爬虫(五十九)正则表达式语法(五十)
这一部分是正则表达式的通用语法,和Python实现无关。
正则表达式本质上只做一件事,那就是编写一个表达式“字符串”,然后用这个字符串去匹配目标文本。核心的核心,都在编写这个“字符串”表达式上面。
注意:文中讨论的所有字符都是英文半角字符,和中文字符没有一毛钱关系!千万不要写成中文标点符号。
一、普通字符
字母、数字、汉字、下划线、以及没有特殊定义的符号,都是"普通字符"。正则表达式中的普通字符,在匹配的时候,只匹配与自身相同的一个字符。
例如:表达式c,在匹配字符串abcde时,匹配结果是:成功;匹配到的内容是c;匹配到的位置开始于2,结束于3。(注:下标从0开始还是从1开始,因当前编程语言的不同而可能不同)
二、元字符
正则表达式中使用了很多元字符,用来表示一些特殊的含义或功能。
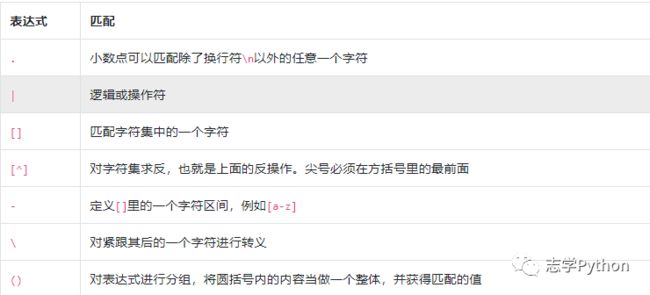
例如:
a.c匹配abc
(a|b)c匹配ac与bc
[abc]1匹配a1或者b1或者c1
使用方括号[]包含一系列字符,能够匹配其中任意一个字符。用[^]包含一系列字符,则能够匹配其中字符之外的任意一个字符。
[ab5@]匹配a或b或5或@
[^abc]匹配a,b,c之外的任意一个字符
[f-k]匹配f~k 之间的任意一个字母
[^A-F0-3]匹配A~F以及0~3之外的任意一个字符
三、转义字符
一些无法书写或者具有特殊功能的字符,采用在前面加斜杠"\"进行转义的方法。例如下表所示:
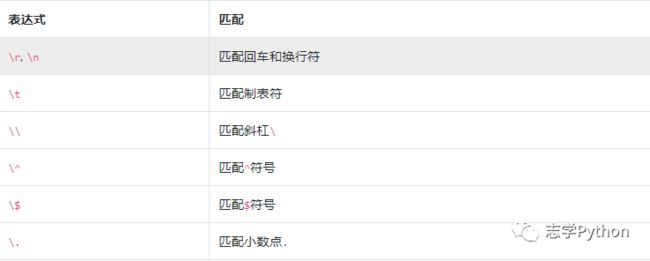
尚未列出的还有问号?、星号*和括号等其他的符号。所有正则表达式中具有特殊含义的字符在匹配自身的时候,都要使用斜杠进行转义。这些转义字符的匹配方法与普通字符类似,也是匹配与之相同的一个字符。
例如表达式\$d,在匹配字符串"abc$de"时,匹配结果是:成功;匹配到的内容是$d;匹配到的位置开始于3,结束于5。
四、预定义匹配字符集
正则表达式中的一些表示方法,可以同时匹配某个预定义字符集中的任意一个字符。比如,表达式\d可以匹配任意一个数字。虽然可以匹配其中任意字符,但是只能是一个,不是多个。如下表所示,注意大小写:

例如表达式\d\d,在匹配abc123时,匹配的结果是:成功;匹配到的内容是12;匹配到的位置开始于3,结束于5。
五、重复匹配
前面的表达式,无论是只能匹配一种字符的表达式,还是可以匹配多种字符其中任意一个的表达式,都只能匹配一次。但是有时候我们需要对某个片段进行重复匹配,例如手机号码13666666666,一般的新手可能会写成\d\d\d\d\d\d\d\d\d\d\d(注意,这不是一个恰当的表达式),不但写着费劲,看着也累,还不一定准确恰当。
这种情况可以使用表达式再加上修饰匹配次数的特殊符号{},不用重复书写表达式就可以重复匹配。比如[abcd][abcd]可以写成[abcd]{2}。
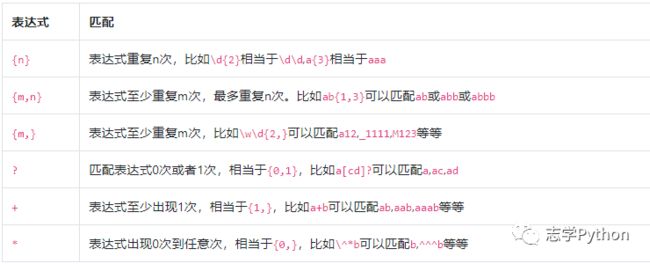
其中有些例子一定要注意!比如ab{1,3}中重复的是b而不是ab,(ab){1,3}这样重复的才是ab。表达式\^*b中重复的是\^而不是^,要从左往右读正则表达式,转义符号有更高的优先级,需要和后面的字符整体认读。
表达式\d+\.?\d*在匹配It costs $12.5时,匹配的结果是:成功;匹配到的内容是12.5;匹配到的位置开始于10,结束于14。
表达式go{2,8}gle在匹配Ads by goooooogle时,匹配的结果是:成功;匹配到的内容是goooooogle;匹配到的位置开始于7,结束于17。
六、位置匹配
