Hive知识点总结(面试)
目录
Hive元数据为何不存放在内置的derby数据库中?
Hive中的四种排序?
Hive与MySQL数据库区别?
HQL的执行流程?
Hive 工作原理?
内部表与外部表?
Hive分组排序的方式?
Hive中的文件格式?
Hive中的分区和分桶?
lateral view 与 explode函数?
Hive表关联查询时的数据倾斜?
Hive中的谓词下推(PPD)?
Hive中Mapper与Reducer的数量?
Hive中有哪些复合数据类型?
Hive元数据为何不存放在内置的derby数据库中?
Hive 将元数据存储在 RDBMS 中,一般常用 MySQL 和 Derby。默认情况下,Hive 元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的测试。实际生产环境中不适用, 为了支持多用户会话,则需要一个独立的元数据库,使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
内置的derby主要问题是并发性能很差,可以理解为单线程操作。Derby还有一个特性,元数据保存在当前目录下,也就说更换目录执行操作,会找不到相关表,比如在/usr下执行创建表,在/usr下可以找到这个表。在/etc下执行查找这个表,就会找不到。
Hive中的四种排序?
order by
全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
set hive.mapred.mode默认为nonstrict,在strict模式下使用order by必须执行limit,否则报错
sort by
如果用sort by进行排序,并且设置mapred.reduce.tasks>1, 则sort by只保证每个reducer的输出有序,不保证全局有序。
distribute by
按照指定的字段对数据进行划分到不同的输出reduce中。通常与sort by搭配使用,比如对同一年份中的温度进行排序:distribute by year sort by temperature,distribute by保证了同一reducer中接受到的是同一年份的数据,而sort by是对reducer排序
cluster by
当distribute by和sorts by的字段相同时,可以使用cluster by方式;cluster by 同时具有 distribute by 和 sort by 的功能。 但是排序只能是升序排序,不能够指定。
Hive与MySQL数据库区别?
1)产品定位
Hive是数据仓库,是为海量数据的离线分析设计的,实时性查。所以不支持OLTP(联机事务处理)所需的关键功能ACID,而更接近于OLAP(联机分析技术),适合离线处理大数据集,虽然还未满足OLAP中OL部分;
而MySQL是关系型数据库,是为实时业务设计的。
2)存储的文件系统 / 可扩展性
Hive中的数据存储在HDFS(Hadoop的分布式文件系统),metastore元数据一般存储在独立的关系型数据库中,而MySQL则是服务器本地的文件系统;因此Hive具有良好的可扩展性,数据库由于ACID语义的严格限制,扩展性十分有限。
3)读写模式
MySQL为写时模式,数据在写入数据库时对照模式检查。写时模式有利于提升查询性能,因为数据库可以对列进行索引。
Hive为读时模式,数据的验证则是在查询时进行的,这有利于大数据集的导入,读时模式使数据的加载非常迅速,数据的加载仅是文件复制或移动。
4)数据更新
Hive是针对数据仓库应用设计的,而数仓的内容是读多写少的,Hive中不支持对数据进行改写,所有数据都是在加载的时候确定好的;而数据库中的数据通常是需要经常进行修改的。
5)数据格式
Hive中数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、"\t"、"\x001")、行分隔符("\n")以及读取文件数据的方法(Hive中文件格式: TextFile,SequenceFile、RCFILE、ORCFile)。
而在MySQL数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
6)索引
Hive只提供了有限的索引功能,可以为一些字段建立索引,一张表的索引数据存储在另外一张表中。由于数据的访问延迟较高,Hive不适合在线数据查询;数据库在少量的特定条件的数据访问中,索引可以提供较低的延迟。
Hive要访问数据中特定数据时,需要全表扫描,因此访问延迟较高。由于MapReduce的引入,Hive可以并行访问数据,在大数据的访问上仍然具有优势。
7)计算模型
Hive使用的模型是MapReduce(也可以 on spark),而MySQL使用的是自己设计的Executor计算模型
HQL的执行流程?
1)输入一条HQL查询语句
2)解析器对这条Hql语句进行语法分析。
3)编译器对这条Hql语句生成HQL的执行计划。
4)优化器生成最佳的Hql的执行计划。
5)执行这条最佳Hql语句。

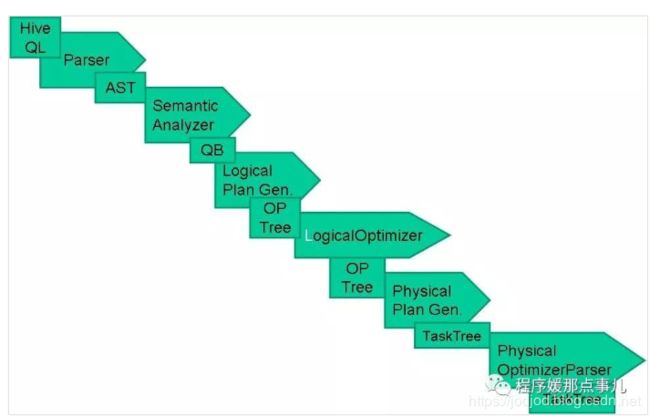
Hive 工作原理?
