基于图的PersonalRank算法原理及Python实现
目录
- 1 相关说明
- 2 PersonalRank算法原理
- 3 代码
- 3.1 随机游走多次实现
- 3.2 矩阵化实现
1 相关说明
- TopN推荐问题
- 在基于图模型的推荐算法中,二分图(u,i)表示用户u对电影i评分过,即用户u观看了电影i。那么给用户u推荐电影的任务可以转化为度量用户顶点Vu和Vu没有边直接相连的电影节点在图上的相关性。
- 相关性高的顶点一般有如下特性:两个顶点有很多路径相连;连接两个顶点之间的路径长度比较短;连接两个顶点之间的路径不会经过出度较大的顶点。
2 PersonalRank算法原理
从用户u节点开始随机游走,游走到一个节点时,首先按照概率α决定是否继续游走,还是停止这次游走并从Vu节点开始重新游走。如果决定继续游走,那么就从当前节点指向的节点中按照均匀分布随机选择一个节点作为下次经过的节点,每个电影节点被访问的概率收敛到一个数,这个数越大,这个电影就越被推荐。
可以理解成用户u节点的重要性是1,通过随机游走将u节点的重要性分给了其他节点。
在执行算法之前,我们需要初始化每个节点的初始概率值。如果我们对用户u进行推荐,则令u对应的节点的初始访问概率为1,其他节点的初始访问概率为0,然后再使用迭代公式计算。迭代公式如下,其中i代表某个节点,α代表每次游走的概率。
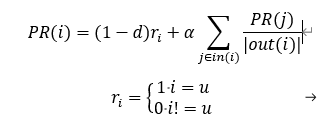
以上随机游走的算法难点是时间复杂度高,可以通过矩阵论重新设计算法,对稀疏矩阵快速求逆。
![]()
rij代表节点i对于节点j的PR值;r0是对角线为1,其他元素为0的矩阵;M是概率转移矩阵,Mij代表节点j分得节点i的访问概率,如果i指向j的话,取值为i出度的倒数,否则取值为0。![]()
其中(E-αM^T )^(-1) (1-α)可以看做所有顶点的推荐结果,删除所有用户节点行和电影节点列,就可以得到以用户为列、电影为行的访问概率矩阵r。对于每位用户,取对应列的所有行,按照PR值排序即可为其推荐。
3 代码
3.1 随机游走多次实现
import pandas as pd
import numpy as np
import math
import pickle
import random
import time
#写数据
def writeFile(data,path):
with open(path, "wb") as f:
pickle.dump(data, f)
#读数据
def readFile(path):
with open(path, "rb") as f:
return pickle.load(f)
#获得用户电影 的两个字典
def getDict(train_data):
user2mv={}
mv2user={}
for index,item in train_data.iterrows():
uid,mid=item['UserID'],item['MovieID']
user2mv.setdefault(uid,[]).append(mid)
mv2user.setdefault(mid,[]).append(uid)
return user2mv,mv2user
#随机游走
def personalRank(train_data,alpha,N):
user2mv,mv2user=getDict(train_data)
users=list(user2mv.keys())
movies=list(mv2user.keys())
#一个columns代表 一个用户
PR_movie=pd.DataFrame(data=np.zeros([len(movies),len(users)]),index=movies,columns=users)#mu 代表m对于u的重要性
PR_user=pd.DataFrame(data=np.eye(len(users)),index=users,columns=users)#u1u2 代表u1对于u2的重要性
num,sum=0,len(users)
#对于每一个用户进行N次随机游走
for user in users:
start=time.clock()
node_list=['u'+user]#u1代表id为1的用户 m1代表id为1的电影 u/m区分node的类型
for step in range(0,N):#随机游走N次
#print(node_list)
PR_movie_tmp={m:0 for m in movies}
PR_user_tmp={u:0 for u in users}
node_list_tmp=[]
#遍历 pr不为0的用户或电影节点 (取出它们的出边)
for node in node_list:
#当节点是用户节点时 其指向电影
if(node[0:1]=='u'):
id=node[1:]
out=len(user2mv[id])
for m in user2mv[id]:
PR_movie_tmp[m]+=alpha*PR_user.loc[id][user]/out
m='m'+m
if(m not in node_list and m not in node_list_tmp):
node_list_tmp.append(m)
#当结点是电影节点时 其指向用户
else:
id=node[1:]
out=len(mv2user[id])
for u in mv2user[id]:
PR_user_tmp[u]+=alpha*PR_movie.loc[id][user]/out
u='u'+u
if(u not in node_list and u not in node_list_tmp):
node_list_tmp.append(u)
#一次随机游走结束 更新pr
PR_user_tmp[user]+=(1-alpha)
PR_user[user]=pd.Series(PR_user_tmp)
PR_movie[user]=pd.Series(PR_movie_tmp)
node_list.extend(node_list_tmp)
num+=1
print('user:{} ok! {}/{}'.format(user,num,sum))
end=time.clock()
print('cost time:{}'.format(end-start))
writeFile(PR_movie,'./PR_movie.file')
writeFile(PR_user,'./PR_user.file')
#测试 给用户user随机游走
def pr_test(train_data,user,alpha,N):
user2mv,mv2user=getDict(train_data)
users=list(user2mv.keys())
movies=list(mv2user.keys())
PR_movie={m:0 for m in movies}
PR_user={u:0 for u in users}
PR_user[user]=1 #初始化
node_list=[user]#节点的顺序