有时候,我们对匹配出现的位置有要求,比如开头、结尾、单词之间等等。

例如表达式^aaa在匹配xxx aaa xxx时,匹配结果是:失败。因为^要求在字符串开始的地方匹配。
表达式aaa$在匹配xxx aaa xxx时,匹配结果是:失败。因为$要求在字符串结束的地方匹配。
表达式.\b.在匹配@@@abc时,匹配结果是:成功;匹配到的内容是@a;匹配到的位置开始于2,结束于4。
表达式\bend\b在匹配weekend,endfor,end时,匹配结果是:成功;匹配到的内容是end;匹配到的位置开始于15,结束于18。
七、贪婪与非贪婪模式
在重复匹配时,正则表达式默认总是尽可能多的匹配,这被称为贪婪模式。比如,针对文本dxxxdxxxd,表达式(d)(\w+)(d)中的\w+将匹配第一个d和最后一个d之间的所有字符xxxdxxx。可见,\w+在匹配的时候,总是尽可能多的匹配符合它规则的字符。同理,带有?、*和{m,n}的重复匹配表达式都是尽可能地多匹配。
但是有时候,这种模式不是我们想要的结果,比如最常见的HTML标签匹配。假设有如下的字符串:
苹果
桃子
香蕉
我们的意图是获取每个(.*) 苹果 桃子 香蕉
那么怎么办呢?使用非贪婪模式!
在修饰匹配次数的特殊符号后再加上一个?问号,则可以使匹配次数不定的表达式尽可能少的匹配,使可匹配可不匹配的表达式,尽可能的"不匹配"。如果少匹配就会导致整个表达式匹配失败的时候,与贪婪模式类似,非贪婪模式会最小限度的再多匹配一些,以使整个表达式匹配成功。
表达式(.*?) 苹果 桃子
针对文本"dxxxdxxxd"举例:
表达式(d)(\w+?)中的\w+?将尽可能少的匹配第一个d之后的字符,结果是只匹配了一个"x",整体只匹配了dx。
表达式(d)(\w+?)(d)为了让整个表达式匹配成功,\w+?不得不匹配xxx才可以让后边的d匹配,从而使整个表达式匹配成功。因此,结果是\w+?匹配了xxx,整体匹配了dxxx。
八、反向引用
表达式在匹配时,表达式引擎会将小括号()包含的表达式所匹配到的字符串记录下来。在获取匹配结果的时候,小括号包含的表达式所匹配到的字符串可以单独获取。这是一个非常有用也非常重要的特性。在实际应用场合中,当用某种边界来查找,而所要获取的内容又不包含边界时,必须使用小括号来指定所要的范围。比如前面的 (.*?) "
其实,"小括号包含的表达式所匹配到的字符串"不仅是在匹配结束后才可以使用,在匹配过程中也可以使用。表达式后边的部分,可以引用前面"括号内的子匹配已经匹配到的字符串"。引用方法是\加上一个数字。\1引用第1对括号内匹配到的字符串,\2 引用第2对括号内匹配到的字符串……以此类推,如果一对括号内包含另一对括号,则外层的括号先排序号。换句话说,哪一对的左括号"("在前,那这一对就先排序号。举例如下:
表达式('|")(.*?)(\1)在匹配'Hello', "World"时,匹配结果是:成功;匹配到的内容是'Hello'。再次匹配下一个时,可以匹配到 "World"。这里的(\1),动态的引用了('|")匹配到的结果。
表达式(\w)\1{4,}在匹配aa bbbb abcdefg ccccc 111121111 999999999时,匹配结果是:成功;匹配到的内容是ccccc。再次匹配下一个时,将得到999999999。这个表达式要求\w范围的字符至少重复5次,注意与\w{5,}之间的区别。
表达式<(\w+)\s*(\w+(=('|").*?\4)?\s*)*>.*?在匹配与
九、常用正则表达式
下面是网络上收集的一些常用正则表达式,请参考使用。PS:各位在复制粘贴的时候务必要小心前后多余的空格!