1)用户提交查询等任务给Driver
2) 编译器获得该用户的任务Plan
3) 编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
4.)编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce), 最后选择最佳的策略。
5)将最终的计划提交给Driver。
6) Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给NodeManager执行该任务,任务会直接读取HDFS中文件进行相应的操作。
7) 获取执行的结果。
8) 取得并返回执行结果。
内部表与外部表?
Managed Table(内部表)
Managed Table 的数据,会存放在 HDFS 中的特定的位置中,通常是 /user/username/hive/warehouse。;当删除表时,数据文件也会一并删除;适用于临时创建的中间表
External Table(外部表)
适用于想要在 Hive 之外使用表的数据的情况.当你删除 External Table 时,只是删除了表的元数据,它的数据并没有被删除。适用于数据多部门共享。建表时create external table...
Hive分组排序的方式?
1)rank() over:跳跃排序,成绩相同的两名是并列,下一位空出所占的名次,两个并列的第二名后是第四名
2)dense_rank() over:两个并列的第二名后是第三名
3)row_number() over:没有重复值的排序,即第几行
rank() over 的时候,空值是最大的,如果排序字段为 null,可能造 成 null 字段排在最前面,影响排序结果。可以使用
rank() (... over... nulls last)来规避这个问题
//根据科目对每个学生的乘积排序
select name,subject,score,rank() over(partition by subject order by score desc nulls last) from student_score;Hive中的文件格式?
| 文件格式 |
TextFile |
SequenceFIle |
RCFile |
| 数据类型 |
字节 |
字节或二进制 |
字节或二进制 |
| 内部存储格式 |
行式 |
行式 |
列式 |
| 压缩形式 |
File Based |
Block Based |
Block Based |
| 可否拆分 |
YES |
YES |
YES |
| 压缩后可否拆分 |
NO |
YES |
YES |
| 描述 | 磁盘开销大,数据解析开销大 | 以键值对的形式序列化到文件中,优势是文件和hadoop api中相互兼容的。 | 数据按行分块,每块按照列存储,压缩快,快速列存取。其中ORCFile是RCFile的改良版,效率更高 |
Hive中的分区和分桶?
HQL通过where字句来限制条件提取数据,那么遍历一张大表,不如将这张大表拆分成多个小表,并通过合适的索引来扫描表中的一小部分,分区和分桶都是采用了这种理念。
- 分区会创建物理目录,并且可以具有子目录(通常会按照时间、地区分区),目录名以
= 创建,分区名会作为表中的伪列,这样通过where字句中加入分区的限制可以在仅扫描对应子目录下的数据。通过partitioned by(field1 type,...) - 分桶可以继续在分区的基础上再划分小表,分桶根据哈希值来确定数据的分布(即MapReducer中的分区!),比如分区下的一部分数据可以根据分桶再分为多个桶,这样在查询时先计算对应列的哈希值并计算桶号,只需要扫描对应桶中的数据即可。通过 clustered by( field ) into n buckets
静态分区
按照年份、国家分区将日志表;先按year分区,后按country分区
hive (db1)> create table logs(id int,context string,time string,city string)
> partitioned by (year string,country string) row format delimited
> fields terminated by ',';
需手动指明分区
hive (db1)> load data local inpath '/home/jinge/2019.csv'
> into table logs partition (year='2019',country='china');
动态分区
通常分区的内容为表中的数据的一部分,一般创建完分区表后,会将基表导入到分区表中(注意列数要相同,别忘了伪列)
分桶
按照ymd字段分为5个桶,导入基表时对应5个reducer
hive (db1)> create table stocks_buckets(symbol string,ymd string)
> clustered by (ymd) into 5 buckets
> row format delimited fields terminated by ',';lateral view 与 explode函数?
explode,可以将array或map结构拆分成多行
hive (db1)> select * from wordcount;
word
["hi","hello"]
["nice","good"]
["hi","nice"]
["hi"]
hive (db1)> select w from wordcount lateral view explode(word) word as w;
w
hi
hello
nice
good
hi
nice
hi
hive (db1)> select explode(word) from wordcount;
col
hi
hello
nice
good
hi
nice
hi
hive (db1)> select w,count(1) as c from wordcount lateral view explode(word) word as w group by w order by c desc;
w c
hi 3
nice 2
hello 1
good 1
Hive表关联查询时的数据倾斜?
