Python——使用 requests 模块爬取网页数据
使用requests模块爬取网页数据
文章目录
- 使用requests模块爬取网页数据
- @[toc]
- 1. 爬取静态页面数据
- 1.1 准备工作
- 1.2 各模块代码
- 1.3 完整代码
- 2. 爬取动态页面数据
- 2.1 准备工作
- 2.2 完整代码
- 2.3 补充说明(2019-07-29)
文章目录
- 使用requests模块爬取网页数据
- @[toc]
- 1. 爬取静态页面数据
- 1.1 准备工作
- 1.2 各模块代码
- 1.3 完整代码
- 2. 爬取动态页面数据
- 2.1 准备工作
- 2.2 完整代码
- 2.3 补充说明(2019-07-29)
以下内容根据个人学习总结
1. 爬取静态页面数据
对于一些静态页面而言,爬取相关数据比较简单,主要思路是首先获取网页链接,然后定位数据源码,最后获取其内容
以下任务目标为爬取盗墓笔记第一部全文,网页地址为盗墓笔记1:七星鲁王宫
1.1 准备工作
后续代码均在 Windows + python 3.7.2 实现,调试用的是 Pycharm Community ,实际上 Visual Studio Code 更加轻量,但是IDE比较适合刚入门的。
使用到的库包括 requests 和 bs4,如果没有安装这两个库,可以直接在cmd中使用下面的命令进行安装
pip install requests
pip install bs4
1.2 各模块代码
talk is cheap, show you the code
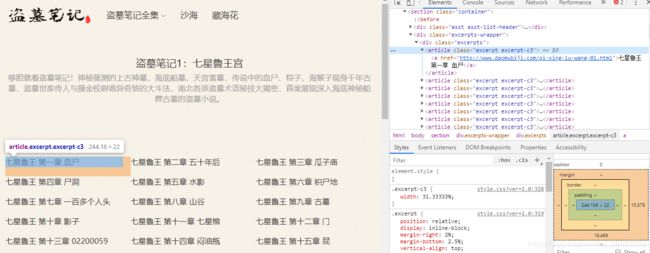
'''
该函数将获取目录页所有章节名及其对应链接
'''
def get_catalog(url):
# url = 'http://www.daomubiji.com/dao-mu-bi-ji-1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.content, 'lxml')
soup_catalog = soup.find_all('article', class_='excerpt excerpt-c3')
catalogs = BeautifulSoup(str(soup_catalog)).find_all('a')
names = []
hrefs = []
for c in catalogs:
names.append(c.text)
hrefs.append(c.attrs['href'])
return names, hrefs

'''
该函数将获取章节页主体文本
'''
def get_one_chapter(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.content, 'lxml')
soup_text = soup.find('article')
return soup_text.text
1.3 完整代码
有了上面2个函数,我们就可以组合起来获得整本书的内容,以下为最终实现代码
#!usr/bin/env python
# -*- encoding:utf-8 -*-
__author__ = 'xx'
__date__ = '2019-07-29'
import requests
from bs4 import BeautifulSoup
def get_catalog(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.content, 'lxml')
soup_catalog = soup.find_all('article', class_='excerpt excerpt-c3')
catalog = BeautifulSoup(str(soup_catalog), 'lxml').find_all('a')
names = []
hrefs = []
for c in catalog:
names.append(c.text)
hrefs.append(c.attrs['href'])
return names, hrefs
def get_one_chapter(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.content, 'lxml')
soup_text = soup.find('article')
return soup_text.text
def get_textbook(url):
text = ''
names, hrefs = get_catalog(url)
index = 1
for name, href in zip(names, hrefs):
content = get_one_chapter(href)
text += '第{0}章 {1}\n'.format(index, name) + content + '\n\n'
return text
def write_to_file(filepath, text):
with open(filepath, 'a+') as f:
f.write(text)
def main():
filepath = './Files/dmbj1.txt'
root_url = 'http://www.daomubiji.com/dao-mu-bi-ji-1'
write_to_file(filepath, get_textbook(root_url))
if __name__ == '__main__':
main()