校验数字的相关表达式:
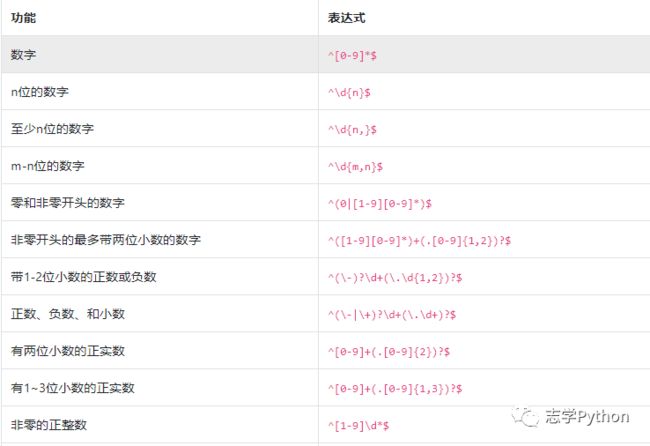
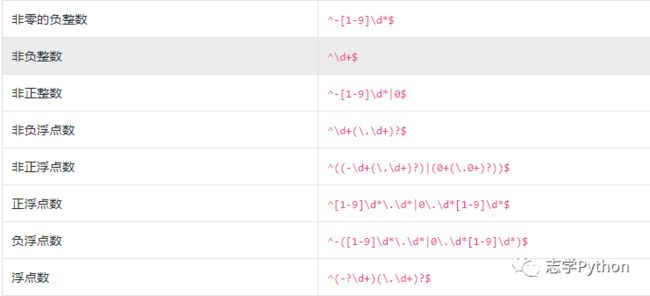
校验字符的相关表达式:
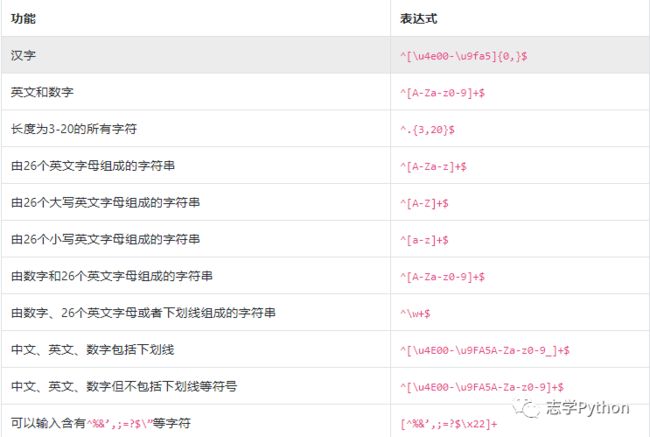
特殊场景的表达式:
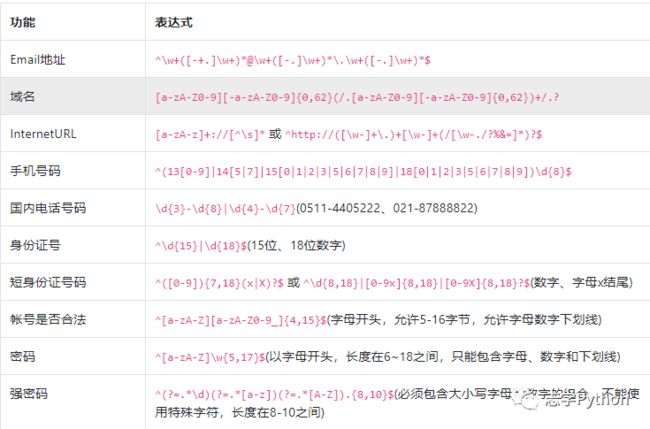
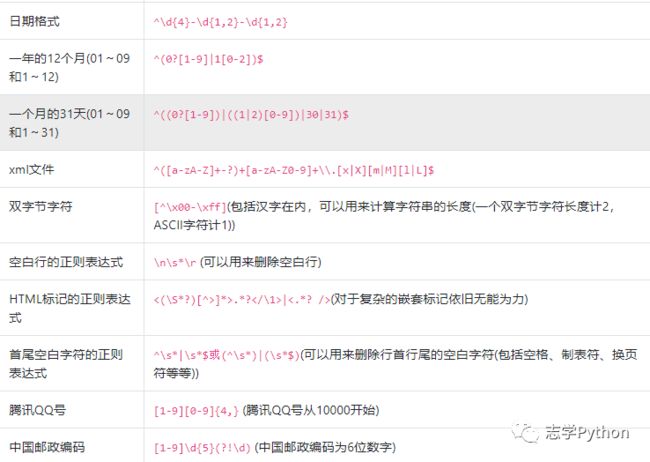

十、总结
关于正则表达式还有更多的高级用法和特性,不过对于这部分内容,各个不同的正则引擎在细节上有点不同,因此就不深入介绍了,有需要的同学,可以自行查看对应版本的说明文档。
请继续关注我

记得点赞加关注哦,记得加鸡腿啊