等,因此nextval[8]=nextval[2]=1;
9)当j=9时,next值为3,第九个字符“a”与第三个字符“a”相等,因此nextval[9]=nextval[3]=0。
2.T="aaaaaaaab"
j 123456789
模式串T aaaaaaaab
next[j] 012345678
nextval[j] 000000008
先算出next数组的值分别为012345678,然后再分别判断。
1)当j=1时,nextval[1]=0;
2)当j=2时,next值为1,第二个字符与第一个字符相等,所以nextval[2]=nextval[1]=0;
3)同样的道理,其后都为0……;
4)当j=9时,next值为8,第九个字符“b”与第八个字符“a”不相等,所以nextval[9]=8。
总结改进过的KMP算法,它是在计算出next值的同时,如果a位字符与它next值指向的b位字符相等,则该a位的nextval就指向b位的nextval值,如果不等,则该a位的nextval值就是它自己a位的next的值。