2. 爬取动态页面数据
对于一些网页来说,其数据并不是在页面本身,而是当页面打开后页面调用js脚本与服务器进行交互,从而改变网页数据,也就是 ajax ,因此仅对目标页面发起普通的 get 请求是无法获得需要的数据的,这时候应该从网页加载找真正请求的目标
以下代码任务为抓取中国数据网的年度人口基本情况中的表格数据
2.1 准备工作
对于想要查找网页的网络活动,常用的是使用抓包工具(比如:Flidder)进行抓包,这里简单的使用 Chrome 浏览器的审查元素中的 Network 活动从而找到请求目标
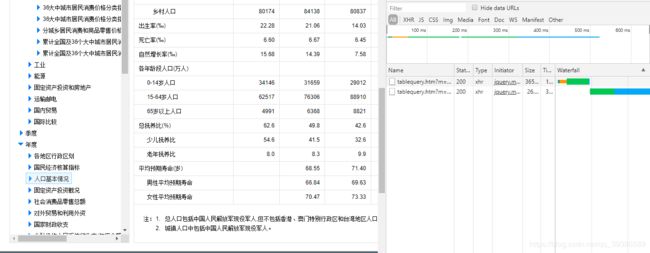
从该图中可以看出,当点击 人口基本情况 时,有两条XHR数据出现在 Network 中,通过对比可以发现,我们所需要的数据恰巧包含在 tablequery.htm?m=QueryData&code=AD03&wds=%5B%7B%22wdcode%22%3A%22reg%22%2C%22valuecode%22%3A%22000000%22%7D%5D 该条数据的 htmltable 中(通过查看Preview可以预览响应转化后的内容,通过查看Response可以查看响应的内容,是一个json数据格式。

故此,我们获得了数据真正的请求源为: http://data.stats.gov.cn/tablequery.htm?m=QueryData&code=AD03&wds=[{"wdcode"%3A"reg"%2C"valuecode"%3A"000000"}]
2.2 完整代码
动态网页数据一般都是 json 格式的字符串,因此还需要导入 json 库将 json 格式的字符串转化为 python 中的 dict 使用
有了前面的铺垫,这里直接上最终实现代码
#!usr/bin/env python
# -*- encoding:utf-8 -*-
__author__ = 'xx'
__date__ = '2019-07-29'
import requests
from bs4 import BeautifulSoup
import json
import pandas as pd
def main():
url = 'http://data.stats.gov.cn/tablequery.htm?m=QueryData&code=AD03&wds=%5B%7B%22wdcode%22%3A%22reg%22%2C%22valuecode%22%3A%22000000%22%7D%5D'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
response = requests.get(url, headers=headers)
data = json.loads(response.text)['htmltable']
soup = BeautifulSoup(data, 'lxml')
trs = soup.find_all('tr')
table = []
index = 1
for tr in trs:
row = []
if index == 1:
ts = tr.find_all('th')
else:
ts = tr.find_all('td')
for th in ts:
row.append(th.text)
table.append(row)
index += 1
df = pd.DataFrame(table)
df.to_excel('./Files/table.xlsx', index=False)
if __name__ == '__main__':
main()
2.3 补充说明(2019-07-29)
刚刚翻阅了一篇博客:Python requests模块params与data的区别,发现可以采用另一种方式获取 json 数据
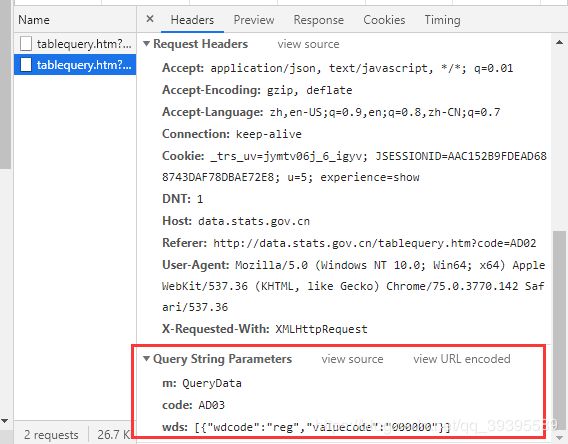
参照上图,调到 Headers 部分,往下找到 Request Headers,将这些作为 get 请求中的 headers 部分,然后翻到最下面有一个 Query String Parameters 这个就是数据源接口中传入的参数,如果使用过第三方api肯定很熟悉这个 url 的格式,就相当于是在调用 http://data.stats.gov.cn/tablequery.htm 接口,然后参数为 m=QueryData code=AD03 wds=[{'wdcode':'reg','valuecode':'000000'}] 这三个,组合成的 url 然后使用 get 方法获得数据
所以我们可以直接使用调用接口的方式去获得数据,该段代码如下
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Host': 'data.stats.gov.cn',
'X-Requested-With': 'XMLHttpRequest'
}
api_url = 'http://data.stats.gov.cn/tablequery.htm'
params = {
'm': 'QueryData',
'code': 'AD03',
'wds': '[{"wdcode":"reg","valuecode":"000000"}]'
}
# 注意,wds这个键对应的值并不是一个字典或者列表,网页接口传的参数始终都是会组成字符串格式
html = requests.get(url, headers=headers, params=params)
data = json.loads(html.text)