node_type=[True]#节点的类型 true为user false为movie
for step in range(0,N):
print(step)
#print(node_list)
print(PR_movie)
PR_movie_tmp={m:0 for m in movies}
PR_user_tmp={u:0 for u in users}
node_list_tmp,node_type_tmp=[],[]
#遍历 pr不为0的用户或电影节点 (取出它们的出边)
for i in range(0,len(node_list)):
node=node_list[i]
ntype=node_type[i]
#当节点是用户节点时 其指向电影
if(ntype):
for m in user2mv[node]:
out=len(user2mv[node])
if(m not in node_list and m not in node_list_tmp):
node_list_tmp.append(m)
node_type_tmp.append(False)
PR_movie_tmp[m]+=alpha*PR_user[node]/out
#当结点是电影节点时 其指向用户
else:
for u in mv2user[node]:
out=len(mv2user[node])
if(u not in node_list and u not in node_list_tmp):
node_list_tmp.append(u)
node_type_tmp.append(True)
PR_user_tmp[u]+=alpha*PR_movie[node]/out
#一次随机游走结束 更新pr
PR_user_tmp[user]+=(1-alpha)
PR_user=PR_user_tmp
PR_movie=PR_movie_tmp
node_list.extend(node_list_tmp)
node_type.extend(node_type_tmp)
train_data,test_data=readFile(./train_data.file'),readFile('./test_data.file')
train_data[['UserID','MovieID']]=train_data[['UserID','MovieID']].astype(str)
#这是测试
#test=[
# ['A','a'],['A','c'],['B','a'],['B','b'],['B','c'],['B','d'],['C','c'],['C','d']
# ]
#train_data_test=pd.DataFrame(data=test,columns=['UserID','MovieID'])
#pr_test(train_data_test,'C',0.85,100)
personalRank(train_data,0.8,20)#这是最终的运行
3.2 矩阵化实现
import pandas as pd
import numpy as np
import math
import pickle
import random
import time
#写数据
def writeFile(data,path):
with open(path, "wb") as f:
pickle.dump(data, f)
#读数据
def readFile(path):
with open(path, "rb") as f:
return pickle.load(f)
#获得用户电影 的两个字典
def getDict(train_data):
user2mv={}
mv2user={}
for index,item in train_data.iterrows():
uid,mid='u'+item['UserID'],'m'+item['MovieID']
user2mv.setdefault(uid,[]).append(mid)
mv2user.setdefault(mid,[]).append(uid)
return user2mv,mv2user
#随机游走
def personalRank(train_data,alpha):
user2mv,mv2user=getDict(train_data)
users=list(user2mv.keys())
movies=list(mv2user.keys())
unum,mnum=len(users),len(movies)
M=pd.DataFrame(data=np.zeros([unum+mnum,unum+mnum]),index=users+movies,columns=users+movies)
for u,mlist in user2mv.items():
out=len(mlist)
for m in mlist:
M.loc[u][m]=1/out
for m,ulist in mv2user.items():
out=len(ulist)
for u in ulist:
M.loc[m][u]=1/out
PR=np.eye(unum+mnum)-alpha*np.array(M).T
PR=np.linalg.inv(PR)*(1-alpha)
PR=pd.DataFrame(data=PR,index=users+movies,columns=users+movies)
PR.drop(columns=movies,inplace=True)
PR.drop(index=users,inplace=True)
#去除uid mid中另外加的"u" "m"
ulist,mlist=[],[]
for u in users:
ulist.append(u[1:])
for m in movies:
mlist.append(m[1:])
PR.index=mlist
PR.columns=ulist
return PR#[movie×user]
from MyFunction import Helper
from MyFunction import RecommendFunction
train_data,test_data=readFile('./train_data.file'),readFile('./test_data.file')
train_data[['UserID','MovieID']]=train_data[['UserID','MovieID']].astype(str)
test_data[['UserID','MovieID']]=test_data[['UserID','MovieID']].astype(str)
PR=personalRank(train_data,0.5)
predict=rf.getScoreTopk(PR,10)
参考:
- https://www.cnblogs.com/hellojamest/p/11763033.html 个人认为这篇文章写的很不错
- https://www.cnblogs.com/james1207/p/3266684.html