XSS语义分析的阶段性总结(一)
前言
由于X3Scan的研发已经有些进展了,所以对这一阶段的工作做一下总结!对于X3Scan的定位,我更加倾向于主动+被动的结合。主动的方面主要体现在可以主动抓取页面链接并发起请求,并且后期可能参考XSStrike加入主动fuzz的功能,这个目前还未加入,正在纠结中。而被动的方面,主要的工作就是xss语义分析的研究,通过xss语义分析而不是盲目的使用payload进行fuzz。
语义分析
业内提的比较早的一款waf产品,语义分析说白了就是根据上下文来进行分析,而不是通过正则搜索的方式来匹配污染源,也就是我们的漏洞触发点。
由于这个需求,我们需要开发一款可以理解上下文的工具。来帮助我们识别我们的payload是输出在什么样的语义环境,从而给出精确的payload,而这一点xray目前做的效果挺不错的。
AST语法树
在此之前我们先简单了解一下JS抽象语法树。
Javascript 代码的解析(Parse )步骤分为两个阶段:词法分析(Lexical Analysis)和 语法分析(Syntactic Analysis)。这个步骤接收代码并输出抽象语法树,亦称 AST
在分析 Javascript 的 AST 过程中,借助于工具 AST Explorer 能帮助我们对 AST 节点有一个更好的感性认识。
下面是AST Explorer对 Javascript代码的解析,经过AST Explorer的解析Javascript代码会被抽象成AST的形式。

下面简单介绍几个节点类型,更多的参考官方文档定义https://esprima.readthedocs.io/en/3.1/syntax-tree-format.html
使用下面的demo为例
var param = location.hash.split("#")[1];
document.write("Hello " + param + "!");
VariableDeclaration
变量声明,kind 属性表示是什么类型的声明,因为 ES6 引入了 const/let。declarations 表示声明的多个描述,因为我们可以这样:let a = 1, b = 2;

VariableDeclarator
变量声明的描述,id 表示变量名称节点,init 表示初始值的表达式,可以为 null

Identifier
标识符,就是我们写 JS 时自定义的名称,如变量名,函数名,属性名,都归为标识符

一个标识符可能是一个表达式,或者是解构的模式(ES6 中的解构语法)。
Literal
字面量,就代表了一个值的字面量,如 “hello”, 1 这些,还有正则表达式(有一个扩展的 Node 来表示正则表达式),如 /\d?/
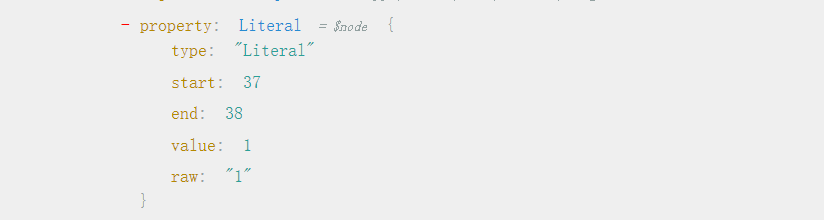

value 这里即对应了字面量的值,我们可以看出字面量值的类型,字符串,布尔,数值,null 和正则。
BinaryExpression
由于这里存在两个个二元运算,所以简单再介绍其中一个,其它的便不多简绍。
二元运算表达式节点,left 和 right 表示运算符左右的两个表达式,operator 表示一个二元运算符。

这里进行运算的一个是Literal类型也就是hello,一个是Identifier类型也就是param变量,运算符为+
AST的介绍先到这里。下面介绍一下检测的原理
检测原理
xss漏洞一般有两种检测方法,第一种是简单粗暴的使用收集来的payload进行fuzz,通过页面是否回显来判断是否存在漏洞,这种手段目前已经不适用了。另一种就是通过对返回页面进行解析,结合语义分析,根据输出在不同的上下文来选择发送我们的payload,这样的话,我们的payload即精巧又准确。
还是使用这个demo
var param = location.hash.split("#")[1];
document.write("Hello " + param + "!");
检测思路一般为,我们首先找到document.write这个函数,从而定位到param,由param我们可以进行回溯到location.hash.split("#")[1],从而证明触发点是可控的。在污点分析模型里面,我们称document.write为sink,也就是污点汇聚点,代表直接产生安全敏感操作(违反数据完整性)或者泄露隐私数据到外界(违反数据保密性),称location.hash.split("#")[1]为source,也就是污点源,代表直接引入不受信任的数据或者机密数据到系统中。很多代码审计工具也是基于了这样的模型。
基于上面的分析,我们需要开发一个可以理解js上下文的工具,帮助我们找到sink和source,让我们可以由sink回溯source,或者由反过来亦可,正则上实现这个问题已经基本不可能了,我们需要能够给上下文赋予准确意义。
而上面的AST语法树可以满足我们的需求,因为它可以帮助我们分析xss的输出点的上下文
幸运的是python里面有将js代码解析为语法树的库pyjsparser,还有在其基础上实现的js2py
from pyjsparser import parse
import json
js = '''
var param = location.hash.split("#")[1];
document.write("Hello " + param + "!");
'''
ast = parse(js)
print(json.dumps((ast)))
解析出来的效果跟AST Explorer是一致的
接下来我们需要设计一个递归来找到每个表达式,每一个Identifier和Literal类型等等。
部分代码如下:
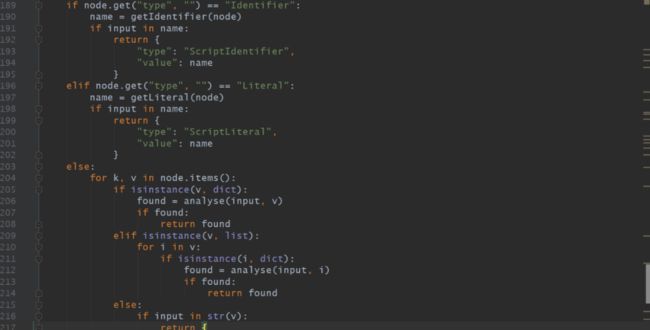
然后再遍历body的节点,找寻输出位置

仍是上面的demo,我们尝试找到Hello


输出结果如下:
![]()
我们找到了Hello,并且输出位置的上下文为Literal
有了上面的研究,通过sink回溯source的方法便可以实现,对于dom型xss的分析,也会更加精确,对于反射型xss输出在js的情况,同样适用
如果回显在JS脚本中,发送测试payload后,通过js语法树解析确定Identifier和Literal这两个类型中是否包含,如果payload是Identifier类型,就可以直接判断存在xss,如果payload是Literal类型,再通过单双引号来测试是否可以闭合。
最后
关于js语义分析暂时先分析到这里,难点还是dom型xss的检测,因为dom xss检测识别有点复杂,下一篇会探讨一下sink输出在html的情况,探讨一下html解析的一些问题。
"
复制链接做实验:XSS进阶一
http://hetianlab.com/expc.do?ce=2626aa4d-704e-4190-a80e-c14d1d47e88c
(恶意攻击者往Web页面里插入恶意html代码,当用户浏览该页之时,嵌入其中Web里面的html代码会被执行,从而形成XSS攻击)
"
点击这里阅读原文