倾斜原因:map输出数据按key Hash的分配到reduce中,由于以下原因造成的reduce 上的数据量差异过大
- key分布不均匀
- 业务数据本身的特性
- 建表时考虑不周
- 某些SQL语句本身就有数据倾斜
其实Hive的优化即为MapReduce的优化
1)hive.map.aggr = true + hive.groupby.skewindata=true
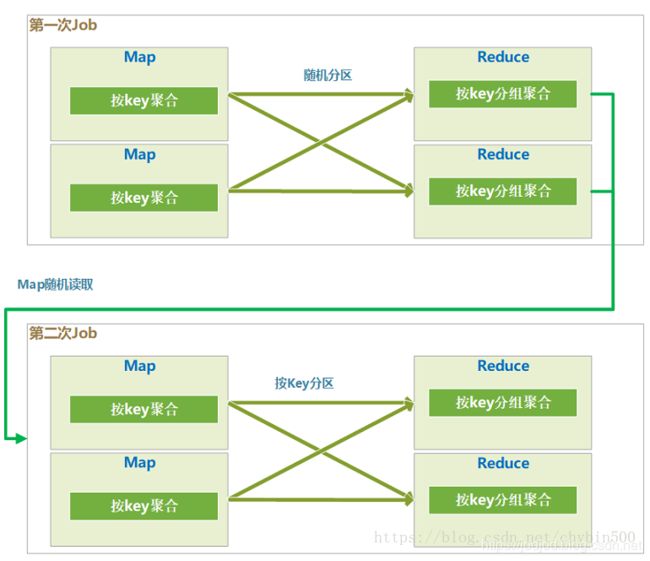
- 会生成两个job来执行group by,第一个job中,各个map是平均读取分片的,在map阶段对这个分片中的数据根据group by 的key进行局部聚合操作,这里就相当于Combiner操作。
- 在第一次的job中,map输出的结果随机分区,这样就可以平均分到reduce中
- 在第一次的job中,reduce中按照group by的key进行分组后聚合,这样就在各个reduce中又进行了一次局部的聚合。
- 因为第一个job中分区是随机的,所有reduce结果的数据的key也是随机的,所以第二个job的map读取的数据也是随机的key,所以第二个map中不存在数据倾斜的问题。
- 在第二个job的map中,也会进行一次局部聚合。
- 第二个job中分区是按照group by的key分区的,这个地方就保证了整体的group by没有问题,相同的key分到了同一个reduce中。
- 7经过前面几个聚合的局部聚合,这个时候的数据量已经大大减少了,在最后一个reduce里进行最后的整体聚合。
2)选用join key 分布最均匀的表作为驱动表。做好列裁剪和filter操作,以达到两表join的时候,数据量相对变小的效果
3)小表Join大表: 使用map join让小的维度表(1000条以下的记录条数)先进内存。在Map端完成Reduce
4)空值的处理:在Hive中主键为 null 值的项会被当做相同的 Key 而分配进同一个计算 Map。把空值的Key变成一个字符串加上一个随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终的结果。
5)避免使用count(distinct):因为count(distinct)是按group by 字段分组,按distinct字段排序,一般这种分布方式是很倾斜的。可以使用count(1)和group by搭配
Hive中的谓词下推(PPD)?
谓词下推:是在不影响结果的情况下,尽量将过滤条件提前执行。谓词下推后,过滤条件在map端执行,减少了map端的输出,降低了数据在集群上传输的量,节约了集群的资源,也提升了任务的性能。
hive.optimize.ppd,默认为true
Hive中Mapper与Reducer的数量?
Mapper数量
num_map_tasks = max[${mapred.min.split.size},min(${dfs.block.size},${mapred.max.split.size})]- mapred.min.split.size: 指的是数据的最小分割单元大小;min的默认值是1B
- mapred.max.split.size: 指的是数据的最大分割单元大小;max的默认值是256MB
- dfs.block.size: 指的是HDFS设置的数据块大小。个已经指定好的值,而且这个参数默认情况下hive是识别不到的
通过调整max可以起到调整map数的作用,减小max可以增加map数,增大max可以减少map数。需要提醒的是,直接调整mapred.map.tasks这个参数是没有效果的。
Reducer数量
Reduce阶段优化的主要工作也是选择合适的reduce task数量, 与map优化不同的是,reduce优化时,可以直接设置mapred.reduce.tasks参数从而直接指定reduce的个数
num_reduce_tasks = min[${hive.exec.reducers.max},(${input.size}/${hive.exec.reducers.bytes.per.reducer})]- hive.exec.reducers.max:从Hive 0.14.0开始,默认值为1009,这个参数的含义是最多启动的Reduce个数
- hive.exec.reducers.bytes.per.reducer:从Hive 0.14.0开始,默认值变成了256M(256,000,000)。这个参数的含义是每个Reduce处理的字节数。比如输入文件的大小是1GB,那么会启动4个Reduce来处理数据。
Hive中有哪些复合数据类型?
1)Map
a.Map 复合数据类型提供了 key-value 对存储,你可以通过 key 获取 value。
b.zhangsan Math:90,Chinese:92,English:78
i.create table score_map(name string, score map) map keys terminated by ':';
ii.select name, score['English'], size(score) from score_map;
2)Struct
a.Struct 是不同数据类型元素的集合。
b.zhangsan Math,90
i.create table course_struct(name string, course struct) collection items terminated by ',';
ii.select name, course.score, course.course from course_struct;
3)Array
a.Array 是同类型元素的集合.
b.zhangsan beijing,shanghai,hangzhou
i.create table person_array(name string, work_locations array) collection items terminated by ',';
ii.select name, work_locations[0], size(work_locations) from person_array;